java 使用POI导出百万级数据
先看结果吧,这只是测试其中有很多因数影响了性能。
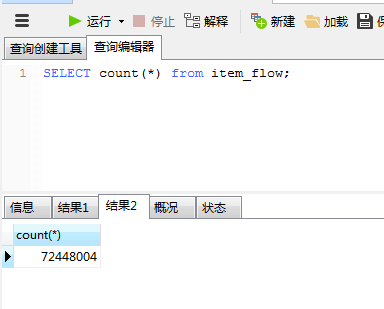
表总数为:7千多万,测试导出100万
表字段有17个字段
最终excel大小有60多兆


总耗时:126165毫秒 差不多2分多钟

其核心简单来说就是分批写入,就是分页一样。这样的好处就是不会内存溢出。
(真的不会写博客。。。)
直接上代码了
public void download(HttpServletResponse response) throws Exception{ // 一次读取的数量 int listCount = 200000; // 求数据库中导出数据的总行数 Integer totalCount = analysisMapper.totalNum(); // 根据行数求数据获取次数 int pageSize = totalCount % listCount > 0 ? (totalCount / listCount) + 1 : totalCount / listCount; //创建poi导出数据对象 SXSSFWorkbook sxssfWorkbook = new SXSSFWorkbook(); //创建sheet页 SXSSFSheet sheet = sxssfWorkbook.createSheet(); //设置表头信息 SXSSFRow headRow = sheet.createRow(0); List<String> indexList = new ArrayList<>(); for (int pg = 0; pg < pageSize; pg++) { List<Map<String, Object>> list = analysisMapper.downloadData(pg * listCount, listCount); if(pg == 0 && list.size() > 0){ Map<String, Object> map = list.get(0); for(Map.Entry<String,Object> entry : map.entrySet()){ indexList.add(entry.getKey()); } for (int j = 0; j < indexList.size(); j++) { headRow.createCell(j).setCellValue(indexList.get(j)); } } // 遍历上面数据库查到的数据 for (int i = 0; i < list.size(); i++) { SXSSFRow dataRow = sheet.createRow(sheet.getLastRowNum() + 1); for (int j = 0; j < indexList.size(); j++) { dataRow.createCell(j).setCellValue(list.get(i).get(indexList.get(j)).toString()); } } } createFile(response, sxssfWorkbook); }
private void createFile(HttpServletResponse response,SXSSFWorkbook sxssfWorkbook) throws Exception{ // 下载导出 String filename = UUID.randomUUID().toString(); // 设置头信息 response.setCharacterEncoding("UTF-8"); response.setContentType("application/vnd.ms-excel"); //设置成xlsx格式 response.setHeader("Content-Disposition","attachment;filename="+ URLEncoder.encode(filename + ".xlsx","UTF-8")); //创建输出流 ServletOutputStream outputStream = response.getOutputStream(); //写入数据 sxssfWorkbook.write(outputStream); //关闭流 outputStream.close(); sxssfWorkbook.close(); }
若果有啥问题请指正。
(转载请注明花儿为何那样红博客)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号