02. FLASK与HTTP
如果想要开发更复杂的Flask应用,就得了解Flask与HTTP协议的交互方式。 HTTP(Hypertext Transfer Protocol,超文本传输协议)定义了服务器和 客户端之间信息交流的格式和传递方式,它是万维网(World Wide Web)中数据交换的基础。
一、请求响应循环#
假设现有http://www.baidu.com/
在浏览器中的地址栏中输入这个URL,然后按下Enter时,稍等片刻,浏览器会显示一个百度页面。
服务器负责接收用户的请求,并把对应的内容返回给客户端,显示在用户的浏览 器上。事实上,每一个Web应用都包含这种处理模式,即“请求-响应循环(Request-Response Cycle)”:客户端发出请求,服务器端处理请求并返回响应。
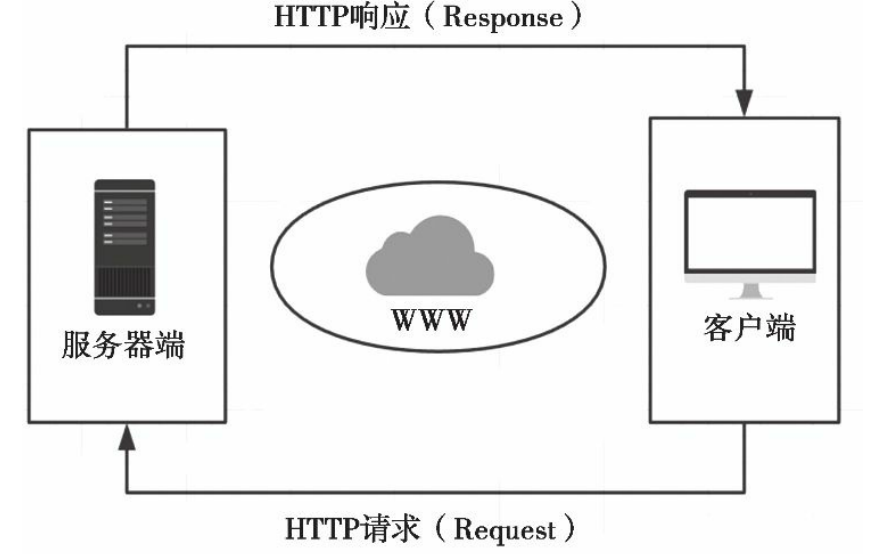
客户端(Client Side)是指用来提供给用户的与服务器通信的各种 软件。该笔记中,客户端通常指Web浏览器(后面简称浏览器),比如 Chrome、Firefox、IE等;
服务器端(Server Side)则指为用户提供服务的服务器,也是程序运行的地方。
这是每一个Web程序的基本工作模式,如果再进一步,这个模式又包含着更多的工作单元。
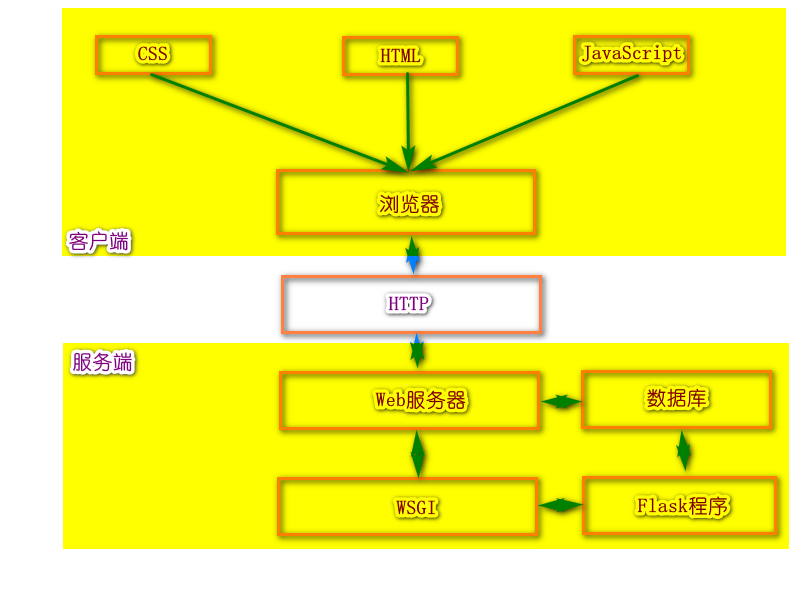
当用户访问一个URL,浏览器便生成对应的HTTP请求,经由互联网发送到对应的Web服务器。Web服务器接收请求,通过WSGI将HTTP 格式的请求数据转换成我们的Flask程序能够使用的Python数据。在程序 中,Flask根据请求的URL执行对应的视图函数,获取返回值生成响应。 响应依次经过WSGI转换生成HTTP响应,再经由Web服务器传递,最终 被发出请求的客户端接收。浏览器渲染响应中包含的HTML和CSS代 码,并执行JavaScript代码,最终把解析后的页面呈现在用户浏览器的窗 口中。
二、HTTP请求#
URL是一个请求的起源。不论服务器是运行在美国洛杉矶,还是运行在自己的电脑上,输入指向服务器所在地址的URL,都会向服务器发送一个HTTP请求。一个标准的URL由很多部分组成,以下面这个URL为例:
http://helloflask.com/hello?name=ChanceySolo
| 信息 | 说明 |
|---|---|
| http:// | 协议字符串,指定要使用的字符串 |
| helloflask.com | 服务器的地址 |
| /hello?name=ChanceySolo | 要获取的资源路径(path),类似UNIX的文件目录 |
这个URL后面的?name=ChanceySolo部分是查询字符串(query string)。 URL中的查询字符串用来向指定的资源传递参数。查询字符串从问号?开始,以键值对的形式写出,多个键值对之间使用&分隔。
1.请求报文#
在浏览器中访问这个URL时,随之产生的是一个发向http://helloflask.com所在服务器的请求。请求的实质是发送到服务器上的一些数据,这种浏览器与服务器之间交互的数据被称为报文 (message),请求时浏览器发送的数据被称为请求报文(request message),而服务器返回的数据被称为响应报文(response message)。
请求报文由请求的方法、URL、协议版本、首部字段(header)以及内容实体组成。
请求报文示意表
| 组成说明 | 请求报文内容 |
|---|---|
| 报文首部:请求行(方法、URL、协议) | GET /hello HTTP/1.1 |
| 报文首部:各种首部字段 | Host:helloflask.com Connection:keep-alive Cache-Control:max-age=0 User-Agent:Mozilla/5.0(Windows NT 6.1;Win64;x64) AppleWebKit/537.36(KHTML,like Gecko) Chrome/59.0.3071.104 Safari/537.36.. |
| 空行 | |
| 报文主体 | name=ChanceySolo |
如果想看真实的HTTP报文,可以在浏览器中向任意一个有效的URL发起请求,然后在浏览器的开发者工具(F12)里的Network标签中 看到URL对应资源加载的所有请求列表,单击任一个请求条目即可看到 报文信息,图2-3是使用Chrome访问本地示例程序的示例。
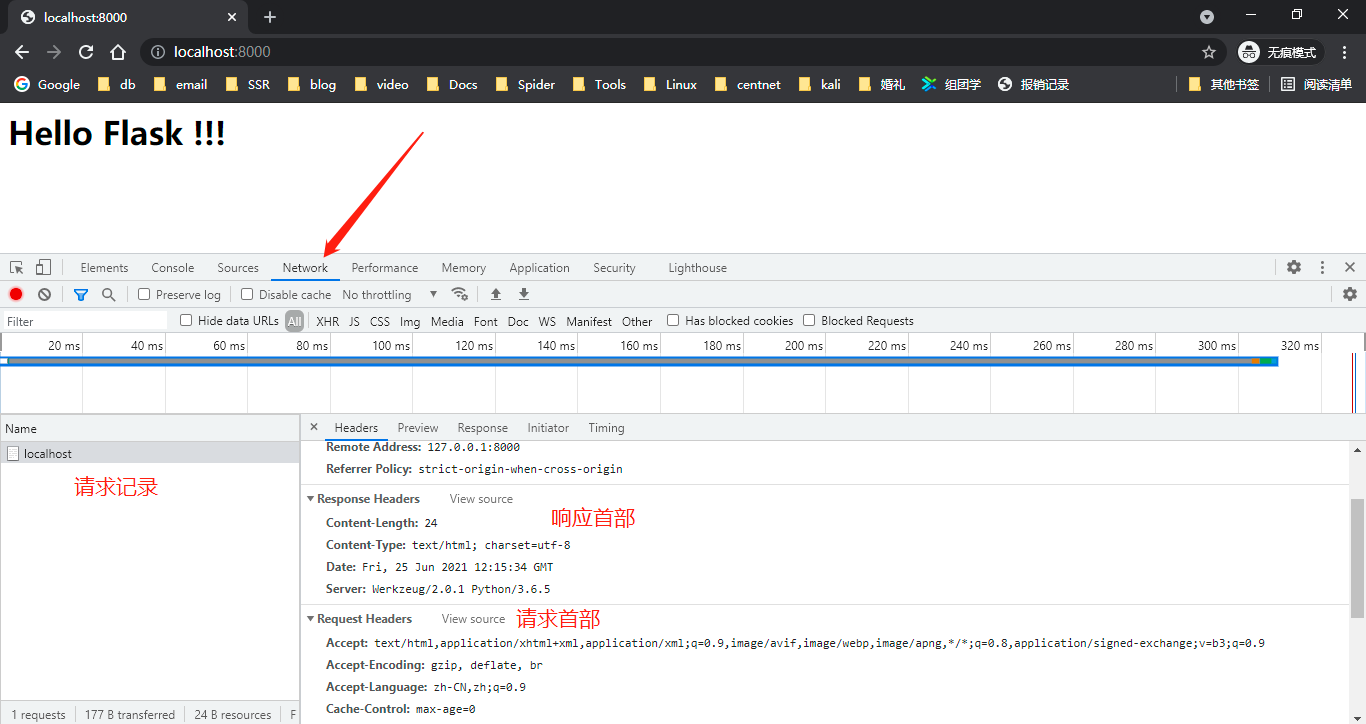
报文由报文首部和报文主体组成,两者由空行分隔,请求报文的主体一般为空。如果URL中包含查询字符串,或是提交了表单,那么报文主体将会是查询字符串和表单数据。
HTTP通过方法来区分不同的请求类型。比如,直接访问一个页面时,请求的方法是GET;在某个页面填写了表单并提交时,请求方法则通常为POST。
| 方法 | 说明 |
|---|---|
| GET | 获取资源 |
| POST | 传输数据 |
| PUT | 传输文件 |
| DELETE | 删除资源 |
| HEAD | 获得报文首部 |
| OPTIONS | 询问支持的方法 |
报文首部包含了请求的各种信息和设置,比如客户端的类型、是否设置缓存、语言偏好等。
2.Request对象#
请求对象request封装了从客户端发来的请求报文,可以从它获取请求报文中的所有数据。
请求解析和响应封装实际上大部分是由Werkzeug完成的,Flask子类化Werkzeug的请求(Request)和响应(Response)对象并添加了和程序相关的特定功能。
使用request的属性获取请求URL
| 属性 | 值 |
|---|---|
| path | u"/hello" |
| full_path | u"/hello?name=ChanceySolo" |
| host | u"helloflask.com" |
| host_url | u"http://helloflask.com/" |
| base_url | u"http://helloflask.com/hello/" |
| url | u"http://helloflask.com/hello?name=ChanceySolo/" |
| url_root | u"http://helloflask.com/" |
除了URL,请求报文中的其他信息都可以通过request对象提供的属 性和方法获取
request对象常用的属性和方法
| 属性/方法 | 说明 |
|---|---|
| args | Werkzeug的ImmutableMultiDict对象。存储解析后的查询字符串,可通过字典方式获取键值。如果想要获取未解析的原生查询字符串,可以使用query_string属性 |
| blueprint | 当前蓝本的名称 |
| cookies | 一个包含所有随请求提交上来的cookies字典 |
| data | 包含字符串形式的请求数据 |
| endpoint | 与当前请求相匹配的端点值 |
| files | Werkzeug的MultiDict对象,包含所有上传文件,可以使用字典的形式获取文件。使用的键为文件input标签中的name属性值,对应的值为Zerkzeug的FileStorage对象,可以调用save()方法并传入保存路径来保存文件 |
| form | Werkzeug的ImmutableMultiDict对象。与files类似,包含解析后的表单数据。表单字段值通过input标签的name属性值作为键获取 |
| values | Werkzeug的CommbinedMultiDict对象,结合了args和form属性的值 |
| get_data(cache=True,as_text=Flase,parse_form_data=False) | 获取请求中的数据,默认读取为字节字符串,将as_text设为True则返回值将是解码后的unicode字符串 |
| get_json(self,force=False,silent=False,cache=True) | 作为JSON解析并返回数据,如果MIME类型不是JSON,返回None(除非force设为True);解析出错则抛出Werkzeug提供的BadRequest异常(如果未开启调试模式,则返回400错误响应),如果silent设置为True则返回None;cache设置是否缓存解析后的JSON数据 |
| headers | 一个Werkzeug的EnvironHeaders对象,包含首部字段,可以以字典的形式操作 |
| is_json | 通过MIME类型判断是否为json数据,返回布尔值 |
| json | 包含解析后的json数据,内部调用get_json(),可通过字典的方式获取键值 |
| method | 请求的HTTP方法 |
| referrer | 请求发起的源URL |
| scheme | 请求URL的模式(HTTP或者HTTPS) |
| user-agent | 用户代理(User-Agent,UA),包含了用户的客户端类型,操作系统类型等信息 |
Werkzeug的MutliDict类是字典的子类,它主要实现了同一个键对应 多个值的情况。比如一个文件上传字段可能会接收多个文件。这时就可 以通过
getlist()方法来获取文件对象列表。而ImmutableMultiDict类继承了MutliDict类,但其值不可更改。
示例程序中实现了同样的功能。访问http://localhost:5000/hello?name=ChanceySolo时,页面加载后会显示“Hello, ChanceySolo!”。这说明处理这个URL的视图函数从查询字符串中获取了查询参数name的值,
from flask import Flask, request
app = Flask(__name__)
@app.route("/hello")
def hello():
name = request.args.get("name", "Flask") # 获取查询参数name的值
return "<h1>Hello %s !</h1>" % name # 插入到返回值中

上面的示例代码包含安全漏洞,在现实中要避免直接将用户传入的数据作为响应返回。
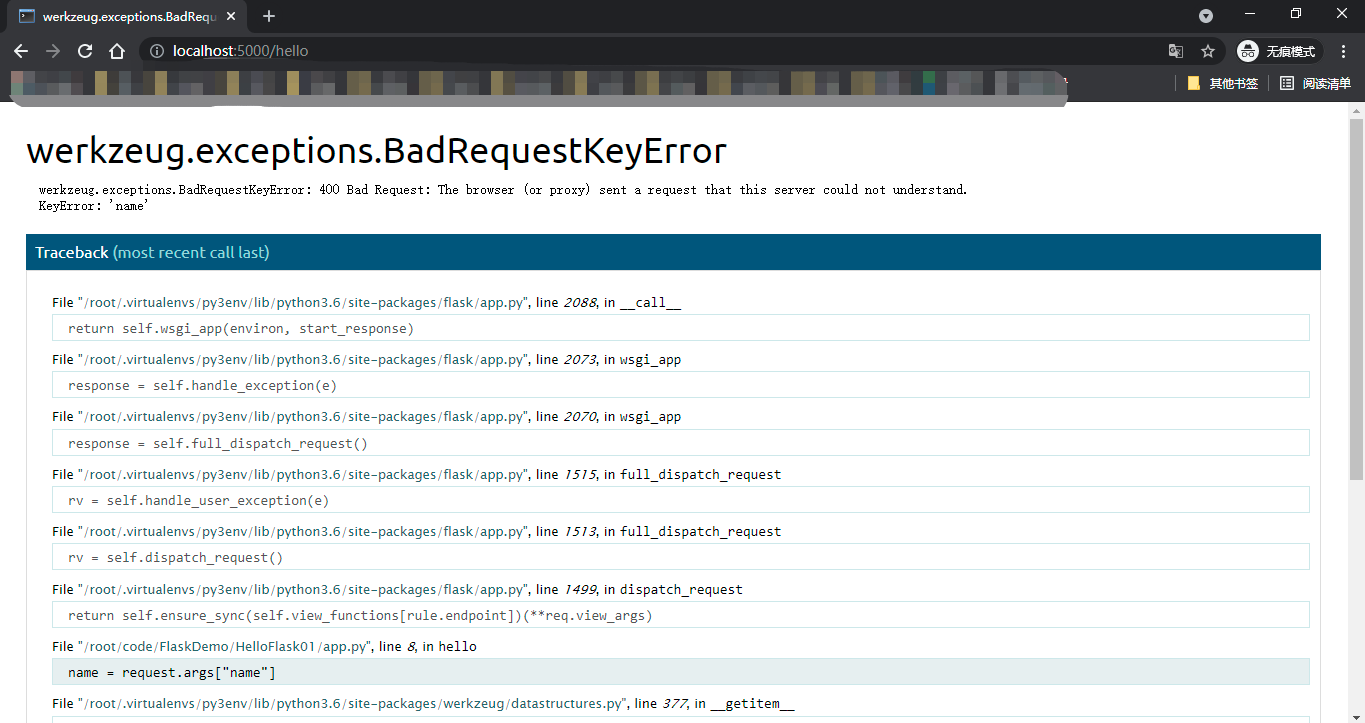
需要注意的是,和普通的字典类型不同,从request对象的类型为MutliDict或ImmutableMultiDict的属性(比如files、form、args)中直接使用键作为索引获取数据时(比如request.args['name']),如果没有对应的键,那么会返回HTTP 400错误响应(Bad Request,表示请求无效),而不是抛出KeyError异常,为了避免这个错误,应该使用get()方法获取数据,如果没有对应的值则返回None; get()方法的第二个参数可以设置默认值,比如 requset.args.get('name','Flask')
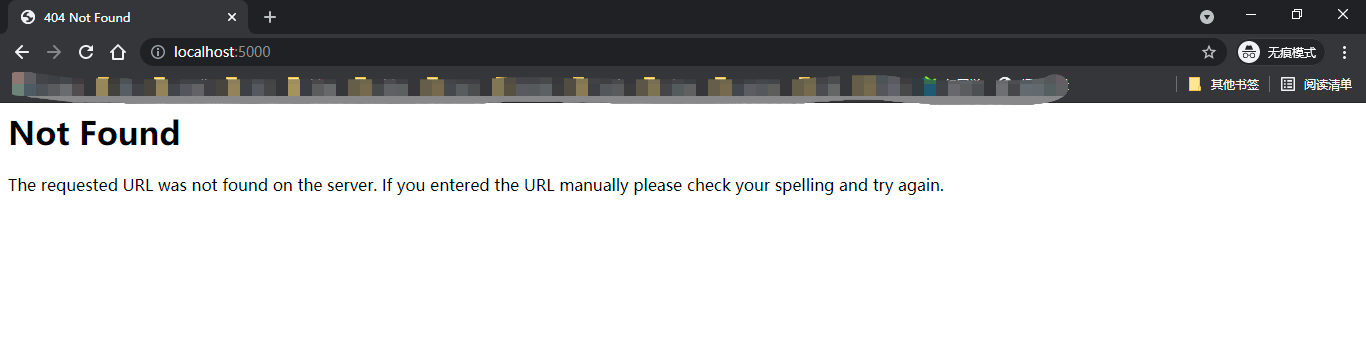
如果开启了调试模式,那么会抛出BadRequestKeyError异常并显示对应的错误堆栈信息,而不是常规的400响应。
3.Flask中处理请求#
URL是指向网络上资源的地址。在Flask中,需要让请求的URL匹配对应的视图函数,视图函数返回值就是URL对应的资源。
①路由匹配#
为了便于将请求分发到对应的视图函数,程序实例中存储了一个路由表app.url_map,其中定义了URL规则和视图函数的映射关系。当请求发来后,Flask会根据请求报文中的URL(path部分)来尝试与这个表中的所有URL规则进行匹配,调用匹配成功的视图函数。如果没有找到匹配的URL规则,说明程序中没有处理这个URL的视图函数,Flask会自动返回404错误响应(Not Found,表示资源未找到)。尝试在浏览器中访问http://localhost:5000/nothing,因为程序中没有视图函数负责处理这个URL,所以会得到404响应,
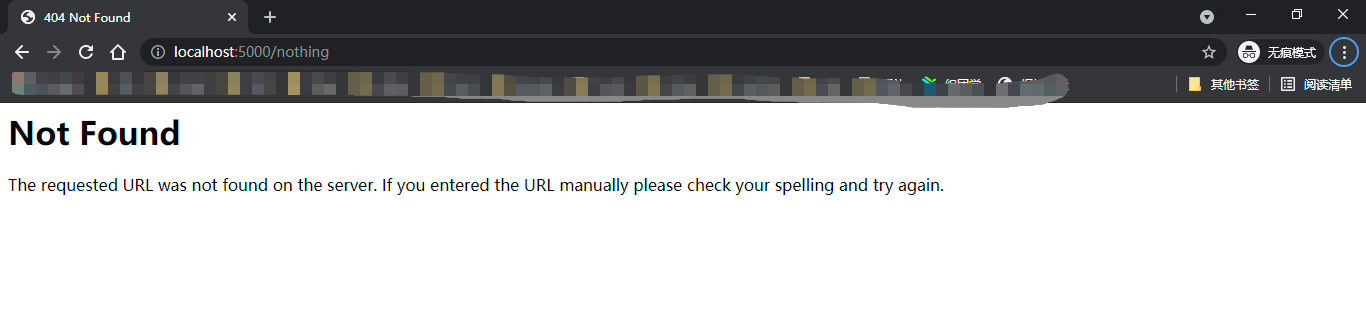
它表示请求的资源没有找到。和前面提及的400错误响应一样,这类错误代码被称为HTTP状态码,用来表示响应的状态。 当请求的URL与某个视图函数的URL规则匹配成功时,对应的视图函数就会被调用。使用flask routes命令可以查看程序中定义的所有路由,这个列表由app.url_map解析得到

在输出的文本中,可以看到每个路由对应的端点 (Endpoint)、HTTP方法(Methods)和URL规则(Rule),其中static 端点是Flask添加的特殊路由,用来访问静态文件。
②设置监听HTTP方法#
上边通过flask routes命令打印出的路由列表可以看到,每一个路由除了包含URL规则外,还设置了监听的HTTP方法。GET是最常用的HTTP方法,所以视图函数默认监听的方法类型就是GET,HEAD、 OPTIONS方法的请求由Flask处理,而像DELETE、PUT等方法一般不会在程序中实现,在后面构建Web API时才会用到这些方法。 在app.route()装饰器中使用methods参数传入一个包含监听的HTTP方法的可迭代对象。比如,下面的视图函数同时监听GET请求和POST请求:
@app.route('/hello', methods=['GET', 'POST'])
def hello():
return '<h1>Hello, Flask!</h1>'

③URL处理#
从上边的路由列表中可以看到,这里只有一个路由,现在添加一个路由,用于计算年龄。
@app.route("/goback/<int:year>")
def goback(year):
nowYear = int(datetime.datetime.now().strftime("%Y"))
age = nowYear - year
return "你今年%d了" % age

URL规则中的变量部分有一些特别,表示为year变量添加了一个int转换器, Flask在解析这个URL变量时会将其转换为整型。URL中的变量部分默认类型为字符串,但Flask提供了一些转换器可以在URL规则里使用。
Flask内置的URL变量转换器
| 转换器 | 说明 |
|---|---|
| string | 不包含斜线的字符串(默认值) |
| int | 整型 |
| float | 浮点型 |
| path | 包含斜线的字符串。static路由的URL规则中的filename变量就是使用这个转换器 |
| any | 匹配一系列给定值中的一个元素 |
| uuid | UUID字符串 |
转换器通过特定的规则指定,即“<转换器:变量名>”。 把year的值转换为整数,因此可以在视图函数中直接对year变量进行数学计算。
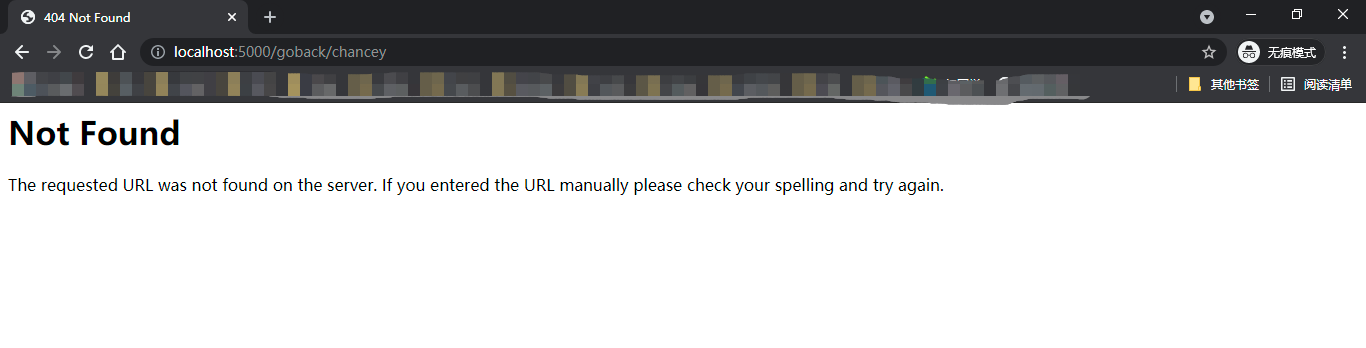
默认的行为不仅仅是转换变量类型,还包括URL匹配。在这个例子中,如果不使用转换器,默认year变量会被转换成字符串,为了能够在 Python中计算天数,需要使用int()函数将year变量转换成整型。 但是如果用户输入的是英文字母,就会出现转换错误,抛出ValueError异常;使用了转换器后,如果URL中传入的变量不是数字,那么会直接返回404错误响应。比如,尝试访问 http://localhost:5000/goback/chancey。
在用法上唯一特别的是any转换器,需要在转换器后添加括号来给出可选值,即
<any (value1, value2, ...)>,比如:@app.route("/sex/<any(man,woman)>") def sexinfo(sex): return "你是个%s" % sex
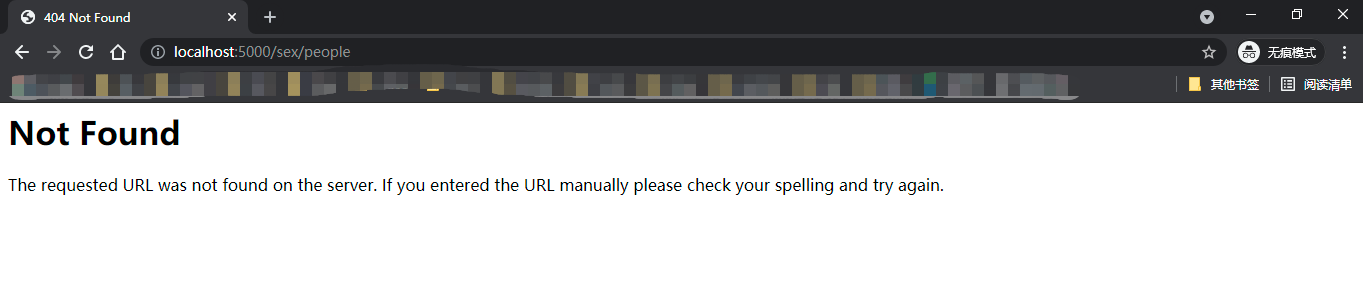
在浏览器中访问http://localhost:5000/sex/时,如果将
sex部分替换为any转换器中设置的可选值以外的任意字符,均会获得404错误响应。
如果想在any转换器中传入一个预先定义的列表,可以通过格式化字符串的方式(使用%或是
format()函数)来构建URL规则字符串,比如:sexs = ["man", "woman", "people"] @app.route("/sex/<any(%s):sexs>" % str(sexs)[1:-1] ) def sexinfomessage(sexs): return "你是个%s" % sexs


④请求钩子#
有时需要对请求进行预处理(preprocessing)和后处理 (postprocessing),这时可以使用Flask提供的一些请求钩子 (Hook),它们可以用来注册在请求处理的不同阶段执行的处理函数 (或称为回调函数,即Callback)。这些请求钩子使用装饰器实现,通过程序实例app调用,用法很简单:以before_request钩子(请求之前) 为例,对一个函数附加了app.before_request装饰器后,就会将这个函数注册为before_request处理函数,每次执行请求前都会触发所有 before_request处理函数。Flask默认实现的五种请求钩子如下所示。
请求钩子
| 钩子 | 说明 |
|---|---|
| before_first_request | 注册一个函数,在处理第一个请求前运行 |
| before_request | 注册一个函数,在处理每一个请求前运行 |
| after_request | 注册一个函数,如果没有未处理的异常抛出,会在每个请求结束后运行 |
| teardown_request | 注册一个函数,即使有未处理的异常抛出,会在每个请求结束后运行。如果发生异常,会传入异常对象作为参数到注册的函数中 |
| after_this_request | 在视图函数内注册一个函数,会在这个请求结束后运行 |
这些钩子使用起来和app.route()装饰器基本相同,每个钩子可以注册任意多个处理函数,函数名并不是必须和钩子名称相同
@app.before_request
def do_something():
pass # 这里的代码会在请求处理之前运行
假如创建了三个视图函数A、B、C,其中视图C使用了after_this_request钩子,那么当请求A进入后,整个请求处理周期的请求处理函数调用流程如图所示。
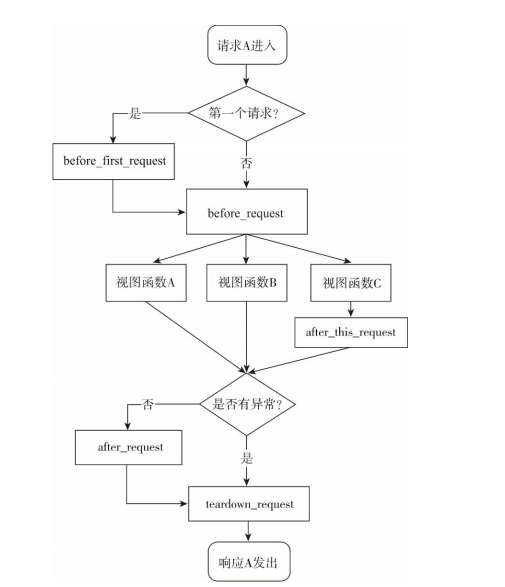
下面是请求钩子的一些常见应用场景:
·before_first_request:在完整程序中,运行程序前需要进行一些程序的初始化操作,比如创建数据库表,添加管理员用户。这些工作可以放到使用before_first_request装饰器注册的函数中。·before_request:比如网站上要记录用户最后在线的时间,可以通过用户最后发送的请求时间来实现。为了避免在每个视图函数都添加更新在线时间的代码,仅在使用before_request钩子注册的函数中调用这段代码。·after_request:经常在视图函数中进行数据库操作,比如更新、插入等,之后需要将更改提交到数据库中。提交更改的代码就可以放到after_request钩子注册的函数中。
另一种常见的应用是建立数据库连接,通常会有多个视图函数需要建立和关闭数据库连接,这些操作基本相同。一个理想的解决方法是在请求之前(before_request)建立连接,在请求之后(teardown_request) 关闭连接。通过在使用相应的请求钩子注册的函数中添加代码就可以实现。
after_request钩子和after_this_request钩子必须接收一个响应类对象作为参数,并且返回同一个或更新后的响应对象。
@app.before_first_request
def printMessage():
print("建立数据库连接")
@app.after_request
def close(sexinfomessage):
print("关闭数据库连接")
return sexinfomessage
三、HTTP响应#
在Flask程序中,客户端发出的请求触发相应的视图函数,获取返回值会作为响应的主体,最后生成完整的响应,即响应报文。
1.响应报文#
响应报文主要由协议版本、状态码(status code)、原因短语 (reason phrase)、响应首部和响应主体组成。以发向localhost: 5000/hello的请求为例,服务器生成的响应报文示意如下所示。
响应报文

响应报文的首部包含一些关于响应和服务器的信息,这些内容由 Flask生成,而在视图函数中返回的内容即为响应报文中的主体内 容。浏览器接收到响应后,会把返回的响应主体解析并显示在浏览器窗 口上。
HTTP状态码用来表示请求处理的结果,如下是常见的几种状态码和相应的原因短语。
当关闭调试模式时,即
FLASK_ENV使用默认值production,如果程序出错,Flask会自动返回500错误响应;而调试模式下则会显示调试信息和错误堆栈。
2.在flask中生成响应#
响应在Flask中使用Response对象表示,响应报文中的大部分内容由服务器处理,大多数情况下,flask只负责返回主体内容。
根据之前的内容,Flask会先判断是否可以找到与请求 URL相匹配的路由,如果没有则返回404响应。如果找到,则调用对应 的视图函数,视图函数的返回值构成了响应报文的主体内容,正确返回时状态码默认为200。Flask会调用make_response()方法将视图函数返回值转换为响应对象。
完整来讲,视图函数可以返回最多由三个元素组成的元组:响应主体、状态码、首部字段。其中首部字段可以为字典,或是两元素元组组成的列表。
比如,普通的响应可以只包含主体内容:
@app.route("/hello")
def hello():
......
return "<h1>Hello Flask!!</h1>"
默认的状态码为200,下面指定了不同的状态码:
@app.route('/hello')
def hello():
...
return '<h1>Hello, Flask!</h1>', 201
有时会想附加或修改某个首部字段。比如,要生成状态码为3XX 的重定向响应,需要将首部中的Location字段设置为重定向的目标URL:
@app.route('/hello')
def hello():
...
return '', 302, {'Location', 'http://www.example.com'}
现在访问http://localhost:5000/hello,会重定向到http://www.example.com。在多数情况下,除了响应主体,其他部分通常只需要使用默认值即可。
①重定向#
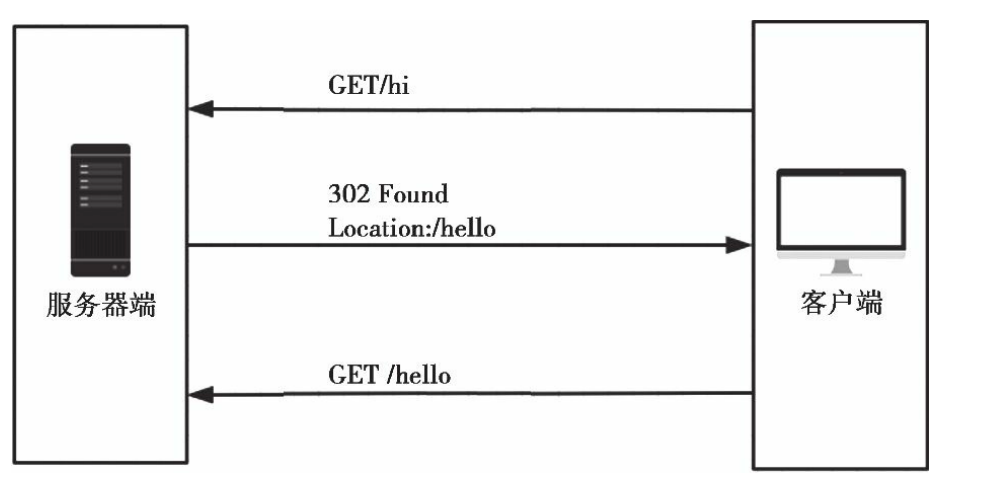
如果访问http://localhost:5000/hi,会发现页面加载后地址栏中的URL变为了http://localhost:5000/hello。这种行为被称为重定向 (Redirect),可以理解为网页跳转。上述示例中,状态码为302的重定向响应的主体为空,首部中需要将Location字段设为重定向的目标URL,浏览器接收到重定向响应后会向Location字段中的目标URL发起新的GET请求,整个流程如图所示。
重定向流程示意图
在Web程序中,经常需要进行重定向。
比如,当某个用户在没有经过认证的情况下访问需要登录后才能访问的资源,程序通常会重定向到登录页面。 对于重定向这一类特殊响应,Flask提供了一些辅助函数。除了像前 面那样手动生成302响应,还可以可以使用Flask提供的redirect()函数来生成重定向响应,重定向的目标URL作为第一个参数。前面的例子可以就简化为:
from flask import Flask, redirect
@app.route('/hello')
def hello():
return redirect('http://www.example.com')
使用redirect()函数时,默认的状态码为302,即临时重定向。如果要修改状态码,可以在redirect()函数中作为第二个参数或使用code关键字传入。
如果要在程序内重定向到其他视图,那么只需在redirect()函数中使用url_for()函数生成目标URL即可
from flask import Flask, redirect, url_for
@app.route('/hi')
def hi():
return redierct(url_for('hello')) # 重定向到/hello
@app.route('/hello')
def hello():
...
②错误响应#
现添加一个路由
# 记得在flask中导入abort方法
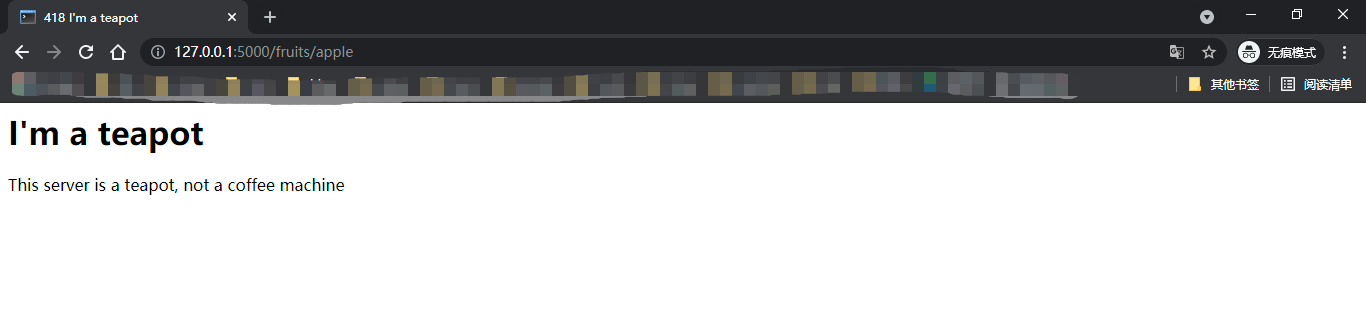
@app.route("/fruits/<fruit>")
def fruits(fruit):
if fruit == "apple":
abort(418)
else:
return "这是一个苹果"
访问http://127.0.0.1:5000/fruits/apple,这里是自定义返回的状态码为418
大多数情况下,Flask会自动处理常见的错误响应。HTTP错误对应的异常类在Werkzeug的werkzeug.exceptions模块中定义,抛出这些异常即可返回对应的错误响应。如果要手动返回错误响应,更方便的方法是使用Flask提供的abort()函数。
在abort()函数中传入状态码即可返回对应的错误响应,如下的视图函数返回404错误响应。
@app.route("/fruits/<fruit>")
def fruits(fruit):
if fruit == "apple":
abort(404)
else:
return "这是一个 %s" % fruit
abort()函数前不需要使用return语句,但一旦abort()函数被调 用,abort()函数之后的代码将不会被执行。虽然有必要返回正确的状态码,但这不是必须的。比如,当某个用户没有权限访问某个资源时,返回404错误要比403错误更加友好。
③响应格式#
在HTTP响应中,数据可以通过多种格式传输。
大多数情况下,使用HTML格式,这也是Flask中的默认设置。
在特定的情况下,也会使用其他格式。
不同的响应数据格式需要设置不同的MIME类型,MIME类型在首部的Content-Type字段中定义,以默认的HTML类型为例:
Content-Type: text/html; charset=utf-8
MIME类型(又称为media type或content type)是一种用来标识文件类型的机制,它与文件扩展名相对应,可以让客户端区分不同的内容类型,并执行不同的操作。一般的格式为“类型名/子类型名”,其中的子类型名一般为文件扩展名。比如,HTML的MIME类型为“text/html”,png 图片的MIME类型为“image/png”。完整的标准MIME类型列表可以在这里看到:https://www.iana.org/assignments/media-types/media-types.xhtml。
这里罗列常见的类型:
响应类型 MIME类型 二进制 application/gzip 音频 audio/aac 字体 font/ttf 图片 image/bmp 视频 video/mp4 文本 text/css
如果要使用其他MIME类型,可以通过Flask提供的make_response()方法生成响应对象,传入响应的主体作为参数,然后使用响应对象的mimetype属性设置MIME类型,比如:
from flask import make_response
@app.route('/foo')
def foo():
response = make_response('Hello, World!')
response.mimetype = 'text/plain'
return response
也可以直接设置首部字段,比如response.headers['Content-Type']='text/xml;charset=utf-8'。但操作mimetype属性更加方便,而且不用设置字符集(charset)选项。
常用的数据格式有纯文本、HTML、XML和JSON。为了对不同的数据类型进行对比,这里将会用不同的数据类型来表示一个便签的内容:Mary写给Chancey的一个提醒。
-
纯文本
MIME类型:text/plain
Note to: Chancey from: Mary heading: Reminder body: Don't forget the party!事实上,其他几种格式本质上都是纯文本。比如同样是一行包含 HTML标签的文本“<h1>Hello,Flask!</h1>”,当MIME类型设置为纯文本时,浏览器会以文本形式显示“<h1>Hello,Flask!</h1>”;当 MIME类型声明为text/html时,浏览器则会将其作为标题1样式的HTML代码渲染。
-
HTML
MIME类型:text/html
<!DOCTYPE html> <html> <head></head> <body> <h1>Note</h1> <p>to: Chancey</p> <p>from: Mary</p> <p>heading: Reminder</p> <p>body: <strong>Don't forget the party!</strong></p> </body> </html>HTML指Hypertext Markup Language(超文本标记语言),是最常用的数据格式,也是Flask返回响应的默认数据类型。
当数据类型为HTML时,浏览器会自动根据HTML标签以及样式类定义渲染对应的样式。 因为HTML常常包含丰富的信息,所以可以直接将HTML嵌入页面中,处理起来比较方便。因此,在普通的HTTP请求中使用HTTP作为响应的内容,这也是默认的数据类型。
-
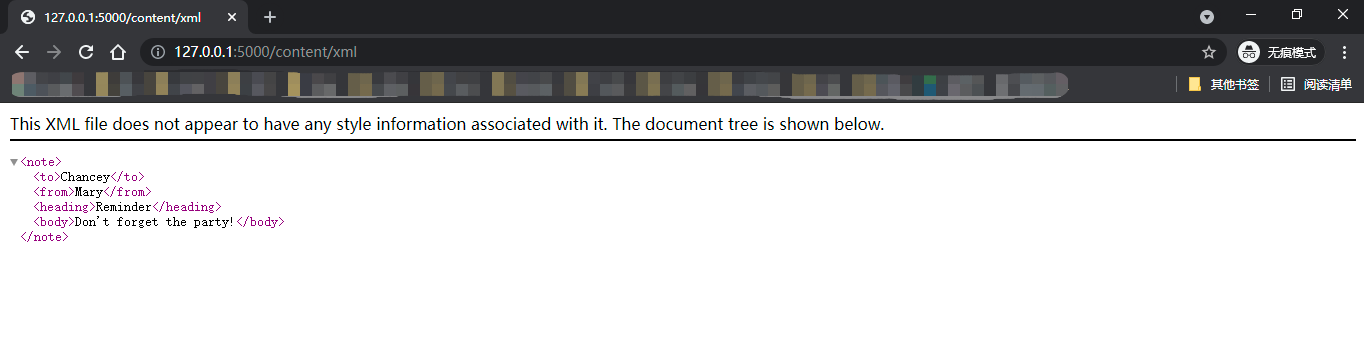
XML
MIME类型:application/xml
<?xml version="1.0" encoding="UTF-8"?> <note> <to>Chancey</to> <from>Mary</from> <heading>Reminder</heading> <body>Don't forget the party!</body> </note>XML指Extensible Markup Language(可扩展标记语言),它是一种简单灵活的文本格式,被设计用来存储和交换数据。XML的出现主要就是为了弥补HTML的不足:对于仅仅需要数据的请求来说,HTML提供的信息太过丰富了,而且不易于重用。XML和HTML一样都是标记性语言,使用标签来定义文本,但HTML中的标签用于显示内容,而XML中的标签只用于定义数据。 XML一般作为AJAX请求的响应格式,或是Web API的响应格式。
-
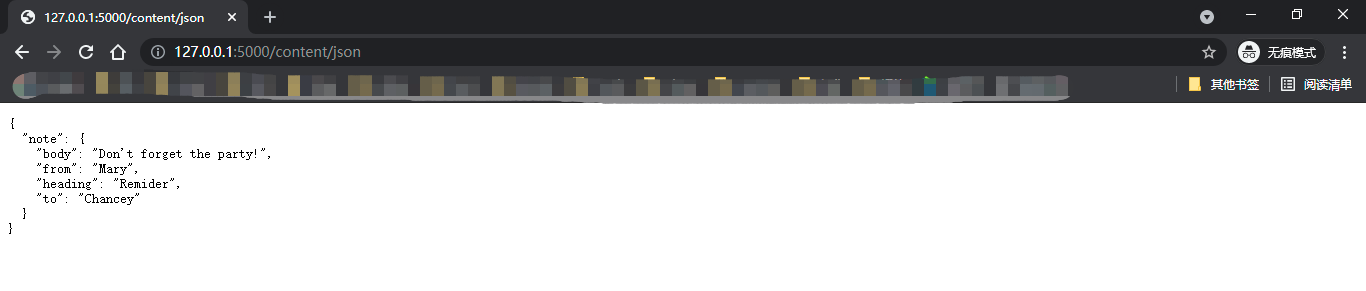
JSON
MIME类型:application/json
{ "note":{ "to":"Peter", "from":"Jane", "heading":"Remider", "body":"Don't forget the party!" } }JSON指JavaScript Object Notation(JavaScript对 象表示法),是一种流行的、轻量的数据交换格式。它的出现又弥补了 XML的诸多不足:XML有较高的重用性,但XML相对于其他文档格式来说体积稍大,处理和解析的速度较慢。
JSON轻量,简洁,容易阅读和解析,而且能和Web默认的客户端语言JavaScript更好地兼容。
JSON的结构基于“键值对的集合”和“有序的值列表”,这两种数据结构类似 Python中的字典(dictionary)和列表(list)。正是因为这种通用的数据结构,使得JSON在同样基于这些结构的编程语言之间交换成为可能。
from flask import Flask, jsonify, make_response
app = Flask(__name__)
@app.route("/content/<content_type>")
def content(content_type):
content_type = content_type.lower()
# text类型
if content_type == 'text':
body = '''Note
to: Chancey
from: Mary
heading: Reminder
body: Don't forget the party!
'''
response = make_response(body)
response.mimetype = 'text/plain'
# html类型
elif content_type == 'html':
body = '''<!DOCTYPE html>
<html>
<head></head>
<body>
<h1>Note</h1>
<p>to: Chancey</p>
<p>from: Mary</p>
<p>heading: Reminder</p>
<p>body: <strong>Don't forget the party!</strong></p>
</body>
</html>
'''
response = make_response(body)
response.mimetype = 'text/html'
# xml类型
elif content_type == 'xml':
body = '''<?xml version="1.0" encoding="UTF-8"?>
<note>
<to>Chancey</to>
<from>Mary</from>
<heading>Reminder</heading>
<body>Don't forget the party!</body>
</note>
'''
response = make_response(body)
response.mimetype = 'application/xml'
# json类型
elif content_type == 'json':
body = {"note":
{
"to": "Chancey",
"from": "Mary",
"heading": "Remider",
"body": "Don't forget the party!"
}
}
response = make_response(json.dumps(body))
response.mimetype = "application/json"
else:
abort(400)
return response


Flask通过引入Python标准库中的json模块为程序提供了JSON支持。也可以直接从Flask中导入json对象,然后调用dumps()方法将字典、列表或元组序列化(serialize)为JSON字符串,再使用前面介绍的方法修改MIME类型,即可返回JSON响应, 如下所示:
from flask import Flask, make_response, json
...
@app.route('/foo')
def foo():
data = {
'name':'Grey Li',
'gender':'male'
}
response = make_response(json.dumps(data))
response.mimetype = 'application/json'
return response
不过一般并不直接使用json模块的dumps()、load()等方法,因为Flask通过包装这些方法提供了更方便的jsonify()函数。借助 jsonify()函数,仅需要传入数据或参数,它会对传入的参数进行序列化,转换成JSON字符串作为响应的主体,然后生成一个响应对象,并且设置正确的MIME类型。使用jsonify函数可以将前面的例子简化为这种形式:
from flask import jsonify
@app.route('/foo')
def foo():
return jsonify(name='ChanceySolo', gender='male')
jsonify()函数接收多种形式的参数。既可以传入普通参数,也可以传入关键字参数。如果想要更直观一点,也可以像使用 dumps()方法一样传入字典、列表或元组。
from flask import jsonify
@app.route('/foo')
def foo():
return jsonify({name='ChanceySolo', gender='male'})
上面两种形式的返回值是相同的,都会生成下面的JSON字符串:
'{"gender": "male", "name": "ChanceySolo"}'
另外,jsonify()函数默认生成200响应,也可以通过附加状态码来自定义响应类型,比如:
@app.route('/foo')
def foo():
return jsonify(message='Error!'), 500
④cookie#
HTTP是无状态(stateless)协议。也就是说,在一次请求响应结束后,服务器不会留下任何关于对方状态的信息。但是对于某些Web程序来说,客户端的某些信息又必须被记住,比如用户的登录状态,这样才可以根据用户的状态来返回不同的响应。为了解决这类问题,就有了Cookie技术。Cookie技术通过在请求和响应报文中添加Cookie数据来保存客户端的状态信息。
Cookie指Web服务器为了存储某些数据(比如用户信息)而保存在浏览器上的小型文本数据。
浏览器会在一定时间内保存它,并在下一次向同一个服务器发送请求时附带这些数据。
Cookie通常被用来进行用户会话管理(比如登录状态),保存用户的个性化信息(比如语言偏好, 视频上次播放的位置,网站主题选项等)以及记录和收集用户浏览数据以用来分析用户行为等。
在Flask中,如果想要在响应中添加一个cookie,最方便的方法是使用Response类提供的set_cookie()方法。要使用这个方法,需要先使用make_response()方法手动生成一个响应对象,传入响应主体作为参数。这个响应对象默认实例化内置的Response类。
Response类的常用属性和方法
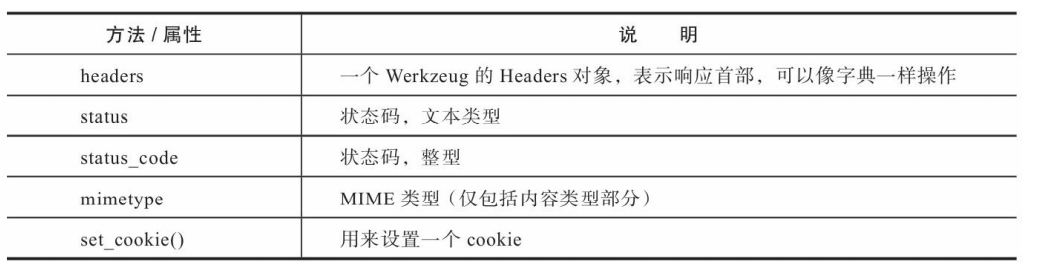
除了如上列出的方法和属性外,Respone类同样拥有和Request类相同的
get_json()方法、is_json()方法以及json属性。
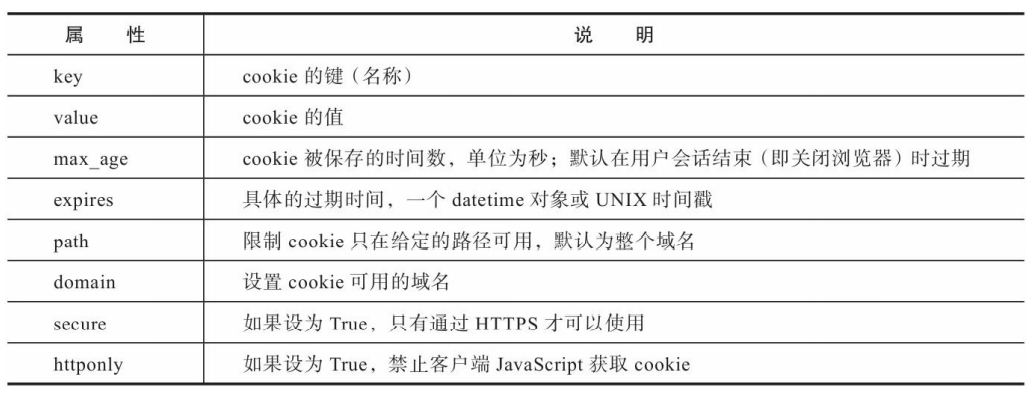
set_cookie()方法支持多个参数来设置Cookie的选项
set_cookie()方法的参数
set_cookie视图用来设置cookie,它会将URL中的name变量的值设置到名为name的cookie里
@app.route("/set/<name>")
def set_cookie(name):
response = make_response(redirect(url_for("Hello")))
response.set_cookie("name", name)
return response
在这个make_response()函数中,传入的是使用redirect()函数生成的重定向响应。
set_cookie视图会在生成的响应报文首部中创建一个Set-Cookie字段,即Set-Cookie:name=Grey;Path=/。
查看浏览器中的Cookie,就会看到多了一块名为name的cookie,其值为设置的“ChanceySolo”。因为过期时间使用默认值,所以会在浏览会话结束时(关闭浏览器)过期。

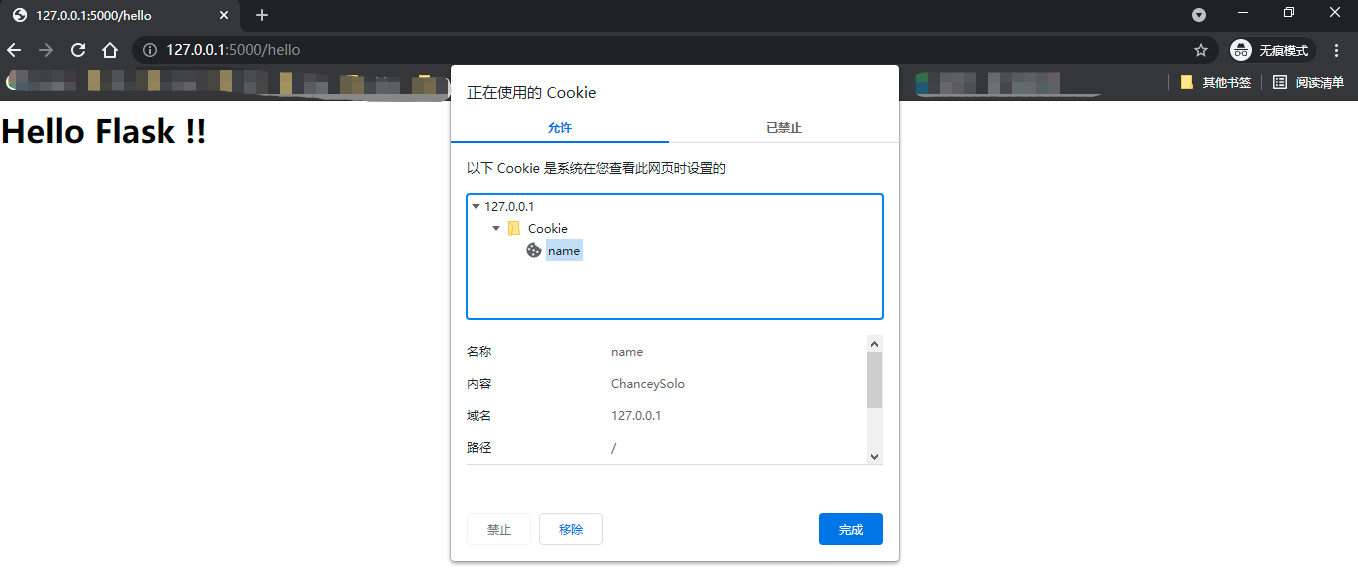
当浏览器保存了服务器端设置的Cookie后,浏览器再次发送到该服务器的请求会自动携带设置的Cookie信息,Cookie的内容存储在请求首部的Cookie字段中,整个交互过程由上到下如下所示。
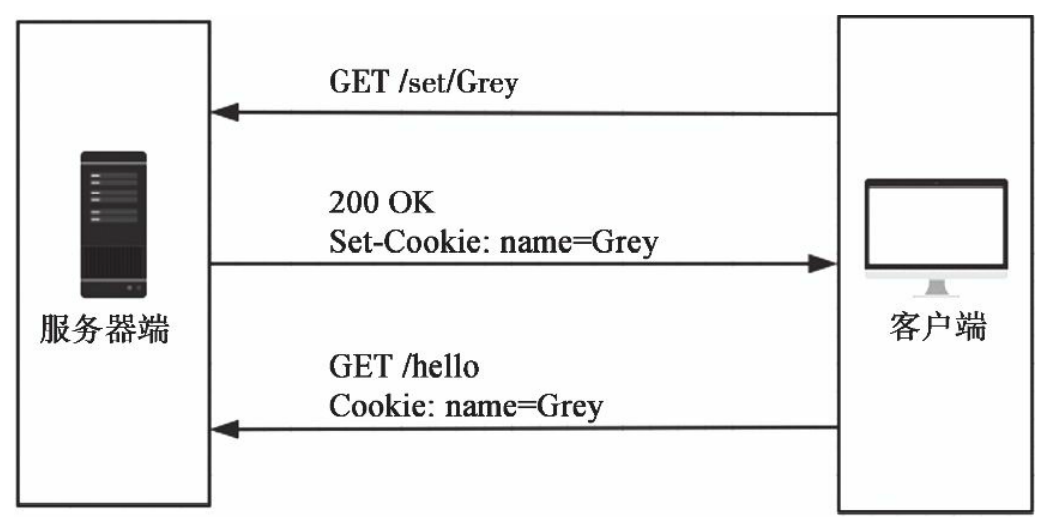
在Flask中,Cookie可以通过请求对象的cookies属性读取。在修改后的hello视图中,如果没有从查询参数中获取到name的值,就从Cookie中寻找:
@app.route("/hello")
def hello():
name = request.args.get("name") # 获取查询参数name的值
if name is None:
name = request.cookies.get("name", "Flask")
return "<h1>Hello %s !</h1>" % name # 插入到返回值中
这个示例函数同样包含安全漏洞。
这时服务器就可以根据Cookie的内容来获得客户端的状态信息,并根据状态返回不同的响应。如果访问http://localhost:5000/set/ChanceySolo,那么就会将名为name的cookie设为ChanceySolo,重定向到/hello后,返回的内容变成了“Hello,ChanceySolo!”。如果你再次通过访问 http://localhost:5000/set/修改name cookie的值,那么重定向后的页面返回的内容也会随之改变。



⑤session#
Cookie在Web程序中发挥了很大的作用,其中最重要的功能是存储用户的认证信息。
先来看看基于浏览器的用户认证是如何实现的。 使用浏览器登录某个社交网站时,会在登录表单中填写用户名和密码,单击登录按钮后,这会向服务器发送一个包含认证数据的请求。 服务器接收请求后会查找对应的账户,然后验证密码是否匹配,如果匹配,就在返回的响应中设置一个cookie,比如,“login_user:ChanceySolo”。 响应被浏览器接收后,cookie会被保存在浏览器中。当用户再次向这个服务器发送请求时,根据请求附带的Cookie字段中的内容,服务器上的程序就可以判断用户的认证状态,并识别出用户。
但是这会带来一个问题,在浏览器中手动添加和修改Cookie是很容易的事,仅仅通过浏览器插件就可以实现。所以,如果直接把认证信息 以明文的方式存储在Cookie里,那么恶意用户就可以通过伪造cookie的内容来获得对网站的权限,冒用别人的账户。为了避免这个问题,需要对敏感的Cookie内容进行加密。方便的是,Flask提供了session对象用来将Cookie数据加密储存。
在编程中,session指用户会话(user session),又称为对话 (dialogue),即服务器和客户端/浏览器之间或桌面程序和用户之间建 立的交互活动。在Flask中,session对象用来加密Cookie。默认情况下, 它会把数据存储在浏览器上一个名为session的cookie里。
a.设置程序密钥
session通过密钥对数据进行签名以加密数据,因此,先设置一个密钥。
这里的密钥就是一个具有一定复杂度和随机性的字符串,比 如“dmwkaoDmio-39cml”。
程序的密钥可以通过Flask.secret_key属性或配置变量SECRET_KEY设置,比如:
app.secret_key = "secret string"
更安全的做法是把密钥写进系统环境变量(在命令行中使用export或set命令),或是保存在.env文件中:
# .env
SECRET_KEY=secret string
然后在程序脚本中使用os模块提供的getenv()方法获取:
from flask import Flask
import os
app.secret_key = os.getenv("secret_key")
可以在getenv()方法中添加第二个参数,作为没有获取到对应环境变量时使用的默认值。
这里的密钥只是示例。在生产环境中,为了安全考虑,必须使用随机生成的密钥
b.模拟用户认证
from flask import Flask, redirect, session, url_for
@app.route("/login")
def login():
session["logged_in"] = True # 写入session
return redirect(url_for("hello"))
这个登录视图只是简化的示例,在实际的登录中,需要在页面上提供登录表单,供用户填写账户和密码,然后在登录视图里验证账户和密码的有效性。session对象可以像字典一样操作,向session中添加一个
logged-incookie,将它的值设为True,表示用户已认证。
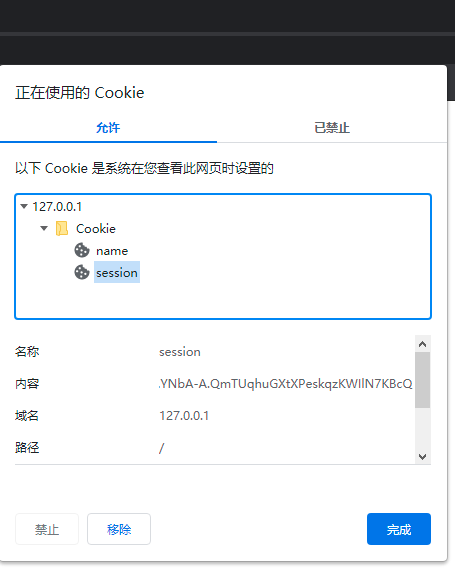
可以在方框内的Content部分看到对应的加密处理后生成的 session值。使用session对象存储的Cookie,用户可以看到其加密后的 值,但无法修改它。因为session中的内容使用密钥进行签名,一旦数据被修改,签名的值也会变化。这样在读取时,就会验证失败,对应的 session值也会随之失效。所以,除非用户知道密钥,否则无法对session cookie的值进行修改
当支持用户登录后,就可以根据用户的认证状态分别显示不同的内容。在login视图的最后,将程序重定向到hello视图,下面是修 改后的hello视图:
@app.route('/')
@app.route('/hello')
def hello():
name = request.args.get('name')
if name is None:
name = request.cookies.get('name')
response = '<h1>Hello, %s!</h1>' % name
# 根据用户认证状态返回不同的内容if 'logged_in' in session:
response += '[已登录]'
else:
response += '[未登录]'
return response


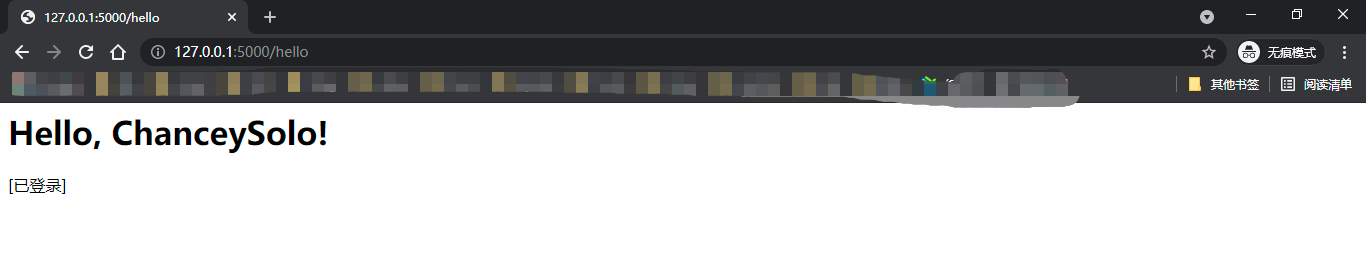
session中的数据可以像字典一样通过键读取,或是使用get()方法。这里只是判断session中是否包含logged_in键,如果有则表示用户已经登录。通过判断用户的认证状态,在返回的响应中添加一行表示认证状态的信息:如果用户已经登录,显示[已登陆];否则 显示[未登录]。
如果访问http://localhost:5000/login,就会登入当前用户,重定向到http://localhost:5000/hello后会发现加载后的页面显示一 行“[已登陆]”,表示当前用户已经通过认证
程序中的某些资源仅提供给登入的用户,比如管理后台,这时就可以通过判断session是否存在logged-in键来判断用户是否认证
from flask import session, abort
@app.route("/admin")
def admin():
if "logged_in" not in session:
abort(403)
return "欢迎登录后台管理页面"
登录之后
通过判断logged_in是否在session中,可以实现:如果用户已经认证,会返回一行提示文字,否则会返回403错误响应。
登出用户的logout视图也非常简单,登出账户对应的实际操作其实就是把代表用户认证的logged-in cookie删除,这通过session对象的pop方法实现
from flask import session
@app.route('/logout')
def logout():
if 'logged_in' in session:
session.pop('logged_in')
return redirect(url_for('hello'))
默认情况下,session cookie会在用户关闭浏览器时删除。通过将 session.permanent属性设为True可以将session的有效期延长为 Flask.permanent_session_lifetime属性值对应的datetime.timedelta对象,也可通过配置变量PERMANENT_SESSION_LIFETIME设置,默认为31 天。
尽管session对象会对Cookie进行签名并加密,但这种方式仅能够确 保session的内容不会被篡改,加密后的数据借助工具仍然可以轻易读取 (即使不知道密钥)。因此,绝对不能在session中存储敏感信息,比如 用户密码。
三、Flask上下文#
为了便于理解,可以把编程中的上下文理解为当前环境的快照。如果把一个Flask程序比作一条可怜的生活在鱼缸里的鱼,那么它当然离不开身边的环境。
这里的上下文和阅读文章时的上下文基本相同。
如果在某篇文章里单独抽出一句话来看,可能会觉得摸不着头脑,只有联系上下文后才能正确理解文章。
Flask中有两种上下文,程序上下文和请求上下文。
如果鱼想要存活,水是必不可少的元素。对于 Flask程序来说,程序上下文就是水。水里包含了各种浮游生物以及微生物,正如程序上下文中存储了程序运行所必须的信息;要想健康地活下去,鱼还离不开阳光。射进鱼缸的阳光就像是程序接收的请求。当客户端发来请求时,请求上下文就登场了。请求上下文里包含了请求的各种信息,比如请求的URL,请求的HTTP方法等。
1.上下文全局变量#
每一个视图函数都需要上下文信息,在前面介绍的Flask将请求报文封装在request对象中。
按照一般的思路,如果要在视图函数中使用它,就得把它作为参数传入视图函数,就像接收URL变量一 样。但是这样一来就会导致大量的重复,而且增加了视图函数的复杂度。
在前面的示例中,并没有传递这个参数,而是直接从Flask导入一个全局的request对象,然后在视图函数里直接调用request的属性获取数据。
Flask会在每个请求产生后自动激活当前请求的上下文,激活请求上下文后,request被临时设为全局可访问。而当每个请求结束后,Flask就销毁对应的请求上下文。 在前面说request是全局对象,但这里的“全局”并不是实际意义上的全局。可以把这些变量理解为动态的全局变量。
在多线程服务器中,在同一时间可能会有多个请求在处理。假设有三个客户端同时向服务器发送请求,这时每个请求都有各自不同的请求 报文,所以请求对象也必然是不同的。因此,请求对象只在各自的线程内是全局的。
Flask通过本地线程(thread local)技术将请求对象在特定的线程和请求中全局可访问。为了方便获取这两种上下文环境中存储的信息,Flask提供了四个上下文全局变量
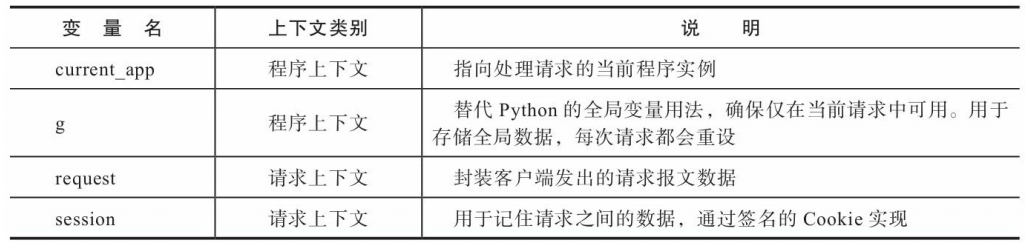
这四个变量都是代理对象,即指向真实对象的代理。一 般情况下,不需要太关注其中的区别。在某些特定的情况下,如果需要获取原始对象,可以对代理对象调用_get_current_object()方法获取被代理的真实对象。
在不同的视图函数中,request对象都表示和视图函数对应的请求,也就是当前请求(current request)。而程序也会有多个程序实例的情况,为了能获取对应的程序实例,而不是固定的某一个程序实例,就需要使用current_app变量
因为g存储在程序上下文中,而程序上下文会随着每一个请求的进入而激活,随着每一个请求的处理完毕而销毁。所以每次请求都会重设这个值。会使用它结合请求钩子来保存每个请求处理前所需要的全局变量,比如当前登入的用户对象,数据库连接等。在前面的示例中,在hello视图中从查询字符串获取name的值,如果每一个视图都需要这个值,那么就要在每个视图重复这行代码。借助g可以将这个操作移动到before_request处理函数中执行,然后保存到g的任意属性上:
from flask import g
@app.before_request
def get_name():
g.name = request.args.get('name')
设置这个函数后,在其他视图中可以直接使用g.name获取对应的 值。另外,g也支持使用类似字典的get()、pop()以及setdefault()方法进行操作。
2.激活上下文#
阳光柔和,鱼儿在水里欢快地游动,这一切都是上下文存在后的美好景象。如果没有上下文,程序只能直挺挺地躺在鱼缸里。在下面这些情况下,Flask会自动激活程序上下文:
- 使用
flask run命令启动程序时。 - 使用旧的
app.run()方法启动程序时。 - 执行使用
@app.cli.command()装饰器注册的flask命令时。 - 使用flask shell命令启动Python Shell时。
当请求进入时,Flask会自动激活请求上下文,这时可以使用 request和session变量。另外,当请求上下文被激活时,程序上下文也被自动激活。当请求处理完毕后,请求上下文和程序上下文也会自动销毁。也就是说,在请求处理时这两者拥有相同的生命周期。
结合Python的代码执行机制理解,这也就意味着,在视图函数中或在视图函数内调用的函数/方法中使用所有上下文全局变量。 在使用flask shell命令打开的Python Shell中,或是自定义的flask命令函数 中,可以使用current_app和g变量,也可以手动激活请求上下文来使用request和session。
如果在没有激活相关上下文时使用这些变量,Flask就会抛出 RuntimeError异常:RuntimeError:Working outside of application context.或是RuntimeError:Working outside of request context.。
同样依赖于上下文的还有
url_for()、jsonify()等函数,所以也只能在视图函数中使用它们。其中jsonify()函数内部调用中使用了current_app变量,而url_for()则需要依赖请求上下文才可以正常运 行。
如果需要在没有激活上下文的情况下使用这些变量,可以手动激活上下文。
In [1]: from app import app
In [2]: from flask import current_app
In [3]: with app.app_context():
...: info = current_app.name
...: print(info)
app
程序上下文对象使用
app.app_context()获取,可以使用with语句执行上下文操作
或者可以显式使用push()方法推送(激活)上下文,在执行完相关操作时使用pop()方法销毁上下文
[root@localhost HelloFlask01]# workon py3env
(py3env) [root@localhost HelloFlask01]# ipython
Python 3.6.5 (default, Jun 6 2021, 01:55:48)
Type 'copyright', 'credits' or 'license' for more information
IPython 7.16.1 -- An enhanced Interactive Python. Type '?' for help.
In [1]: from app import app
In [2]: from flask import current_app
In [3]: app_ctx = app.app_context()
In [4]: app_ctx.push()
In [5]: print(current_app.name)
app
In [6]: app_ctx.pop()
而请求上下文可以通过test_request_context()方法临时创建:
In [7]: from app import app
In [8]: from flask import request
In [9]: with app.test_request_context("/hello"):
...: request.method
...:
'GET'
In [10]:
同样的,这里也可以使用push()和pop()方法显式地推送和销 毁请求上下文。
3.上下文钩子#
在上文中介绍了请求生命周期中可以使用的几种钩子,Flask也为上下文提供了一个teardown_appcontext钩子,使用它注册的回调函数会在程序上下文被销毁时调用,而且通常也会在请求上下文被销毁时调用。比如,需要在每个请求处理结束后销毁数据库连接:
@app.teardown_appcontext
def teardown_db(exception):
...
db.close()
使用app.teardown_appcontext装饰器注册的回调函数需要接收异常对象作为参数,当请求被正常处理时这个参数值将是None,这个函数的 返回值将被忽略。
四、HTTP进阶实战#
此处将会介绍有关上述所介绍的实际开发中所用到的
1.重定向回上一个页面#
在前面的示例程序中,使用redirect()函数生成重定向响应。
比如,在login视图中,登入用户后将用户重定向到/hello页面。在复杂的应用场景下,需要在用户访问某个URL后重定向到上一个页面。
最常见的情况是,用户单击某个需要登录才能访问的链接,这时程序会重定向到登录页面,当用户登录后合理的行为是重定向到用户登录前浏览的页面,以便用户执行未完成的操作,而不是直接重定向到主页。在示例程序中,创建两个视图函数foo和bar,分别显示一个 Foo页面和一个Bar页面,如下所示:
@app.route("/foo")
def foo():
return "<h1>Foo page</h1><a href="%s">Do something</a>" % url_for("do_something")
@app.route("/bar")
def bar():
return "<h1>Bar page</h1><a href="%s">Do something</a>" % url_for("do_something")
在这两个页面中,添加了一个指向do_something视图的链接。这个do_something视图如下所示:
@app.route("/do_something")
def do_something():
return redirect(url_for('hello'))
这里需要这个视图在执行完相关操作后能够重定向回上一个页面,而不是固定的/hello页面。也就是说,如果在Foo页面上单击链接,需要被重定向回Foo页面;如果在Bar页面上单击链接,我们则希望返回到Bar页面。
①获取上一个页面的URL#
要重定向回上一个页面,最关键的是获取上一个页面的URL。上一个页面的URL一般可以通过两种方式获取:
a. HTTP referer
HTTP referer(起源为referrer在HTTP规范中的错误拼写)是一个用来记录请求发源地址的HTTP首部字段(HTTP_REFERER),即访问来源。
当用户在某个站点单击链接,浏览器向新链接所在的服务器发起请求,请求的数据中包含的HTTP_REFERER字段记录了用户所在的原站点URL。这个值通常会用来追踪用户,比如记录用户进入程序的外部站点,以此来更有针对性地进行营销。
在Flask中,referer的值可以通过请求对象的referrer属性获取,即request.referrer(正确拼写形式)。现在,do_something视图的返回值可以这样编写:
return redirect(request.referrer)
但是在很多种情况下,referrer字段会是空值,比如用户在浏览器的地址栏输入URL,或是用户出于保护隐私的考虑使用了防火墙软件或使用浏览器设置自动清除或修改了referrer字段。这时需要添加一个备选项(即跳转到主页)
return redirect(request.referrer or url_for('hello'))
b.查询参数
除了自动从referrer获取,另一种更常见的方式是在URL中手动加入包含当前页面URL的查询参数,这个查询参数一般命名为next。比如,下面在foo和bar视图的返回值中的URL后添加next参数
@app.route("/foo")
def foo():
return '<h1>Foo page</h1><a href="%s">Do something and redirect</a>' % url_for('do_something', next=request.full_path)
@app.route("/bar")
def bar():
return '<h1>Bar page</h1><a href="%s">Do something and redirect</a>' % url_for('do_something', next=request.full_path)
在程序内部只需要使用相对URL,所以这里使用request.full_path获取当前页面的完整路径。在do_something视图中,获取这个next值,然后重定向到对应的路径(当然,这里也要添加为空的情况):
return redirect(request.args.get('next', url_for('hello')))
为了覆盖更全面,可以将这两种方式搭配起来一起使用:首先获取next参数,如果为空就尝试获取referer,如果仍然为空,那么就重定向到默认的hello视图。因为在不同视图执行这部分操作的代码完全相同,可以创建一个通用的redirect_back()函数
def redirect_back(default='hello', **kwargs):
for target in request.args.get('next'), request.referrer:
if target:
return redirect(target)
return redirect(url_for(default, **kwargs))
通过设置默认值,可以在referer和next为空的情况下重定向到默认的视图。在do_something视图中使用这个函数的示例如下所示:
@app.route('/do_something_and_redirect')
def do_something():
return redirect_back()
②对URL进行安全验证#
虽然已经实现了重定向回上一个页面的功能,但安全问题不容小觑,鉴于referer和next容易被篡改的特性,如果不对这些值进行验证,则会形成开放重定向(Open Redirect)漏洞。以URL中的next参数为例,next变量以查询字符串的方式写在URL里,因此任何人都可以发给某个用户一个包含next变量指向任何站点的链接。举个简单的例子,如果访问http://localhost:5000/do-something?next=http://helloflask.com 程序会被重定向到http://helloflask.com。也就是说,如果不验证next变量指向的URL地址是否属于应用内,那么程序很容易就会被重定向到外部地址。
假设应用是一个银行业务系统(下面简称网站A),某个攻击者模仿我们的网站外观做了一个几乎一模一样的网站(下面简称网站B)。接着,攻击者伪造了一封电子邮件,告诉用户网站A账户信息需要更新,然后向用户提供一个指向网站A登录页面的链接,但链接中包含一个重定向到网站B的next变量,比如:
http://exampleA.com/login?next=http://maliciousB.com。当用户在A网站登录后,如果A网站重定向 到next对应的URL,那么就会导致重定向到攻击者编写的B网站。因为B网站完全模仿A网站的外观,攻击者就可以在重定向后的B网站诱导用户输入敏感信息,比如银行卡号及密码。
确保URL安全的关键就是判断URL是否属于程序内部,创建一个URL验证函数is_safe_url(),用来验证next变量值是否属于程序内部URL。
from urlparse import urlparse, urljoin
# Python3需要从urllib.parse导入
from flask import request
def is_safe_url(target):
ref_url = urlparse(request.host_url)
test_url = urlparse(urljoin(request.host_url, target))
return test_url.scheme in ('http', 'https') and ref_url.netloc == test_url.netloc
注意:如果使用Python3,那么这里需要从urllib.parse模块导入urlparse和urljoin函数。示例程序仓库中实际的代码做了兼容性处理。
这个函数接收目标URL作为参数,并通过request.host_url获取程序内的主机URL,然后使用urljoin()函数将目标URL转换为绝对URL。接着,分别使用urlparse模块提供的urlparse()函数解析两个URL,最后对目标URL的URL模式和主机地址进行验证,确保只有属于程序内部的URL才会被返回。在执行重定向回上一个页面的redirect_back()函数中,使用is_safe_url()验证next和referer的值:
def redirect_back(default='hello', **kwargs):
for target in request.args.get('next'), request.referrer:
if not target:
continue
if is_safe_url(target):
return redirect(target)
return redirect(url_for(default, **kwargs))
2.使用AJAX技术发送异步请求#
在传统的Web应用中,程序的操作都是基于请求响应循环来实现的。每当页面状态需要变动,或是需要更新数据时,都伴随着一个发向服务器的请求。当服务器返回响应时,整个页面会重载,并渲染新页面。这种模式会带来一些问题。首先,频繁更新页面会牺牲性能,浪费服务器资源,同时降低用户体验。另外,对于一些操作性很强的程序来说,重载页面会显得很不合理。比如做了一个Web计算器程序,所有的按钮和显示屏幕都很逼真,但当我们单击“等于”按钮时,要等到页面重新加载后才在显示屏幕上看到结果,这显然会严重影响用户体验。而AJAX技术可以完美地解决这些问题。
①认识AJAX#
AJAX指异步Javascript和XML(Asynchronous JavaScript AndXML),它不是编程语言或通信协议,而是一系列技术的组合体。简单来说,AJAX基于XMLHttpRequest(https://xhr.spec.whatwg.org/)让我们可以在不重载页面的情况下和服务器进行数据交换。加上JavaScript和DOM(Document Object Model,文档对象模型),就可以在接收到响应数据后局部更新页面。而XML指的则是数据的交互格式,也可以是纯文本(Plain Text)、HTML或JSON。顺便说一句,XMLHttpRequest不仅支持HTTP协议,还支持FILE和FTP协议。
在Web程序中,很多加载数据的操作都可以在客户端使用AJAX实现。比如,当用户鼠标向下滚动到底部时在后台发送请求获取数据,然后插入文章;再比如,用户提交表单创建新的待办事项时,在后台将数据发送到服务器端,保存后将新的条目直接插入到页面上。在这种模式下,可以在客户端实现大部分页面逻辑,而服务器端则主要负责处理数据。这样可以避免每次请求都渲染整个页面,这不仅增强了用户体验,也降低了服务器的负载。
AJAX让Web程序也可以像桌面程序那样获得更流畅的反应和动态效果。总而言之,AJAX让Web程序更像是程序,而非一堆使用链接和按钮连接起来的网页资源。
以删除某个资源为例,在普通的程序中流程如下:
- 当“删除”按钮被单击时会发送一个请求,页面变空白,在接收到响应前无法进行其他操作。
- 服务器端接收请求,执行删除操作,返回包含整个页面的响应。
- 客户端接收到响应,重载整个页面。
使用AJAX技术时的流程如下:
- 当单击“删除”按钮时,客户端在后台发送一个异步请求,页面不变,在接收响应前可以进行其他操作。
- 服务器端接收请求后执行删除操作,返回提示消息或是无内容的204响应。
- 客户端接收到响应,使用JavaScript更新页面,移除资源对应的页面元素。
②使用jQuery发送AJAX请求#
jQuery是流行的JavaScript库,它包装了JavaScript,可以通过更简单的方式编写JavaScript代码。
对于AJAX,它提供了多个相关的方法,使用它可以很方便地实现AJAX操作。更重要的是,jQuery处理了不同浏览器的AJAX兼容问题,只需要编写一套代码,就可以在所有主流的浏览器正常运行。
使用jQuery实现AJAX并不是必须的,你可以选择使用原生的XMLHttpRequest、其他JavaScript框架内置的AJAX接口,或是使用更新的Fetch API(https://fetch.spec.whatwg.org/)来发送异步请求。
使用全局jQuery函数ajax()发送AJAX请求。ajax()函数是底层函数,有丰富的自定义配置,支持的主要参数
| 参数 | 参数值类型及默认值 | 说明 |
|---|---|---|
| url | 字符串;默认为当前页地址 | 请求的地址 |
| type | 字符串;默认为GET | 请求的方式,即HTTP方法,比如GET、POST、DELETE等 |
| data | 字符串;无默认值 | 发送到服务器的数据。会被jQuery自动转换为查询字符串 |
| dataType | 字符串;默认由jQuery自动判断 | 期待服务器返回的数据类型,可用的值如下:xml、html、script、json、text |
| contentType | 字符串;默认为application/x-www-form-urlencoded;charset=UTF-8 |
发送请求时使用的内容类型,即请求首部的Content-Type字段内容 |
| complete | 函数;无默认值 | 请求完成后调用的回调函数 |
| success | 函数;无默认值 | 请求成功后调用的回调函数 |
| error | 函数;无默认值 | 请求失败后调用的回调函数 |
完整的可用配置参数列表可以在这里看到:点击跳转。
jQuery还提供了其他快捷方法(shorthand method):用于发送GET请求的
get()方法和用于发送POST请求的post()方法,还有直接用于获取json数据的getjson()以及获取脚本的getscript()方法。这些方法都是基于ajax()方法实现的。在这里,为了便于理解,使用了底层的ajax方法。jQuery中和AJAX相关的方法及其具体用法可以在这里看到:点击跳转。
③返回局部数据#
对于处理AJAX请求的视图函数来说,我们不会返回完整的HTML响应,这时一般会返回局部数据,常见的三种类型如下所示:
a.纯文本或局部的HTML模板
@app.route('/comments/<int:post_id>')
def get_comments(post_id):
...
return render_template('comments.html')
b.json数据
JSON数据可以在JavaScript中直接操作:
@app.route('/profile/<int:user_id>')
def get_profile(user_id):
...
return jsonify(username=username, bio=bio)
在jQuery中的
ajax()方法的success回调中,响应主体中的JSON字符串会被解析为JSON对象,可以直接获取并进行操作。
c.空值
有些时候,程序中的某些接收AJAX请求的视图并不需要返回数据给客户端,比如用来删除文章的视图。这时可以直接返回空值,并将状态码指定为204(表示无内容)
@app.route('/post/delete/<int:post_id>', methods=['DELETE'])
def delete_post(post_id):
...
return '', 204
④异步加载长文章示例#
在示例程序的对应页面中,显示一篇很长的虚拟文章,文章正文下方有一个“加载更多”按钮,当加载按钮被单击时,会发送一个AJAX请求获取文章的更多内容并直接动态插入到文章下方。用来显示虚拟文章的show_post。
from jinjia2.utils import generate_lorem_ipsum
@app.route("post")
def show_post():
html = """
<h1>A very long post</h1>
<div class="body">%s</div>
<button id="load">Load More</button>
<script src="https://code.jquery.com/jquery-3.3.1.min.js"></script>
<script type="text/javascript">
$(function(){
$('#load').click(function(){
$.ajax({
url: '/more', // 目标URL
type: 'get', // 请求方法
success: function(data){ // 返回2XX响应后触发的回调函数
$('.body').append(data); // 将返回的响应插入到页面中
}
})
})
})
</script>
"""
post_body = generate_lorem_ipsum(n = 5) # 生成5段随机文本
return html % post_body
文章的随机正文通过Jinja2提供的generate_lorem_ipsum()函数生成,n参数用来指定段落的数量,默认为5,它会返回由随机字符组成的虚拟文章。文章下面添加了一个“加载更多”按钮。按钮下面是两个<script></script>代码块,第一个script从CDN加载jQuery资源。
在第二个script标签中,代码的最外层创建了一个$(function(){...})函数,这个函数是常见的$(document).ready(function(){...})函数的简写形式。这个函数用来在页面DOM加载完毕后执行代码,类似传统JavaScript中的window.onload方法,所以通常会将代码包装在这个函数中。美元符号是jQuery的简写,通过它来调用jQuery提供的多个方法,所以$.ajax()等同于jQuery.ajax()。
在$(function(){...}中,$'#load'被称为选择器,在括号中传入目标元素的id、class或是其他属性来定位到对应的元素,将其创建为jQuery对象。传入了“加载更多”按钮的id值以定位到加载按钮。在这个选择器上,附加了.clickfunction{...},这会为加载按钮注册一个单击事件处理函数,当加载按钮被单击时就会执行单击事件回调函数。在这个回调函数中,使用$.ajax方法发送一 个AJAX请求到服务器,通过url将目标URL设为“/more”,通过type参数将请求的类型设为GET。当请求成功处理并返回2XX响应时另外还包括304响应,会触发success回调函数。success回调函数接收的第一个 参数为服务器端返回的响应主体,在这个回调函数中,文章正文通过$'.body'选择底部使用append方法插入返回的data数据。
@app.route('/more')
def load_post():
return generate_lorem_ipsum(n=5)
在出版业和设计业,lorem ipsum指一段常用的无意义的填充文字。以lorem ipsum开头的这段填充文本是抽取哲学著作《On the ends of good and evil》中的文段,并对单词进行删改调换而来。
3.HTTP服务器端推送#
不论是传统的HTTP请求-响应式的通信模式,还是异步的AJAX式请求,服务器端始终处于被动的应答状态,只有在客户端发出请求的情况下,服务器端才会返回响应。这种通信模式被称为客户端拉取(client pull)。在这种模式下,用户只能通过刷新页面或主动单击加载按钮来拉取新数据。
然而,在某些场景下,需要的通信模式是服务器端的主动推送 (server push)。比如,一个聊天室有很多个用户,当某个用户发送消息后,服务器接收到这个请求,然后把消息推送给聊天室的所有用户。类似这种关注实时性的情况还有很多,比如社交网站在导航栏实时显示新提醒和私信的数量,用户的在线状态更新,股价行情监控、显示商品库存信息、多人游戏、文档协作等。实现服务器端推送的一系列技术被合称为HTTP Server Push(HTTP服务器端推送),目前常用的推送技术如下:
| 名 称 | 说 明 |
|---|---|
| 传统轮询 | 在特定的时间间隔内,客户端使用AJAX技术不断向服务器发送HTTP请求,然后获取新的数据并更新页面 |
| 长轮询 | 和传统轮询类似,但是如果服务器端没有返回数据,那就保持连接一直开启,直到有数据时才返回。取回数据后再次发送另一个请求 |
| Server-Sent Events(SSE) | SSE通过HTML5中的EventSource API实现。SSE会在客户端和服务器之间建立一个单向的通道,客户端监听来自服务端的数据,而服务器可以在任意时间发送数据,两者建立类似订阅/发布的通信模式 |
按照列出的顺序来说,这几种方式对实时通信的实现越来越完善。当然,每种技术都有各自的优缺点,在具体的选择上,要根据面向的用户群以及程序自身的特点来分析选择。
轮询(polling)这类使用AJAX技术模拟服务器端推送的方法实现起来比较简单,但通常会造成服务器资源上的浪费,增加服务器的负担,而且会让用户的设备耗费更多的电量(频繁地发起异步请求)。SSE效率更高,在浏览器的兼容性方面,除了Windows IE/Edge,SSE基本上支持所有主流浏览器,但浏览器通常会限制标签页的连接数量。
除了这些推送技术,在HTML5的API中还包含了一个WebSocket协议,和HTTP不同,它是一种基于TCP协议的全双工通信协议(full-duplex communication protocol)。和前面介绍的服务器端推送技术相比,WebSocket实时性更强,而且可以实现双向通信(bidirectional communication)。另外,WebSocket的浏览器兼容性要强于SSE。
4.Web安全防范#
无论是简单的博客,还是大型的社交网站,Web安全都应该放在首位。Web安全问题涉及广泛,我们在这里介绍其中常见的几种攻击(attack)和其他常见的漏洞(vulnerability)。 对于Web程序的安全问题,一个首要的原则是:永远不要相信你的用户。大部分Web安全问题都是因为没有对用户输入的内容进行“消毒”造成的。
①注入攻击#
SQL是一种功能齐全的数据库语言,也是关系型数据库的通用操作语言。使用它可以对数据库中的数据进行修改、查询、删除等操作;ORM是用来操作数据库的工具,使用它可以在不手动编写SQL语句的情况下操作数据库。
a.攻击原理
在编写SQL语句时,如果直接将用户传入的数据作为参数使用字符串拼接的方式插入到SQL查询中,那么攻击者可以通过注入其他语句来执行攻击操作,这些攻击操作包括可以通过SQL语句做的任何事:获取敏感数据、修改数据、删除数据库表……
b.攻击示例
假设程序是一个学生信息查询程序,其中的某个视图函数接收用户输入的密码,返回根据密码查询对应的数据。数据库由一个db对象表示,SQL语句通过execute()方法执行:
@app.route('/students')
def bobby_table():
password = request.args.get('password')
cur = db.execute("SELECT * FROM students WHERE password='%s';" % password)
results = cur.fetchall()
return results
在实际应用中,敏感数据需要通过表单提交的POST请求接收,这里为了便于演示,通过查询参数接收。
通过查询字符串获取用户输入的查询参数,并且不经过任何处理就使用字符串格式化的方法拼接到SQL语句中。在这种情况下,如果攻击者输入的password参数值为'or 1=1--, 即http://example.com/students?password='or 1=1--,那么最终视图函数中 被执行的SQL语句将变为:
SELECT * FROM students WHERE password='' or 1=1 --;
这时会把students表中的所有记录全部查询并返回,也就意味着所有的记录都被攻击者窃取了。更可怕的是,如果攻击者将password参数的值设为';drop table users;--,那么查询语句就会变成:
SELECT * FROM students WHERE password=''; drop table students; --;
执行这个语句会把students表中的所有记录全部删除掉。
在SQL中,
;用来结束一行语句;--用来注释后面的语句,类似Python中的“#”。
c.主要防范方法
1)使用ORM可以一定程度上避免SQL注入问题。
2)验证输入类型。比如某个视图函数接收整型id来查询,那么就在URL规则中限制URL变量为整型。
3)参数化查询。在构造SQL语句时避免使用拼接字符串或字符串格式化(使用百分号或format()方法)的方式来构建SQL语句。而要使用各类接口库提供的参数化查询方法,以内置的sqlite3库为例:
db.execute('SELECT * FROM students WHERE password=?, password)
4)转义特殊字符,比如引号、分号和横线等。使用参数化查询时,各种接口库会做转义工作。
②XSS攻击#
a.攻击原理
XSS是注入攻击的一种,攻击者通过将代码注入被攻击者的网站中,用户一旦访问网页便会执行被注入的恶意脚本。XSS攻击主要分为反射型XSS攻击(Reflected XSS Attack)和存储型XSS攻击(Stored XSS Attack)两类。
b.攻击示例
反射型XSS又称为非持久型XSS(Non-Persistent XSS)。当某个站点存在XSS漏洞时,这种攻击会通过URL注入攻击脚本,只有当用户访问这个URL时才会执行攻击脚本。前面介绍查询字符串和cookie时引入的示例就包含反射型XSS漏洞,如下所示:
@app.route('/hello')
def hello():
name = request.args.get('name')
response = '<h1>Hello, %s!</h1>' % name
这个视图函数接收用户通过查询字符串传入的数据,未做任何处理就把它直接插入到返回的响应主体中,返回给客户端。如果某个用户输入了一段JavaScript代码作为查询参数name的值,如下所示:
http://example.com/hello?name=<script>alert('Bingo!');</script>
客户端接收的响应将变为下面的代码:
<h1>Hello, <script>alert('Bingo!');</script>!</h1>
当客户端接收到响应后,浏览器解析这行代码就会打开一个弹窗
能够执行alert()函数就意味着通过这种方式可以执行任意JavaScript代码。即攻击者通过JavaScript几乎能够做任何事情:窃取用户的cookie和其他敏感数据,重定向到钓鱼网站,发送其他请求,执行诸如转账、发布广告信息、在社交网站关注某个用户等。
即使不插入JavaScript代码,通过HTML和CSS(CSS注入)也可以影响页面正常的输出,篡改页面样式,插入图片等。
如果网站A存在XSS漏洞,攻击者将包含攻击代码的链接发送给网站A的用户Foo,当Foo访问这个链接就会执行攻击代码,从而受到攻击。存储型XSS也被称为持久型XSS(persistent XSS),这种类型的XSS攻击更常见,危害也更大。它和反射型XSS类似,不过会把攻击代码储存到数据库中,任何用户访问包含攻击代码的页面都会被殃及。比如,某个网站通过表单接收用户的留言,如果服务器接收数据后未经处理就存储到数据库中,那么用户可以在留言中插入任意JavaScript代码。
比如,攻击者在留言中加入一行重定向代码:
<script>window.location.href="http://attacker.com";</script>其他任意用户一旦访问留言板页面,就会执行其中的JavaScript脚本。那么其他用户一旦访问这个页面就会被重定向到攻击者写入的站点。
c.主要防范方法
- HTML转义
防范XSS攻击最主要的方法是对用户输入的内容进行HTML转义,转义后可以确保用户输入的内容在浏览器中作为文本显示,而不是作为代码解析。
这里的转义和Python中的概念相同,即消除代码执行时的歧义,也就是把变量标记的内容标记为文本,而不是HTML代码。具体来说,这会把变量中与HTML相关的符号转换为安全字符,以避免变量中包含影响页面输出的HTML标签或恶意的JavaScript代码。比如,使用Jinja2提供的escape()函数对用户传入的数据进行转义:
from jinja2 import escape
@app.route('/hello')
def hello():
name = request.args.get('name')
response = '<h1>Hello, %s!</h1>' % escape(name)
在Jinja2中,HTML转义相关的功能通过Flask的依赖包MarkupSafe实现。调用
escape()并传入用户输入的数据,可以获得转义后的内容,前面的示例中,用户输入的JavaScript代码将被转义为:
<script>alert("Bingo!")</sript>转义后,文本中的特殊字符(比如“>”和“<”)都将被转义为HTML实体,这行文本最终在浏览器中会被显示为文本形式的
<script>alert('Bingo!')</script>
不过一般不会在视图函数中直接构造返回的HTML响应,而是会使用Jinja2来渲染包含变量的模板
- 验证用户输入
XSS攻击可以在任何用户可定制内容的地方进行,例如图片引用、自定义链接。仅仅转义HTML中的特殊字符并不能完全规避XSS攻击,因为在某些HTML属性中,使用普通的字符也可以插入JavaScript代码。除了转义用户输入外,还需要对用户的输入数据进行类型验证。在所有接收用户输入的地方做好验证工作。以某个程序的用户资料页面为例,演示一下转义无法完全避免的XSS攻击。程序允许用户输入个人资料中的个人网站地址,通过下面的方式显示在资料页面中:
<a href="{{ url }}">Website</a>
其中{{url}}部分表示会被替换为用户输入的url变量值。如果不对URL进行验证,那么用户就可以写入JavaScript代码,比如javascript:alert()'Bingo!');。因为这个值并不包含会被转义的<和>。最终页面上的链接代码会变为:
<a href="javascript:alert('Bingo!');">Website</a>
当用户单击这个链接时,就会执行被注入的攻击代码。
另外,程序还允许用户自己设置头像图片的URL。这个图片通过下面的方式显示:
<img src="{{ url }}">
类似的,{{url}}部分表示会被替换为用户输入的url变量值。如果不对输入的URL进行验证,那么用户可以将url设为123"onerror="alert('Bingo!'),最终的<img>标签就会变为:
<img src="123" onerror="alert('Bingo!')">
在这里因为src中传入了一个错误的URL,浏览器便会执行onerror属性中设置的JavaScript代码。
③CSRF攻击#
CSRF(Cross Site Request Forgery,跨站请求伪造)是一种近年来才逐渐被大众了解的网络攻击方式,又被称为One-Click Attack或SessionRiding。在OWASP上一次(2013)的TOP 10 Web程序安全风险中,它位列第8。随着大部分程序的完善,各种框架都内置了对CSRF保护的支持,但目前仍有5%的程序受到威胁。
a.攻击原理
CSRF攻击的大致方式如下:某用户登录了A网站,认证信息保存在cookie中。当用户访问攻击者创建的B网站时,攻击者通过在B网站发送一个伪造的请求提交到A网站服务器上,让A网站服务器误以为请求来自于自己的网站,于是执行相应的操作,该用户的信息便遭到了篡改。总结起来就是,攻击者利用用户在浏览器中保存的认证信息,向对应的站点发送伪造请求。在前面学习cookie时,我们介绍过用户认证通过保存在cookie中的数据实现。在发送请求时,只要浏览器中保存了对应的cookie,服务器端就会认为用户已经处于登录状态,而攻击者正是利用了这一机制。
b.攻击示例
假设网站是一个社交网站(example.com),简称网站A;攻击者的网站可以是任意类型的网站,简称网站B。在我们的网站中,删除账户的操作通过GET请求执行,由使用下面的delete_account视图处理:
@app.route('/account/delete')
def delete_account():
if not current_user.authenticated:
abort(401)
current_user.delete()
return 'Deleted!'
当用户登录后,只要访问http://example.com/account/delete就会删除账户。那么在攻击者的网站上,只需要创建一个显示图片的img标签,其中的src属性加入删除账户的URL:
<img src="http://example.com/account/delete">
当用户访问B网站时,浏览器在解析网页时会自动向img标签的src属性中的地址发起请求。此时在A网站的登录信息保存在cookie中,因此,仅仅是访问B网站的页面就会让账户被删除掉。当然,现实中很少有网站会使用GET请求来执行包含数据更改的敏感操作,这里只是一个示例。现在,假设吸取了教训,改用POST请求提交删除账户的请求。尽管如此,攻击者只需要在B网站中内嵌一个隐藏表单,然后设置在页面加载后执行提交表单的JavaScript函数,攻击仍然会在用户访问B网站时发起。虽然CSRF攻击看起来非常可怕,但仍然可以采取一些措施来进行防御。
c.主要防范方法
- 正确使用HTTP方法
防范CSRF的基础就是正确使用HTTP方法。在前面介绍过HTTP中的常用方法。在普通的Web程序中,一般只会使用到GET和POST方法。而且,目前在HTML中仅支持GET和POST方法(借助AJAX则可以使用其他方法)。在使用HTTP方法时,通常应该遵循下面的原则:
·GET方法属于安全方法,不会改变资源状态,仅用于获取资源, 因此又被称为幂等方法。页面中所有可以通过链接发起的请求都属于GET请求。
·POST方法用于创建、修改和删除资源。在HTML中使用form标签创建表单并设置提交方法为POST,在提交时会创建POST请求。
在GET请求中,查询参数用来传入过滤返回的资源,但是在某些特殊情况下,也可以通过查询参数传递少量非敏感信息。虽然在实际开发中,通过在“删除”按钮中加入链接来删除资源非常方便,但安全问题应该作为编写代码时的第一考量,应该将这些按钮内嵌在使用了POST方法的form元素中。正确使用HTTP方法后,攻击者就无法通过GET请求来修改用户的数据。
- CSRF令牌校验
当处理非GET请求时,要想避免CSRF攻击,关键在于判断请求是否来自自己的网站。在前面我们曾经介绍过使用HTTP referer获取请求来源,理论上说,通过referer可以判断源站点从而避免CSRF攻击,但因为referer很容易被修改和伪造,所以不能作为主要的防御措施。除了在表单中加入验证码外,一般的做法是通过在客户端页面中加入伪随机数来防御CSRF攻击,这个伪随机数通常被称为CSRF令牌。附注在计算机语境中,令牌指用于标记、验证和传递信息的字符,通常是通过一定算法生成的伪随机数。在HTML中,POST方法的请求通过表单创建。把在服务器端创建的伪随机数(CSRF令牌)添加到表单中的隐藏字段里和session变量(即签名cookie)中,当用户提交表单时,这个令牌会和表单数据一起提交。在服务器端处理POST请求时,会对表单中的令牌值进行验证,如果表单中的令牌值和session中的令牌值相同,那么就说明请求发自自己的网站。因为CSRF令牌在用户向包含表单的页面发起GET请求时创建,并且在一定时间内过期,一般情况下攻击者无法获取到这个令牌值,所以可以有效地区分出请求的来源是否安全。
对于AJAX请求,可以在
XMLHttpRequest请求首部添加一个自定义字段X-CSRFToken来保存CSRF令牌。通常会使用扩展实现CSRF令牌的创建和验证工作,比如Flask- SeaSurf点击跳转、Flask-WTF内置的CSRFProtect等
除了这几个攻击方式外,还有很多安全问题要注意。比如文件上传漏洞、敏感数据存储、用户认证与权限管理等。
作者:ChanceySolo
出处:https://www.cnblogs.com/chancey/p/17570065.html
版权:本作品采用「ChanceySolo-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?