
关于TVM
1、不同的框架与硬件
对于深度学习任务,有很多的深度学习框架可以选择,Google的Tensor Flow和Facebook的Pytorch,Amazon的Mxnet等。不管是使用哪一个框架进行模型训练,最终都需要将训练好的模型部署到实际应用场景中。在模型部署的时候我们会发现我们要部署的设备可能是五花八门的,如果我们要手写一个用于推理的框架在所有可能部署的设备上都达到良好的性能并且易于使用是一件非常困难的事。如果要把模型部署在指定设备上,一般会采用硬件厂商自己开发的前向推理框架,下面列出了不同的设备对应的前向推理框架:
- Intel CPU/Intel GPU/ -----------------> OpenVINO
- Nvidia GPU/ -----------------> TensorRT
- Arm CPU/Arm GPU/ -----------------> NCNN/MNN
- FPGA/
- NPU(华为海思)/
- BPU(地平线)/
- MLU(寒武纪)/
虽然针对不同的硬件设备我们使用特定的推理框架进行部署是最优的,但这也同时存在问题,比如一个开发者训练了一个模型需要在多个不同类型的设备上进行部署,那么开发者需要将训练的模型分别转换到特定框架可以读取的格式。
2、编译器
实际上在编译器发展的早期也和要将各种深度学习训练框架的模型部署到各种硬件面临的情况一下,历史上出现了非常多的编程语言,比如C/C++/Java等等,然后每一种硬件对应了一门特定的编程语言,再通过特定的编译器去进行编译产生机器码,可以想象随着硬件和语言的增多,编译器的维护难度是多么困难。
为了解决上面的问题,科学家为编译器抽象出了编译器前端,编译器中端,编译器后端等概念,并引入IR (Intermediate Representation)的概率。解释如下:
- 编译器前端:接收C/C++/Java等不同语言,进行代码生成,吐出IR
- 编译器中端:接收IR,进行不同编译器后端可以共享的优化,如常量替换,死代码消除,循环优化等,吐出优化后的IR
- 编译器后端:接收优化后的IR,进行不同硬件的平台相关优化与硬件指令生成,吐出目标文
以LLVM编译器为例子:

3、深度学习编译器
受到编译器解决方法的启发,深度学习编译器被提出,我们可以将各个训练框架训练出来的模型看作各种编程语言,然后将这些模型传入深度学习编译器之后吐出IR,由于深度学习的IR其实就是计算图,所以可以直接叫作Graph IR。针对这些Graph IR可以做一些计算图优化再吐出IR分发给各种硬件使用。这样,深度学习编译器的过程就和传统的编译器类似,可以解决上面提到的很多繁琐的问题。
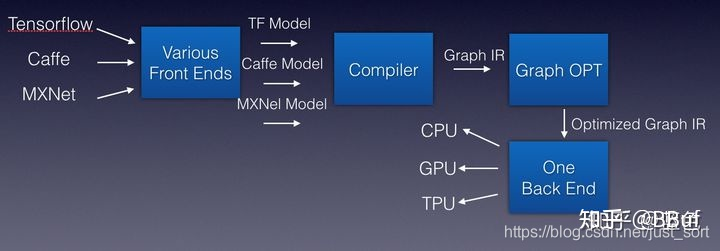
4、TVM
基于上面深度学习编译器的思想,陈天奇领衔的TVM横空出世。TVM就是一个基于编译优化的深度学习推理框架,TVM的架构图:
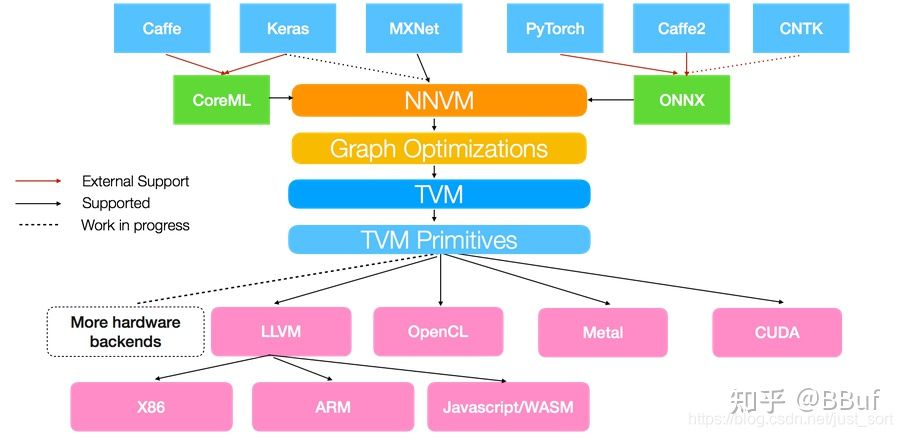
从这个图中我们可以看到,TVM架构的核心部分就是NNVM编译器(注意一下最新的TVM已经将NNVM升级为了Realy,所以后面提到的Relay也可以看作是NNVM)。NNVM编译器支持直接接收深度学习框架的模型,如TensorFlow/Pytorch/Caffe/MxNet等,同时也支持一些模型的中间格式如ONNX、CoreML。这些模型被NNVM直接编译成Graph IR,然后这些Graph IR被再次优化,吐出优化后的Graph IR,最后对于不同的后端这些Graph IR都会被编译为特定后端可以识别的机器码完成模型推理。比如对于CPU,NNVM就吐出LLVM可以识别的IR,再通过LLVM编译器编译为机器码到CPU上执行。
