正则表达式
正则表达式
一、背景
- 文本处理已经能称为计算机常见工作之一
- 对文本内容的搜索、定位、提取是逻辑比较复杂的
- 为了快速方便的解决上述问题,产生了正则表达式
二、简介
1. 定义
即文本的高级匹配模式,提供搜索、替换等功能。其本质是由一系列字符串和特殊符号构成的字符串,这个字符串即正则表达式
2. 原理
通过特殊的符号去描述字符的组成规则,比如重复、位置等,来表达一类字符串,进而匹配
三、 元字符
每个普通字符匹配其对应字符
>>> import re
>>> re.findall("a","abcdefg")
['a']
>>> d = re.findall("你好","你好,成都,北京,上海,深圳")
>>> print(d)
['\xe4\xbd\xa0\xe5\xa5\xbd']
1 或
元字符: |
规则:匹配|两侧任意正则表达式规则
>>> re.findall("com|cn","xxx.com,xxxxxx.cn")
['com', 'cn']
>>> re.findall("ab|bc","abcdef") # 当出现这种重叠的匹配,则取前边的
['ab']
2 匹配单个
元字符:.
匹配规则:匹配除换行外任意一个字符
>>> re.findall("a.c","abcdef")
['abc']
>>> re.findall("f..","foo,f12,a12")
['foo', 'f12']
3 匹配集
元字符:[字符集]
规则:匹配字符集中任意一个字符
>>> re.findall("[f1]","foo,f12,a12")
['f', 'f', '1', '1']
[]的字符表示很多个字符
[abc#!你好]匹配其中任意一个
[0-9][a-z][A-Z]匹配区间内任意一个
[_#?0-9a-z]混合书写(区间字符写后边,单个写前边)
>>> re.findall("[aeiou]","hello world !!!")
['e', 'o', 'o']
>>> re.findall("[0-3a-m]","123456789 hello world !!!")
['1', '2', '3', 'h', 'e', 'l', 'l', 'l', 'd']
4 匹配取反
元字符:[^字符集]
匹配规则:匹配除了字符集以外的所有字符
>>> re.findall("[^0-3]","123456789 hello world !!!")
['4', '5', '6', '7', '8', '9', ' ', 'h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd', ' ', '!', '!', '!']
>>> re.findall("[^0-3a-zA-Z]","123456789 hello world !!!")
['4', '5', '6', '7', '8', '9', ' ', ' ', ' ', '!', '!', '!']
5 匹配开始
元字符:^
规则:匹配字符串的开始位置
>>> re.findall("^hello","123456789 hello world !!!")
[]
>>> re.findall("^hello","hello world !!!")
['hello']
6 匹配结束
元字符:$
规则:匹配匹配目标字符串结束位置
>>> re.findall("!$","hello world !!!")
['!']
使用技巧
^``$表示开头结尾位置,这两个元字符一定在正则表达式开头和结尾处
7 匹配重复
元字符:*
规则:匹配前边的字符出现0次或者多次
>>> re.findall("he*","hello world !!! h")
['he', 'h']
>>> re.findall("[A-Z][a-z]*","Hello World !!!")
['Hello', 'World']
只作用于符号前边的单个字符
元字符:+
规则:匹配前边的字符出现一次或多次
>>> re.findall("wo+","woooooooo~~w!")
['woooooooo']
至少要有一个符号前边的字符
元字符:?
规则:匹配前边的字符出现0次或者1次
>>> re.findall("-?[1-9][0-9]*","age:19,sorces:-60") # 匹配整数
['19', '-60']
元字符:{n}
规则:匹配前边的字符出现n次
>>> re.findall("1[0-9]{10}","tel:12389454930") # 匹配电话号码
['12389454930']
元字符:{m,n}
规则:匹配前边的字符出现m到n次
>>> re.findall("[1-9][0-9]{5,10}","QQ:943870322") # 匹配QQ号码
['943870322']
8 匹配任意(非)数字
元字符:\d``\D
规则:\d匹配任意数字 [0-9]
\D 匹配任意非数字 [^0-9]
>>> re.findall("\d{1,5}","mysql:3306,mongo:27017")
['3306', '27017']
>>> re.findall("\D{1,5}","mysql:3306,mongo:27017")
['mysql', ':', ',mong', 'o:']
9 匹配任意(非)普通字符
元字符:\w``\W
规则:\w 匹配普通字符
\W 匹配非普通字符
普通字符指数字、字母、下划线、汉字等
>>> re.findall("\w+","addr=('127.0.0.1',8888)")
['addr', '127', '0', '0', '1', '8888']
>>> re.findall("\W+","addr=('127.0.0.1',8888)")
["=('", '.', '.', '.', "',", ')']
10 匹配任意(非)空字符
元字符: \s``\S
规则:\s 匹配任意空字符
\S匹配任意非空字符
说明:
空字符指:
空格 \r \n \t \v \f(分别为空格、回车、换行、水平制表符、垂直制表符、翻页符)
>>> re.findall("\w+ \w+","hello world")
['hello world']
>>> re.findall("\w+ \w+","hello world")
[]
>>> re.findall("\w+\s+\w+","hello world")
['hello world']
>>> re.findall("\S+","hello world")
['hello', 'world']
11 匹配开头结尾位置
元字符:\A``\Z
规则:\A=^ ; \Z=$
作用等同于以上元字符
>>> re.findall("\A\w+\Z","helloworld")
['helloworld']
>>> re.findall("^\w+$","helloworld")
['helloworld']
使用技巧
如果正则表达式中同时出现
^、$,则两者之间的正则表达式需要将目标字符串内容全部匹配(fullmatch)
12 匹配单词(非)边界
元字符: \b \B
规则: \b 匹配单词边界
\B 匹配非单词边界
说明
单词边界指普通字符(
\w代表的字符)与其他字符的交界位置
>>> re.findall("is","this is a test")
['is', 'is']
>>> re.findall(r"\bis\b","this is a test")
['is']
>>> re.findall(r"\Bis\b","this is a test")
['is']
>>> re.findall(r"-?\b[1-9][0-9]","age:18,scores:-68,0000045")
['18', '-68']
13 总结
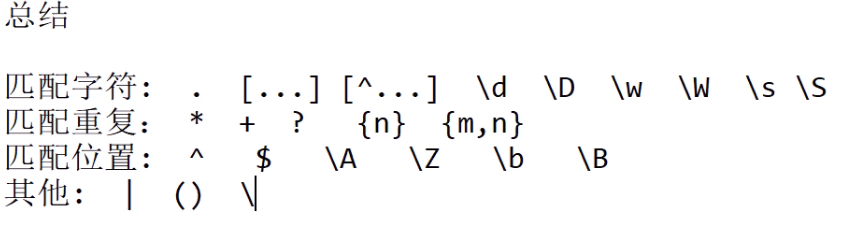
四、 转义
1.\
如果使用正则表达式匹配特殊字符,需要加\表示转义
特殊字符:
.,*,+,?,^,$,[],{},(),|,\
>>> re.findall(r"-?\d+\.?\d*","12,-45,12.34,-12.34")
['12', '-45', '12.34', '-12.34']
>>> re.findall(r"\$\d+","$100")
['$100']
>>> re.findall("\\$\\d+","$100") # python 字符串
['$100']
2.raw字符串
概述:在字符串前边加r,表示该字符串不会进行转义处理
>>> re.findall(r"\bis\b","This is a test")
['is']
五、贪婪&非贪婪
1. 贪婪模式
默认情况下,匹配重复的元字符总是尽可能多的向后匹配更多的内容
比如:*``+``?``{m,n}
>>> re.findall(r"ab*?","abbbbbbbbbbbbbbbbbbbbbbbb")
['a']
>>> re.findall(r"ab+?","abbbbbbbbbbbbbbbbbbbbbbbb")
['ab']
>>> re.findall(r"ab??","abbbbbbbbbbbbbbbbbbbbbbbb")
['a']
>>> re.findall(r"ab{3,5}?","abbbbbbbbbbbbbbbbbbbbbbbb")
['abbb']
2. 非贪婪模式
也叫懒惰模式,让重复的元字符尽可能少的匹配
*-->*?
+-->+?
?-->??
{m,n}-->{m,n}?
re.findall(r"\(.+\)","(李-白),(杜-甫),(白 居 易)") # 贪婪匹配
re.findall(r"\(.+\)?","(李-白),(杜-甫),(白 居 易)") # 懒惰匹配
六、正则表达式分组
1. 概述
在正则表达式中,以()建立正则表达式内部分组。子组时正则表达式的一部分,可作为内部整体操作。
2.作用
作为内部整体,改变元字符的操作对象
re.search(r"王|李\w{1,3}","李云龙").group()
# 以上的正则并不会匹配李,做分组即可
re.search(r"(王|李)\w{1,3}","李云龙、王力宏").group()
每个子组对应一个原组
3.捕获组
给正则表达式子组起一个名字,表达一定的意义,该组就是捕获组
格式:(?p<name>pattern)
re.search(r"(?P<first_name>王|李)\w{1,3}","李云龙、王力宏").group()
注意事项
- 一个正则表达式中可以有多个分组
- 子组可以嵌套
- 子组顺序一般由内到外、从左到右
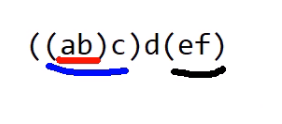
以上图中,
ab为第一组,abc为第二组,ef为第三组
s =re.findall(r"\d{17}(x|\d)","72882119923299920x,725621199232989201asx738821199232439201").group()
七、正则表达式原则
1. 正确性
能够正确的匹配出目标字符串
2. 排他性
除了目标字符串之外,尽可能不匹配其他字符串
3. 全面性
尽可能的考虑目标字符串的所有情况,不遗漏
八、RE模块
1. compile
regex = re.compile(pattern,flags = 0)
功能:生成正则表达式对象
参数:正则表达式,功能扩展标志位(在原有匹配规则上添加新的功能)
返回值:正则表达式对象
2. findall
l = re.findall(pattern,string,flags=0)
功能:通过正则匹配目标字符串
参数:正则、目标字符串、功能扩展标志位
返回值:由匹配结果组成的列表
l = re.findall(string,pos,endpos)
功能:通过正则匹配目标字符串
参数:目标字符串、截取目标字符串的开始位置、截取目标字符串的末尾位置
返回值:返回匹配到的内容列表,如果正则中有子组,则列表中元素为子组对应内容
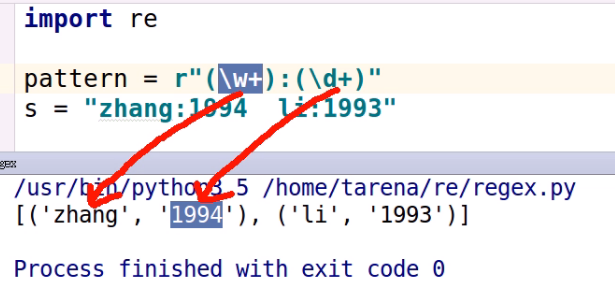
pattern = r'(\w+):(\d+)'
s = 'zhang:1994 li:1993'
# re模块调用
l = re.findall(pattern,s)
print(l)
# regex调用
regex = re.compile(pattern)
l = regex.findall(s,pos=0,endpos=13)
print(l)
3. split
re.split(pattern,string,flags=0)
功能:通过正则匹配目标字符串
参数:目标字符串、目标字符串、功能扩展标志位
返回值:返回切割后的内容列表
# 分割字符串
l = re.split(f'/s+',"hello world") # \s+ 匹配任意空格
print(l)
4. sub
re.sub(pattern,rel,string,count,flags=0)
功能:使用指定的字符串替换匹配到的内容
参数:正则、指定字符串、目标字符串、替换多少处,默认替换全部
返回值:返回替换后的字符串
# 替换
s = re.sub(r'垃圾','**','玩的真的垃圾,你真是个垃圾')
print(s)

pattern = r'\d+'
s = "2019/7/31,观世音菩萨成道200年"
it = re.finditer(pattern,s)
# print(dir(next(it)))
for i in it:
print(i.group())
5. fullmatch
re.fullmatch(pattern,string,flags=0)
功能:通过正则匹配目标字符串的全部内容
参数:正则、目标字符串、功能扩展标志位
返回值:返回匹配内容的match对象
# 完全匹配目标字符串内容
obj = re.fullmatch(r"\w+","J_bob")
print(obj.group())
6. match
re.match(pattern,string,flags=0)
功能:通过正则匹配目标字符串的全部内容
参数:正则、目标字符串、功能扩展标志位
返回值:返回匹配内容的match对象
只能匹配开始的内容
等同于加上
^
# 匹配目标字符串开始位置
obj = re.match(r"[A-Z]\w+","Hello World")
print(obj.group())
7. search
re.search(pattern,string,flags=0)
功能:通过正则匹配目标字符串的第一处内容
参数:正则、目标字符串、功能扩展标志位
返回值:返回匹配内容的match对象
# 匹配第一个字符
obj = re.match(r"[A-Z]\w+","Hello World")
print(obj.group())
obj = re.search(r'\d+',s)
print(obj.group())
九、对象属性
1. regex对象属性
- flags:flags标志位置
- pattern:正则
- groups:子组数量
- groupindex:捕获组与组序列号形成的字典
regex = re.compile(r"(ab)cd(?P<pig>)",flags=re.I)
print(regex.flags)
print(regex.pattern)
print(regex.groups)
print(regex.groupindex)
2. mtach对象属性
2.1 属性变量
pos
endpos
re
string
lastgroup
lastindex
2.2属性方法
start() 获取匹配内容开始的位置
end() 获取匹配内容结束的位置
span() 获取匹配内容起止的位置
gourpdict() 获取捕获组组名称和对应的内容字典{组名:内容}
groups() 获取子组对应的内容
group()
功能:获取match对象对应的内容
参数:默认得到全部匹配内容;组序号或者组名,则得到对应组内容
2.3 e.g.
import re
pattern = r'(ab)cd(?P<pig>ef)'
regex = re.compile(pattern)
# 获取match对象
obj = regex.search("abcdefghijklmn")
# ************ 属性变量 ************
print(obj.pos) # 匹配目标字符串开始位置
print(obj.endpos) # 目标字符串
print(obj.string) #正则表达式
print(obj.lastgroup) # 最后一组组名,没有返回None
print(obj.lastindex) # 最后一组序列号
print(obj.start()) # 获取匹配内容的开始位置
print(obj.end()) # 获取匹配内容的结束位置
print(obj.span()) # 获取匹配内容的起始位置
print(obj.groupdict()) # 获取捕获组组名称和对应的内容字典{组名:内容}
print(obj.groups()) # 获取子组对应的内容
print(obj.group())
print(obj.group(1))
print(obj.group('pig'))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号