
C++中的多线程
1、进程与线程
传统的C++中并没有线程的概念,直到C++11才引入了多线程与并发技术
1.1、进程
一个应用程序被操作系统加载到内存之后,从开始执行到执行结束的这样一个过程。进程通常由程序、数据和进程控制(PCB)组成,比如双击打开一个软件就是开启一个进程。
1.2、线程
线程是进程中的一个实体,是被系统独立分配和调度的基本单位,线程是CPU可执行调度的最小单位。引入线程后,进程的两个基本属性被分开了:线程作为调度和分配的基本单位(CPU调度);进程作为独立分配资源的单位(内存分配)。线程基本上不 拥有资源,可与同属于一个进程的其他线程共享进程所拥有的全部资源(涉及到同步互斥问题)。
1.3、进程与线程的区别
线程分为用户线程和内核线程,用户线程不依赖于内核,不依赖于系统调用,内核线程依赖于内核和系统调用。进程不论是用户进程还是内核进程都依赖于内核。进程要独立占用的系统资源(内存),而同一进程的线程是共享资源的,进程本身并不能获取CPU时间,只有他的线程才可以。进程在创建、撤销和切换过程中,系统的时空开销非常大,可以通过创建线程完成同样的任务,以减少并发执行时付出的时空开销。
2、并发
同一时间里CPU同时执行多条命令。
2.1、伪并发
不同线程占用不同的时间片,CPU在各个线程之间来回快速切换。这样的多线程不一定要比单线程快,比如当多个程序员同时编写一个项目,不可避免要互相交流,如果互相交流的时间远大于编码时间,效率更低。伪并发的大致模型如下:

整个框代表一个CPU的运行,T1和T2代表两个不同的线程,在执行期间,不同的线程分别占用不同的时间片,然后由操作系统负责调度执行不同的线程。但是很明显,由于内存、寄存器等等都是有限的,所以在执行下一个线程的时候不得不把上一个线程的一些数据先保存起来,这样下一次执行该线程的时候才能继续正确的执行。
2.2、理想并发
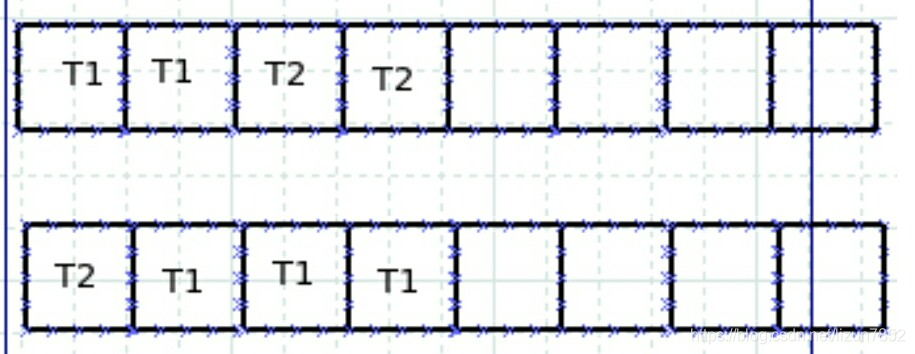
可以看出,这是真正的并发,真正实现了时间效率上的提高。因为每一个框代表一个CPU的运行,所以真正实现并发的物理基础的多核CPU。
2.3、并发的物理基础
慢慢的,发展出了多核CPU,这样就为实现真并发提供了物理基础。但这仅仅是硬件层面提供了并发的机会,还需要得到语言的支持。像C++11之前缺乏对于多线程的支持,所写的并发程序也仅仅是伪并发。也就是说,并发的实现必须首先得到硬件层面的支持,不过现在的计算机已经是多核CPU了,我们对于并发的研究更多的是语言层面和软件层面了。
3、C++实现并发
C++中采用多线程实现并发,通过thred库实现。使用C++中的单线程和多线程对数列求和:
单线程:
#include <iostream> #include <vector> #include <algorithm> using namespace std; int GetSum(vector<int>::iterator first,vector<int>::iterator last) { return accumulate(first,last,0);//调用C++标准库算法 } int main() { vector<int> largeArrays; for(int i=0;i<100000000;i++) { if(i%2==0) largeArrays.push_back(i); else largeArrays.push_back(-1*i); } int res = GetSum(largeArrays.begin(),largeArrays.end()); return 0; }
多线程:
#include <iostream> #include <vector> #include <algorithm> #include <thread> using namespace std; //线程要做的事情就写在这个线程函数中 void GetSumT(vector<int>::iterator first,vector<int>::iterator last,int &result) { result = accumulate(first,last,0); //调用C++标准库算法 } int main() //主线程 { int result1,result2,result3,result4,result5; vector<int> largeArrays; for(int i=0;i<100000000;i++) { if(i%2==0) largeArrays.push_back(i); else largeArrays.push_back(-1*i); } thread first(GetSumT,largeArrays.begin(), largeArrays.begin()+20000000,std::ref(result1)); //子线程1 thread second(GetSumT,largeArrays.begin()+20000000, largeArrays.begin()+40000000,std::ref(result2)); //子线程2 thread third(GetSumT,largeArrays.begin()+40000000, largeArrays.begin()+60000000,std::ref(result3)); //子线程3 thread fouth(GetSumT,largeArrays.begin()+60000000, largeArrays.begin()+80000000,std::ref(result4)); //子线程4 thread fifth(GetSumT,largeArrays.begin()+80000000, largeArrays.end(),std::ref(result5)); //子线程5 first.join(); //主线程要等待子线程执行完毕 second.join(); third.join(); fouth.join(); fifth.join(); int resultSum = result1+result2+result3+result4+result5; //汇总各个子线程的结果 return 0; }
C++11中引入了多线程技术,通过thread线程类对象来管理线程,只需要#include <thread>即可。thread类对象的创建意味着一个线程的开始。thread first(线程函数名,参数1,参数2,......);每个线程有一个线程函数,线程要做的事情就写在线程函数中。根据操作系统上的知识,一个进程至少要有一个线程,在C++中可以认为main函数就是这个至少的线程,我们称之为主线程。而在创建thread对象的时候,就是在这个线程之外创建了一个独立的子线程。这里的独立是真正的独立,只要创建了这个子线程并且开始运行了,主线程就完全和它没有关系了,不知道CPU会什么时候调度它运行,什么时候结束运行,一切都是独立,自由而未知的。
4、同步互斥
临界资源:对于同一进程的多个线程,进程资源中有些对线程是共享的,但有些资源一次只能供一个线程使用,这样的资源被称为临界资源,也可以叫做互斥资源,即只能被各个线程互斥访问。
临界区:线程中对临界资源实施操作的那段程序,称之为临界区。
4.1、线程之间的同步
线程的同步是指在一些确定点上需要线程之间相互合作,协同工作。在访问同一个临界资源(互斥资源)时,两个线程间必须有一个先后顺序,因为临界资源一次只能供一个线程使用,如果两个线程都想要访问,这会形成死锁。假如程序中有一个静态变量,static int a;线程1负责往里写入数据,线程2需要读取其中的数据,那么线程2在读数据之前必须是线程1写入了数据,如果不是,那么线程2必须停下来等待线程1的操作结束。
4.2、线程之间的互斥
线程的互斥是指同一进程中的多个线程之间因争用临界资源而互斥的执行,即一次只能有一个线程访问临界资源。 假如程序中有一个静态变量,static int b;线程1想要往里写入数据,线程2也想要往里写入数据,那么此时静态变量b就是一个临界资源(互斥资源),即一次只能被一个线程访问。
4.3、C++中解决同步互斥方法
C++11中实现多线程间同步与互斥有两种方法:信号量机制和锁机制,其中锁机制最为常用。
本文为一篇学习笔记
原文链接:https://blog.csdn.net/lizun7852/article/details/88783440
