Hive3.1.2源码编译兼容Spark3.1.2 Hive on Spark
原文:Hive3.1.2源码编译兼容Spark3.1.2 Hive on Spark - D-Arlin - 博客园 (cnblogs.com)
在使用hive3.1.2和spark3.1.2配置hive on spark的时候,发现官方下载的hive3.1.2和spark3.1.2不兼容,hive3.1.2对应的版本是spark2.3.0,而spark3.1.2对应的hadoop版本是hadoop3.2.0。
所以,如果想要使用高版本的hive和hadoop,我们要重新编译hive,兼容spark3.1.2。
1. 环境准备
这里在Mac编译,电脑环境需要Java、Maven、idea。
注:在Windows 10中无法编译,没有.bat文件,可以选择在虚拟机中,安装一台带图形化界面的CentOS7。
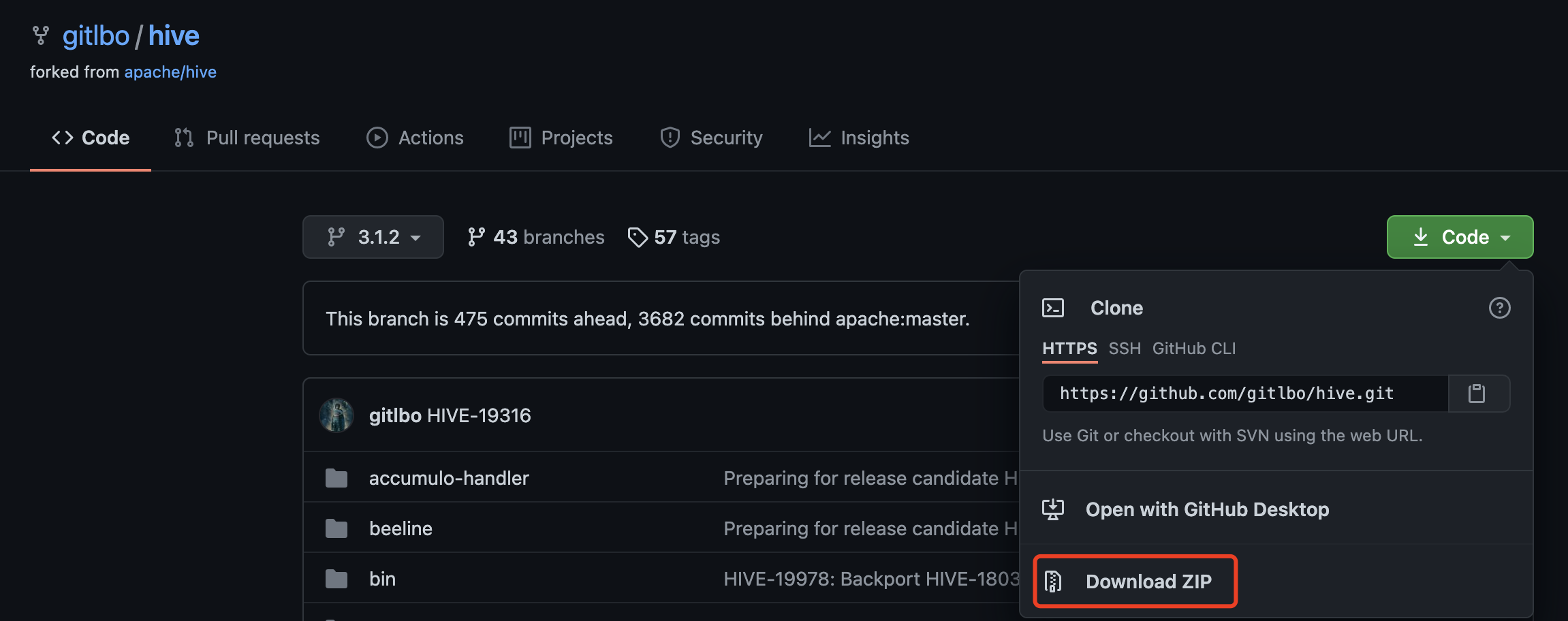
提前下载好hive3.1.2源码,并用idea打开源码。
https://github.com/gitlbo/hive/tree/3.1.2
https://www.jetbrains.com/idea/download/download-thanks.html?platform=linux
这里使用的是GitHub上的源码,因为集群中所安装的Hadoop-3.3.0中和Hive-3.1.2中都包含guava的依赖,Hadoop-3.3.0中的版本为guava-27.0-jre,而官网下载的Hive-3.1.2中的版本为guava-19.0。
由于Hive运行时会加载Hadoop依赖,故会出现依赖冲突的问题。如果直接将官网下载的源码包中pom.xml文件中的guava版本修改为27.0-jre,编译会报错,所以这里直接选择用GitHub上的源码。
注意:下载完依赖后,pom文件会报很多处错误,这个不能决定是否是错误。需要使用官方提供的编译打包方式去检验才行。
2. 打包测试
执行编译命令
打开terminal终端,使用如下命令进行进行打包,检验编译环境是否正常
mvn clean package -Pdist -DskipTests -Dmaven.javadoc.skip=true
3. 可能会遇到的问题
如果没有遇到,就直接跳过。
maven打包报错
[ERROR] Failed to execute goal on project hive-upgrade-acid: Could not resolve dependencies for project org.apache.hive:hive-upgrade-acid:jar:3.1.2: Failure to find org.pentaho:pentaho-aggdesigner-algorithm:jar:5.1.5-jhyde in http://maven.aliyun.com/nexus/content/groups/public/ was cached in the local repository, resolution will not be reattempted until the update interval of alimaven has elapsed or updates are forced -> [Help 1]
3.1 解决jar缺失
pentaho-aggdesigner-algorithm-5.1.5-jhyde.jar缺失
方法一
在maven的setting文件中添加,增加2个阿里云仓库地址
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>spring-plugin</name>
<url>https://maven.aliyun.com/repository/spring-plugin</url>
</mirror>
<mirror>
<id>repo2</id>
<name>Mirror from Maven Repo2</name>
<url>https://repo.spring.io/plugins-release/</url>
<mirrorOf>central</mirrorOf>
</mirror>
重新执行打包命令
方法二
手动下载jar包,并上传到目标目录
jar包下载地址
重新执行打包命令
这两种方法多试几次,一般就能解决了。
3.2 error in opening zip file
若出现读取XXXXX..jar时出错; error in opening zip file,找到对应目录,删除jar包,重新下载就好了。
3.3 After correcting the problems, you can resume the build with the command
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-javadoc-plugin:2.4:javadoc (resourcesdoc.xml) on project hive-webhcat: An error has occurred in JavaDocs report generation:Unable to find javadoc command: The environment variable JAVA_HOME is not correctly set. -> [Help 1] [ERROR] [ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch. [ERROR] Re-run Maven using the -X switch to enable full debug logging. [ERROR] [ERROR] For more information about the errors and possible solutions, please read the following articles: [ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoExecutionException [ERROR] [ERROR] After correcting the problems, you can resume the build with the command [ERROR] mvn <args> -rf :hive-webhcat
没有配置JAVA_HOME导致的,配置之后还是不行,记得重启一下idea。
也有可能是之前使用的是USE JAVA_HOME,修改成项目的就可以成功build project了。
编译成功提示:
[INFO] ------------------------------------------------------------------------ [INFO] Reactor Summary for Hive 3.1.2: [INFO] [INFO] Hive Upgrade Acid .................................. SUCCESS [ 5.537 s] [INFO] Hive ............................................... SUCCESS [ 0.232 s] [INFO] Hive Classifications ............................... SUCCESS [ 0.393 s] [INFO] Hive Shims Common .................................. SUCCESS [ 1.809 s] [INFO] Hive Shims 0.23 .................................... SUCCESS [ 2.859 s] [INFO] Hive Shims Scheduler ............................... SUCCESS [ 1.573 s] [INFO] Hive Shims ......................................... SUCCESS [ 1.018 s] [INFO] Hive Common ........................................ SUCCESS [ 7.054 s] [INFO] Hive Service RPC ................................... SUCCESS [ 2.797 s] [INFO] Hive Serde ......................................... SUCCESS [ 4.794 s] [INFO] Hive Standalone Metastore .......................... SUCCESS [ 27.884 s] [INFO] Hive Metastore ..................................... SUCCESS [ 2.779 s] [INFO] Hive Vector-Code-Gen Utilities ..................... SUCCESS [ 0.237 s] [INFO] Hive Llap Common ................................... SUCCESS [ 3.263 s] [INFO] Hive Llap Client ................................... SUCCESS [ 2.194 s] [INFO] Hive Llap Tez ...................................... SUCCESS [ 2.383 s] [INFO] Hive Spark Remote Client ........................... SUCCESS [ 2.915 s] [INFO] Hive Query Language ................................ SUCCESS [ 52.792 s] [INFO] Hive Llap Server ................................... SUCCESS [ 5.707 s] [INFO] Hive Service ....................................... SUCCESS [ 5.299 s] [INFO] Hive Accumulo Handler .............................. SUCCESS [ 3.621 s] [INFO] Hive JDBC .......................................... SUCCESS [ 18.186 s] [INFO] Hive Beeline ....................................... SUCCESS [ 3.277 s] [INFO] Hive CLI ........................................... SUCCESS [ 2.593 s] [INFO] Hive Contrib ....................................... SUCCESS [ 2.074 s] [INFO] Hive Druid Handler ................................. SUCCESS [ 13.076 s] [INFO] Hive HBase Handler ................................. SUCCESS [ 4.767 s] [INFO] Hive JDBC Handler .................................. SUCCESS [ 2.537 s] [INFO] Hive HCatalog ...................................... SUCCESS [ 0.439 s] [INFO] Hive HCatalog Core ................................. SUCCESS [ 4.441 s] [INFO] Hive HCatalog Pig Adapter .......................... SUCCESS [ 2.914 s] [INFO] Hive HCatalog Server Extensions .................... SUCCESS [ 2.732 s] [INFO] Hive HCatalog Webhcat Java Client .................. SUCCESS [ 2.935 s] [INFO] Hive HCatalog Webhcat .............................. SUCCESS [ 5.959 s] [INFO] Hive HCatalog Streaming ............................ SUCCESS [ 3.133 s] [INFO] Hive HPL/SQL ....................................... SUCCESS [ 4.280 s] [INFO] Hive Streaming ..................................... SUCCESS [ 2.540 s] [INFO] Hive Llap External Client .......................... SUCCESS [ 2.564 s] [INFO] Hive Shims Aggregator .............................. SUCCESS [ 0.051 s] [INFO] Hive Kryo Registrator .............................. SUCCESS [ 2.208 s] [INFO] Hive TestUtils ..................................... SUCCESS [ 0.156 s] [INFO] Hive Packaging ..................................... SUCCESS [ 55.564 s] [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 04:33 min [INFO] Finished at: 2021-06-12T23:32:27+08:00 [INFO] ------------------------------------------------------------------------
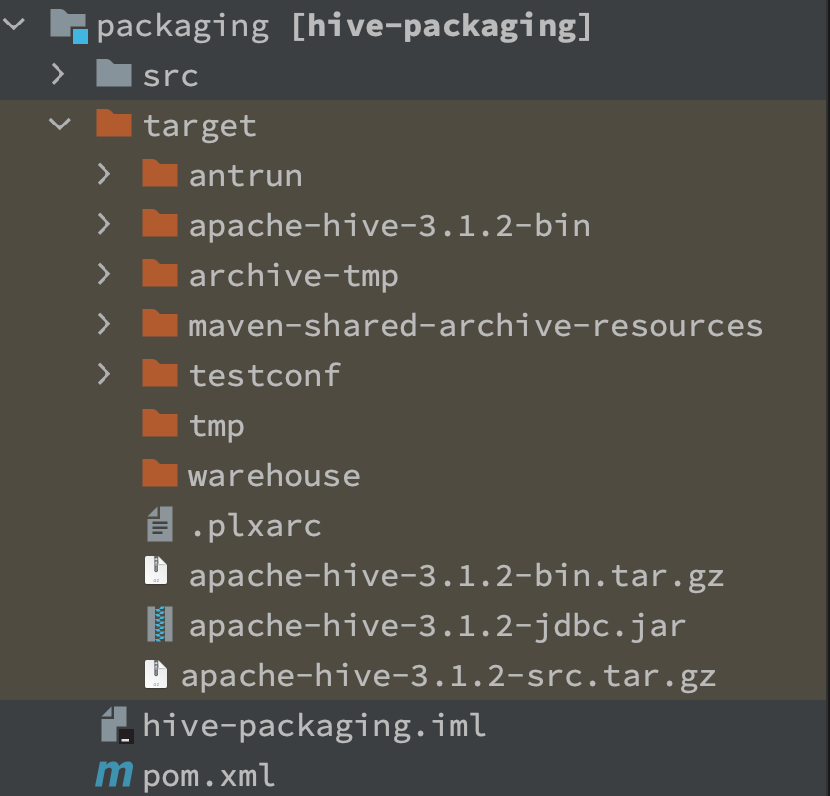
编译成功后,可以在**/packaging/target目录下查看编译完成的安装包。
4. 整合Spark3.1.2
4.1 修改pom.xml文件
将pom.xml201行的
<spark.version>3.0.0</spark.version>
改为
<spark.version>3.1.2</spark.version>
4.2 重新编译
mvn clean package -Pdist -DskipTests -Dmaven.javadoc.skip=true
基本等上几分钟,就能编译完成。
若使用官网提供的3.1.2版本编译,这里会报错,需要修改源码,GitHub上的源码,是已经修改过的。
5. 测试Hive on Spark
5.1 启动环境
启动zookeeper,hadoop集群,hive,启动hive客户端
5.2 插入测试数据
创建一张测试表
hive (default)> create external table student(id int, name string) location '/student';
插入一条测试数据
hive (default)> insert into table student values(1,'abc');
执行结果
Query ID = bigdata_20210613144232_7bafd4ac-0552-4d67-b53c-dc04b2a6f45c
Total jobs = 1
Launching Job 1 out of 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Running with YARN Application = application_1623236770182_0016
Kill Command = /opt/module/hadoop-3.3.0/bin/yarn application -kill application_1623236770182_0016
Hive on Spark Session Web UI URL: http://node00001:39673
Query Hive on Spark job[0] stages: [0, 1]
Spark job[0] status = RUNNING
--------------------------------------------------------------------------------------
STAGES ATTEMPT STATUS TOTAL COMPLETED RUNNING PENDING FAILED
--------------------------------------------------------------------------------------
Stage-0 ........ 0 FINISHED 1 1 0 0 0
Stage-1 ........ 0 FINISHED 1 1 0 0 0
--------------------------------------------------------------------------------------
STAGES: 02/02 [==========================>>] 100% ELAPSED TIME: 5.05 s
--------------------------------------------------------------------------------------
Spark job[0] finished successfully in 5.05 second(s)
Loading data to table default.student
OK
Time taken: 21.836 seconds

 浙公网安备 33010602011771号
浙公网安备 33010602011771号