03. 并发编程(线程)
线程编程
一、 概述
1. 定义
- 线程被称为轻量级的进程
- 线程也是多任务编程方法,可以使用计算机多核资源
- 线程是系统分配内核的最小单元
- 线程可以理解为进程中的任务分支程序
2. 特征
- 一个进程可以包含多个线程
- 线程也是一个运行过程,消耗计算机资源
- 一个进程中的所有线程共享这个进程资源
- 多个线程运行互不影响,各自执行
- 线程的创建和消耗资源远小于进程
- 线程也有自己的特有属性特征命令集、id等
二、threading模块
1. 创建线程
使用threading模块创建
1.1 步骤
from threading import Thread
(1) t = Thread()
功能:创建线程的对象
参数:target 绑定的线程函数
args 元组 给线程函数位置传参
keargs 字典 给线程函数关键字传参
(2) t.start()
功能:启动线程
(3) t.join([timeout])
功能:阻塞等待回收线程
参数:超时时间
import threading
from time import sleep
import os
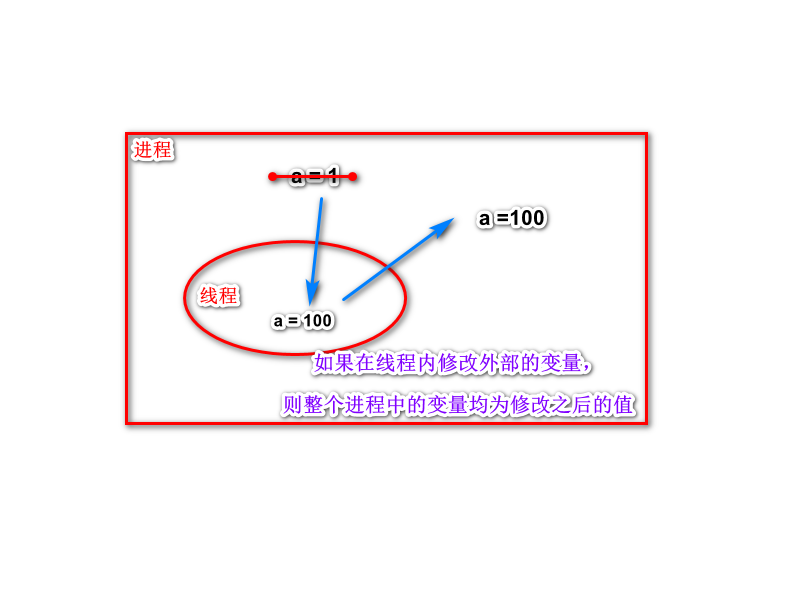
a = 1
print('a : ',a)
# 线程函数
def music():
global a
a = 10000
for i in range(5):
sleep(2)
print('命运交响曲',os.getpid())
# 创建线程对象
t = threading.Thread(target=music)
# 启动线程
t.start()
# 主线程执行
for i in range(5):
sleep(3)
print("梦中的婚礼",os.getpid())
# 释放资源
t.join()
print("a : ",a)
1.2 例如
from threading import Thread
from time import sleep
# 含有参数的线程函数
def fun(sec,name):
print("线程函数传参")
sleep(sec)
print("%s 线程执行完毕哦"%name)
# 创建多个线程
threeads = []
for i in range(5):
t = Thread(target=fun,args=(2,),kwargs={'name':"T%d"%i})
threeads.append(t)
t.start()
for i in threeads:
i.join()
2.线程对象属性
t.name 线程名称
t.setName() 设置线程名称
t.getName() 获取线程名称
t.is_alive*() 查看线程的生命周期
t.daemon 设置主线程和分支线程的退出关系
t.setDaemon()设置daemon属性值
t.isDaemon() 查看daemon属性值
设置daemon为True ,此时主线程退出分支线程也会退出,该设置在start()之前设置,且不与join()共同使用
from threading import Thread
from time import sleep
def fun():
sleep(3)
print("线程属性测试")
t = Thread(target=fun,name="chancey")
# 设置Daemon属性值
t.setDaemon(True)
t.start()
t.setName("素心") # 设置线程名称
print("线程名称:",t.name) # 获取线程名称
print("线程名称:",t.getName()) # 获取线程名称
print("线程生命周期:",t.is_alive()) # 查看线程的生命周期
3.自定义线程类
在函数太多的情况下使用线程类。
3.1 步骤
(1) 继承Thread类
(2) 重写__init__方法添加自己的属性,执行父类的__init__
(3) 重写run方法
3.2 使用
(1) 使用自定义类实例化对象
(2) 通过对象调用start()创建进程,自动运行run
(3) 通过join回收进程
3.3 整体代码
from threading import Thread
from time import ctime,sleep
class MyThread(Thread):
def __init__(self,target,args=None,kwargs=None):
super().__init__()
self.target = target
self.args = args
self.kwargs = kwargs
def run(self):
self.target(*self.args,**self.kwargs)
def player(sec,song):
for i in range(2):
print("正在 %s : %s"%(song,ctime()))
sleep(sec)
t = MyThread(target=player,args=(3,),kwargs={'song':'凉凉'})
t.start()
t.join()
三、线程通信
1.通信方法
线程间使用全局变量进行通信
2.共享资源的争夺
共享资源:多个进程或者线程都可以操作的资源称为共享资源
影响:对共享资源的无序操作可能会带来数据的混乱或者操作错误。此时需要同步互斥机制处理
同步互斥
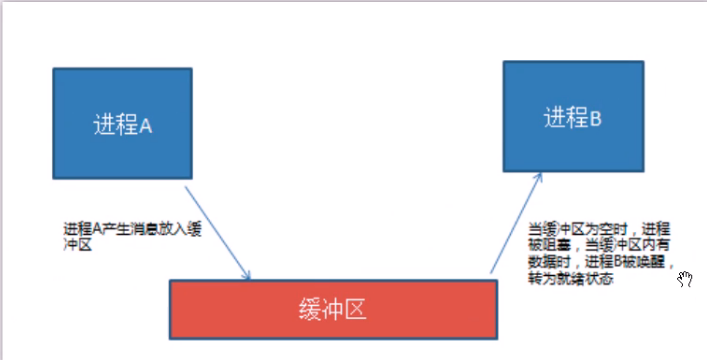
同步是一种协作关系,为完成操作,多进程或者多线程间形成一种协调,按照必要的步骤执行操作
互斥
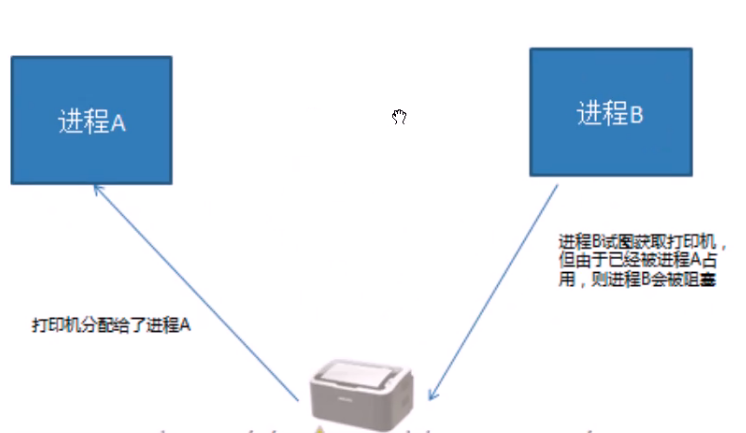
互斥是一种制约关系,当一个进程或者线程抢占到资源时进行加锁处理,其他进程就无法操作资源,知道解锁之后才能操作。
3.线程互斥方法
3.1 Event
from treading imort Event
(1)e = Event 创建event对象
(2) e.wait([timeout]) 阻塞等待直到e被set
(3) e.set() 设置e,使wait结束阻塞
(4) e.clear() 清除e设置,wait会阻塞
(5) e.is_set() 判断e的状态
3.2 Lock
from threading import Lock
(1)lock = Lock() 创建锁
(2) lock.acquire() 上锁 如果lock已经被锁会阻塞
(3) lock.realease() 解锁
from threading import Thread,Lock
a = b = 0
lock = Lock() # 创建Lock锁
def value():
while True:
if a != b:
print("a = %d,b = %d"%(a,b))
t = Thread(target=value)
t.start()
while True:
with lock: # 加锁
a += 1
b += 1
t.join()
3.3 实例
# test.py
def count(x,y):
c = 0
while c < 7000000:
x += 1
y += 1
c += 1
def io():
write()
read()
def write():
f = open('test','w')
for i in range(1700000):
f.write("hello world !!! \n")
def read():
f = open('test')
f.readline()
f.close()
# CPU密集型
from test import count,write,read
import time
t = time.time()
for i in range(10):
count(1,1)
print("single cpu:",time.time() -t)
# IO密集型
from test import count,write,read,io
import time
t = time.time()
for i in range(10):
# count(1,1)
io()
print("single cpu:",time.time() -t)
# 多线程
from test import *
import threading
import time
jobs = []
t = time.time()
for i in range(10):
th = threading.Thread(target=count,args=(1,1))
jobs.append(th)
th.start()
for i in jobs:
i.join()
print("Thread CPU :",time.time() - t)
结论:
在无阻塞的情况下,多线程程序运行效率和单线程几乎相近,而多进程可以有效的提高程序的运行效率
3.4 GIL
全局解释器锁
3.4.1 概述
由于python解释器设计加入了全局解释器锁,导致python解释器同时只能解释一个线程,大大降低了python的执行效率
导致后果:因为遇到阻塞python线程会主动让出解释器,所以python线程在高延迟,多阻塞的情况下可以提高运行效率,其他情况并不适合
GIL问题:
- 修改c解释器
- 尽量使用进程并发
- 不使用c作为解释器(java c#)
3.4.2 区别联系
- 两者都是多任务编程方式,都能使用计算机多核资源
- 进程的创建和删除消耗的计算机资源比线程多
- 进程空间独立,数据互不干扰,有专门通信方法。线程使用全局变量通信
- 一个进程包含多个线程,包含关系
- 多线程共享进程资源,对共享资源操作时往往需要同步互斥处理
- 进程线程都是运行过程的描述,有自己的属性标志
3.4.3 使用场景
- 任务场景:如果是相对独立的任务模块可能使用进程,如果是多个分支共同构成一个完整功能可使用线程
- 项目结构:多种语言实现不同任务模块可能是多进程
- 语言特点:比如java一些语言实现线程资源少效率高,python有GIL等
- 难易程度:通信难度,逻辑处理难度
4.基于threading的多线程网络并发
4.1 原理
每当客户端发起请求,就创建一个新的线程处理客户端请求,主线程循环等待其他客户端连接
4.2 步骤
- 创建监听套接字
- 循环接收客户端连接请求
- 当有新的客户端连接,创建线程处理
- 主线程继续等待其他连接
- 客户端退出,则对应的线程结束
四、集成模块线进程网络并发
1. 使用方法
import socketserver
通过模块提供的不同的类的组合,完成多线程或者多进程,TCP或者UDP的并发模型
TCPServer 创建tcp套接字
UDPServer 创建udp套接字
StreamRequestHandler 处理tcp客户端请求
DatagramRequestHandler 处理udp客户端请求
ForkingMixIn 创建多进程并发
ForkingTCPServer ForkingMixIn+TCPServer
ForkingUDPServer ForkingMixIn+UDPServer
ThreadingMixIn 创建多线程并发
ThreadingTCPServer ThreadingMixIn+TCPServer
ThreadingUDPServer ThreadingMixIn+TCPServer
2.步骤
- 创建服务器类,通过选择继承的类,决定创建tcp或者udp,多线程或者多进程的网络并发模型
- 创建请求处理类。根据服务器类型选择stream还是datagram处理类。重写handle方法,做具体的请求处理
- 通过服务器实例化对象,绑定请求处理里
- 通过服务器对象绑定对象启动服务
五、网络通信模型
1.分类
-
循环网络模型:循环接收客户端请求,处理请求,同时只能处理一个客户端请求任务,处理完再进行下一个
优点:实现简单,占用资源少
缺点:无法同时处理多个请求,效率不高
适用情况:客户端不会长期占有服务器,任务比较小,任务量不大,UDP比TCP实现更加简单
-
IO并发网络模型:利用IO多路复用等IO模型技术,同时处理多个IO任务请求
并未使用多线程或多进程。
优点:资源消耗少,能同时处理多个IO
缺点:只能处理IO操作
-
多进程/多线程并发:当一个客户端连接服务器,就创建一个新的进程/线程处理客户端请求,客户端退出时对应点的进程/县城也随之销毁
优点:同时满足多个客户端长期占有服务器需求,可以处理各种请求
缺点:资源消耗较大
使用情况:客户端请求比较复杂,处理时间比较长,配合较强的服务器部署技术(负载均衡,集群技术,分布式处理,缓存队列等)
2.多进程网络并发
基于fork的并发模型
- 创建监听字
- 循环等待客户端连接
- 有客户端创建新的进程处理客户端请求
- 远进程继续等待其他客户端连接
- 如果客户端退出,则销毁对应的进程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号