Hadoop MapReduce作业执行流程
整个 Hadoop MapReduce 的作业执行流程如图 1 所示,共分为 10 步。
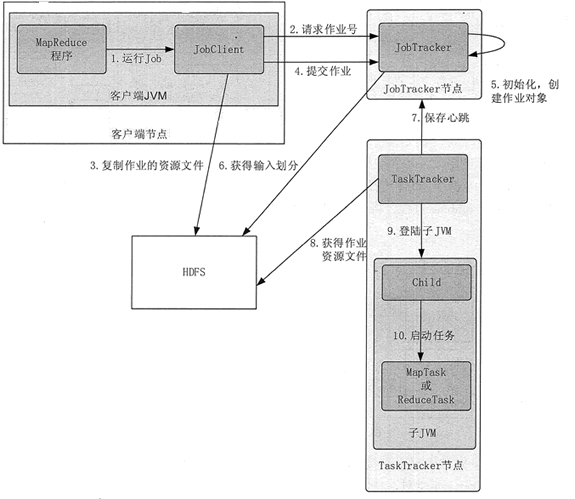
图 1 Hadoop MapReduce的作业执行流程
1)客户端通过 Runjob() 方法启动作业提交过程。
2)客户端通过 JobTracker 的 getNewJobId() 请求一个新的作业 ID。
3)客户端检查作业的输出说明,计算作业的输入分片等,如果有问题,就抛出异常,如果正常,就将运行作业所需的资源(如作业 Jar 文件,配置文件,计算所得的输入分片等)复制到一个以作业 ID 命名的目录中。
4)通过调用 JobTracker 的 submitjob() 方法告知作业准备执行。
1)JobTracker 接收到对其 submitJob() 方法的调用后,就会把这个调用放入一个内部队列中,交由作业调度器进行调度。初始化主要是创建一个表示正在运行作业的对象,以便跟踪任务的状态和进程。
2)为了创建任务运行列表,作业调度器首先从 HDFS 中获取 JobClient 已计算好的输入分片信息,然后为每个分片创建一个 MapTask,并且创建 ReduceTask。
TaskTracker 定期通过“心跳”与 JobTracker 进行通信,主要是告知 JobTracker 自身是否还存活,以及是否已经准备好运行新的任务等。
JobTracker 接收到心跳信息后,如果有待分配的任务,就会为 TaskTracker 分配一个任务,并将分配信息封装在心跳通信的返回值中返回给 TaskTracker。
对于 Map 任务,JobTracker 通常会选取一个距离其输入分片最近的 TaskTracker,对于 Reduce 任务,JobTracker 则无法考虑数据的本地化。
2)TaskTracker 启动一个新的 JVM 来运行每个任务(包括 Map 任务和 Reduce 任务),这样,JobClient 的 MapReduce 就不会影响 TaskTracker 守护进程。任务的子进程每隔几秒便告知父进程它的进度,直到任务完成。
这些消息通过一定的时间间隔由 ChildJVM 向 TaskTracker 汇聚,然后再向 JobTracker 汇聚。JobTracker 将产生一个表明所有运行作业及其任务状态的全局视图,用户可以通过 Web UI 进行查看。JobClient 通过每秒查询 JobTracker 来获得最新状态,并且输出到控制台上。
图 1 Hadoop MapReduce的作业执行流程
1. 提交作业
客户端向 JobTracker 提交作业。首先,用户需要将所有应该配置的参数根据需求配置好。作业提交之后,就会进入自动化执行。在这个过程中,用户只能监控程序的执行情况和强制中断作业,但是不能对作业的执行过程进行任何干预。提交作业的基本过程如下。1)客户端通过 Runjob() 方法启动作业提交过程。
2)客户端通过 JobTracker 的 getNewJobId() 请求一个新的作业 ID。
3)客户端检查作业的输出说明,计算作业的输入分片等,如果有问题,就抛出异常,如果正常,就将运行作业所需的资源(如作业 Jar 文件,配置文件,计算所得的输入分片等)复制到一个以作业 ID 命名的目录中。
4)通过调用 JobTracker 的 submitjob() 方法告知作业准备执行。
2. 初始化作业
JobTracker 在 JobTracker 端开始初始化工作,包括在其内存里建立一系列数据结构,来记录这个 Job 的运行情况。1)JobTracker 接收到对其 submitJob() 方法的调用后,就会把这个调用放入一个内部队列中,交由作业调度器进行调度。初始化主要是创建一个表示正在运行作业的对象,以便跟踪任务的状态和进程。
2)为了创建任务运行列表,作业调度器首先从 HDFS 中获取 JobClient 已计算好的输入分片信息,然后为每个分片创建一个 MapTask,并且创建 ReduceTask。
3. 分配任务
JobTracker 会向 HDFS 的 NameNode 询问有关数据在哪些文件里面,这些文件分别散落在哪些结点里面。JobTracker 需要按照“就近运行”原则分配任务。TaskTracker 定期通过“心跳”与 JobTracker 进行通信,主要是告知 JobTracker 自身是否还存活,以及是否已经准备好运行新的任务等。
JobTracker 接收到心跳信息后,如果有待分配的任务,就会为 TaskTracker 分配一个任务,并将分配信息封装在心跳通信的返回值中返回给 TaskTracker。
对于 Map 任务,JobTracker 通常会选取一个距离其输入分片最近的 TaskTracker,对于 Reduce 任务,JobTracker 则无法考虑数据的本地化。
4.执行任务
1)TaskTracker 分配到一个任务后,通过 HDFS 把作业的 Jar 文件复制到 TaskTracker 所在的文件系统,同时,TaskTracker 将应用程序所需要的全部文件从分布式缓存复制到本地磁盘。TaskTracker 为任务新建一个本地工作目录,并把 Jar 文件中的内容解压到这个文件夹中。2)TaskTracker 启动一个新的 JVM 来运行每个任务(包括 Map 任务和 Reduce 任务),这样,JobClient 的 MapReduce 就不会影响 TaskTracker 守护进程。任务的子进程每隔几秒便告知父进程它的进度,直到任务完成。
5. 进程和状态的更新
一个作业和它的每个任务都有一个状态信息,包括作业或任务的运行状态,Map 任务和 Reduce 任务的进度,计数器值,状态消息或描述。任务在运行时,对其进度保持追踪。这些消息通过一定的时间间隔由 ChildJVM 向 TaskTracker 汇聚,然后再向 JobTracker 汇聚。JobTracker 将产生一个表明所有运行作业及其任务状态的全局视图,用户可以通过 Web UI 进行查看。JobClient 通过每秒查询 JobTracker 来获得最新状态,并且输出到控制台上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号