02. 并发编程(进程)
并发编程(进程)
意义
充分利用计算机资源,同时处理多个任务,提高程序的运行效率
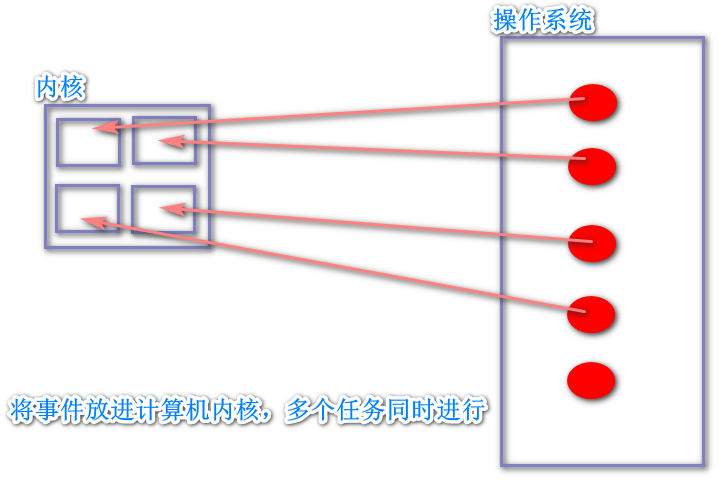
并行:多个任务利用计算机多核资源在同时进行,此时多个任务间时并行关系
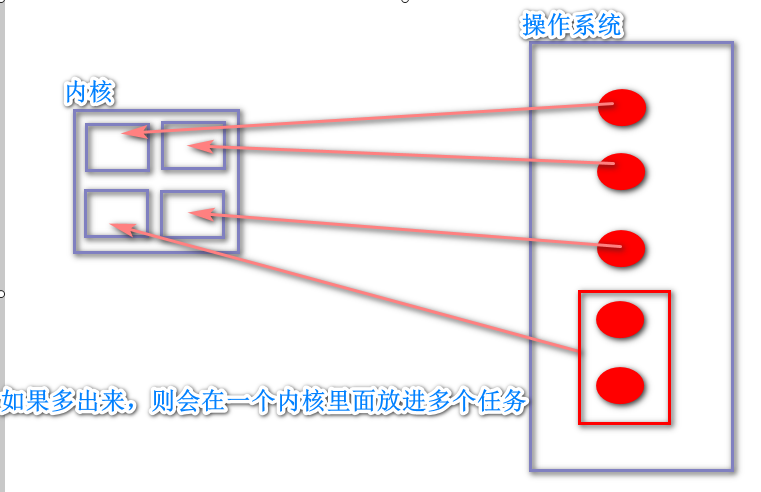
并发:同时处理多个任务,内核在任务期不断的切换达到很多任务都是被同时处理的效果,实际每个时刻只有一个任务在执行
实现方法:
多线程、多进程
一、进程
1. 定义
指的是程序在计算机中的一次运行过程
- 程序是一个可行行的文件,是静态的只占磁盘
- 进程是一个动态的过程,占有计算机运行资源,有一定的生命周期
如何产生一个进程?
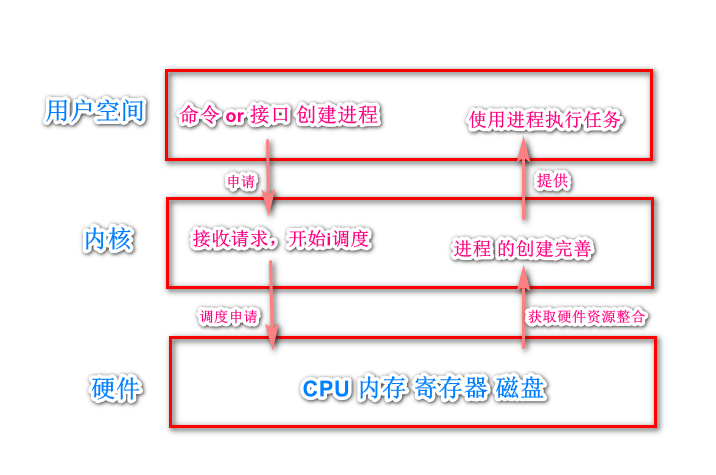
- 用户空间通过命令或者接口发起请求;
- 操作系统接收请求,开始调用系统接口创建进程;
- 操作系统调配计算机硬件资源,整合进程状态等进程创建工作;
- 操作系统将创建的进程提供给用户使用
进程概念:
- CPU时间片:如果一个进程占有CPU则称这个进程在时间片上;
- PCB(进程控制块):在内存中开辟一块新的空间,用于存放进程信息,也用于操作系统对进程的调配;
- PID:系统为每个进程分配的大于零的整数,作为进程的ID标志;
- 父子进程:系统中每一个进程(除了初始进程)都有唯一的父进程,可以有0个或者多个子进程;
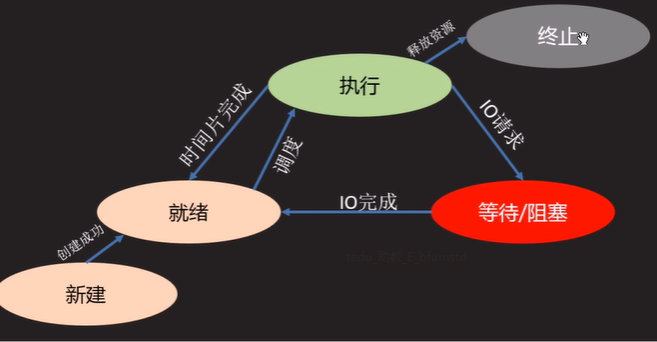
- 进程状态(三态):
- 就绪态:进程具备执行条件,等待分配CPU资源
- 运行态:进程占有CPU时间片正在运行
- 阻塞态:进程处理阻塞暂停状态,让出CPU
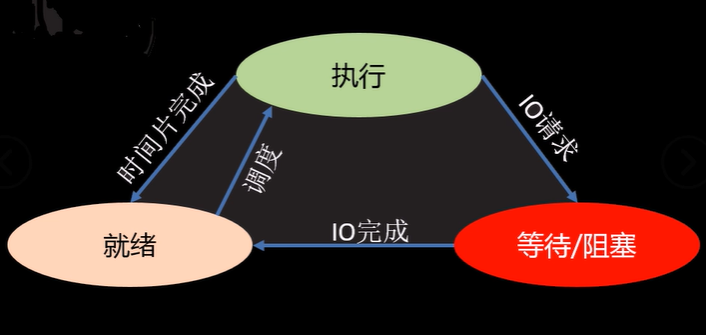
- 进程状态(五态):# 相比三态来说,五态只是多出了新建和终止
- 新建:创建进程获取资源
- 终止:进程结束释放资源
查看进程状态
ps -auxS 等待态
R 运行态
Z 僵尸
l 有多线程的
+前台进程
2.进程的运行特征
(1) 进程可以使用计算机多核资源
(2) 进程是计算机资源分配的最小单元
(3) 进程之间的运行互不影响,各自独立
(4) 每个进程拥有各自独立的空间,各自使用各自的空间内容
3. 基于fork的进程创建
pid = os.fork()
功能:创建新的进程
返回值:整数
如果创建进程失败返回一个负数;
如果成功,新进程得到0,原进程得到新进程的PID号
import os
pid = os.fork()
if pid < 0:
print('Create process faild')
elif pid == 0:
print('The new process')
else:
print("The old process")
print('Fork test over')
# 执行以上代码不难发现,用户下执行了两次命令,采用父子进程实现并发效果,并且父进程本身存在,所有操作系统优先分配资源给父进程,其实也就是看是谁抢到时间片
- 子进程会复制父进程的全部内存空间,从
fork的下一句开始执行 - 父子进程各自运行,互不影响,顺序不确定(看谁先抢到计算机资源)
- 利用父子进程中fork返回值的差异,配合if语句让父子进程执行不同的内容,几乎是固定搭配
- 父进程fork之前开辟的空间,子进程也会拥有,父子进程在各自空间操作不会相互影响
- 父子进程有各自特有的内容,PID、PCB...
4.进程相关的函数
-
os.getpid()功能:获取一个进程的PID值
返回值:返回当前进程的PID
-
os.getppid()功能:获取父进程的PID
返回值: 父进程PID
-
os._exit(status)功能:结束一个进程
参数:表示进程的结束状态(整数)
进程的结束状态
0 正常结束
-
sys.exit([status])功能:结束一个进程
参数:默认为0,整数表示退出,如果是字符则串表示退出时打印提示信息
####### os.getpid()
import os
pid = os.fork()
if pid < 0:
print("Error")
elif pid == 0:
print("Child PID",os.getpid())
else:
print("Parent PID",os.getpid())
####### os.getppid()
import os
pid = os.fork()
if pid < 0:
print("Error")
elif pid == 0:
print("Child PID",os.getpid())
print("Get parent PID",os.getppid())
else:
print("Parent PID",os.getpid())
print("Get child PID",pid)
####### os._exit(status)
import os
print("进程结束之前")
os._exit(0)
print("进程结束之后")
####### sys.exit([status])
import os,sys
sys.exit("进程退出")
print("进程结束之后")
5.孤儿和僵尸
都是负面影响的进程
5.1 孤儿进程
没有父进程的子进程
概述
父进程先于子进程退出,此时子进程为孤儿进程
当资源里面有孤儿进程的时候,操作系统就会派出一个进程,用来管理该孤儿进程,成为新的父进程
import os
from time import sleep
pid = os.fork()
if pid < 0:
print("Error")
elif pid == 0:
sleep(1)
print("Child PID",os.getpid())
print("Get parent PID",os.getppid())
else:
print("Parent PID",os.getpid())
print("Get child PID",pid)
打印出的parent和get_parent不一样,此时的get_parent是新的父进程
特点
- 孤儿进程会被系统进程收养,此时系统进程会成为孤儿进程新的父进程
- 孤儿进程退出时,系统进程会处理退出行为
5.2 僵尸进程
父进程mei'youmei
概述
子进程先于父进程退出,父进程没有处理子进程退出行为,此时子进程就会成为僵尸进程。
特点
僵尸进程虽然已经结束,但是会存留部分进程信息在内存中,大量的僵尸进程会浪费系统内存。
# 死循环,会创建很多的进程,直到宕机
import os
from time import sleep
pid = od.fork()
if pid == 0:
print("子进程:",os.getpid())
os._exit(0)
else:
print("父进程,长点心吧")
while True:
pass
处理方式
1. wait()
(1) pid,status = os.wait()
功能:阻塞等待子进程退出
返回值
- pid(退出子进程PID)
- status(子进程的退出状态)
(2) pid,status = os.waitpid()
功能:阻塞等待子进程退出
参数
pid(-1表示等待任意子进程退出,>0 表示等待指定子进程)option(0表示阻塞,os.WNOHANG表示非阻塞)
返回值
- pid 退出子进程的PID
- status 退出子进程的状态
# 用wait处理僵尸进程
import os
from time import sleep
pid = os.fork()
if pid < 0:
print("操作有误")
elif pid == 0:
sleep(3)
print("子进程%d退出"%os.getpid())
os._exit(2)
else:
pid,status = os.wait()
print("PID:",pid)
# 获取子进程退出
print("STATUS:",status)
while True:
sleep(100)
##### 第二种
import os
from time import sleep
pid = os.fork()
if pid < 0:
print("操作有误")
elif pid == 0:
sleep(3)
print("子进程%d退出"%os.getpid())
os._exit(2)
else:
#pid,status = os.wait()
pid,status = os.waitpid(-1,os.WNOHANG)
print("PID:",pid)
# 获取子进程退出
print("STATUS:",os.WEXITSTATUS(status))
while True:
sleep(100)
2.创建二级子进程
步骤
- 父进程创建子进程
wait等待回收; - 子进程创建二级子进程后退出;
- 二级子进程成为孤儿,和父进程一起完成事件
# 二级子进程处理僵尸
import os
from time import sleep
def f1():
sleep(3)
print("chancey love mary !")
def f2():
sleep(3)
print("mary very big !)
pid = os.fork()
if pid < 0:
print("操作出错“)
elif pid == 0:
p = os.fork()
if p == 0:
f1()
else:
os._exit(0) # 一级子进程退出
else:
os.wait() # 回收一级进程
3.信号处理
原理:子进程退出会发送信号给父进程,如果父进程忽略子进程信号,则系统会自动处理子进程退出
方法
import signal
signal.signal(signal.SIGCHLD,signal.SIG_IGN)
特点
- 非阻塞
- 一次使用,永久生效(可以处理所有子进程退出)
import signal
import os
# 处理子进程信号
signal.signal(signal.SIGCHLD,signal.SIG_IGN)
pid = os.fork()
if pid < 0:
pass
elif pid == 0:
print("子进程",os.getpid())
else:
while True:
pass
二、multipprocessing模块
1.创建流程
- 将需要子进程处理的事件封装为函数;
- 通过
Process类创建进程对象,关联函数; - 可以通过进程对象对进程进行属性设置;
- 通过
start启动进程; - 通过
join回收进程
2.接口使用
-
Process()功能:创建进程对象
参数:
target绑定要执行的目标函数
args元组,按照位置进行传参
kwargs字典 给target函数关键字传参 -
p.start()功能:启动进程
此时进程产生,将p绑定函数作为新进程的执行内容
-
p.join([timeout])功能:阻塞等待回收进程
参数:超时时间(可选)
multipprocessing创建进程同样是复制父进程的空间代码段,父子进程运行互不影响- 子进程只执行target绑定函数,其余均父进程执行
Process创建进程中,往往父进程只用来创建和回收进程。具体事件由子进程完成multipprocessing创建的子进程中不能使用标准输入(也就是说不能用input)
from multiprocessing import Process
from time import sleep
# 带参数的进程函数
def worker(sec,name):
for i in range(1,3):
sleep(3)
print("T AM %s"%name)
print("T AM WORKING")
p = Process(target=worker,args=(2,"Baron"),kwargs={"name" : "Baron"})
p.start()
p.join()
3.进程对象的属性
p.name*()进程名称
p.pid()进程PID号
p.is_alive()进程是否存在生命周期
p.daemon()设置父子进程的退出关系
如果将
p.daemon()属性设置为True,则父进程退出,其他进程也会退出要求必须在
start()前设置不和
join共同使用
from multiprocessing import Process
from time import ctime,sleep
def fun():
for i in range(3):
sleep(2)
print(ctime)
p = Process(target = fun)
p.daemon = True
p.start()
print("Name:",p.name)
print("PID:",p.pid)
print("alive",p.is_alive())
4.自定义进程类
4.1 编写流程
(1) 定义进程类继承Process
(2) 编写自己的__init__函数添加属性,super重新加载父类的__init__方法
(3) 重写Process中的run方法
在python中,只要函数名相同,就是重写
4.2 使用
(1) 使用自定义类实例化对象
(2) 通过对象调用start()创建进程,自动运行run
(3) 通过join回收进程
# 自定义一个简单的进程类
from multiprocessing import Process
import time
# 自定义进程类
class Clock(Process):
def __init__(self,value):
self.value = value
super().__init__()
# 重写run方法
def run(self):
for i in range(1,11):
print("当前时间为:",time.ctime())
time.sleep(self.value)
# 创建进程对象
p = Clock(2)
p.start()
p.join()
三、进程池
1. 必要性
- 进程的创建和销毁过程消耗的计算机资源较多
- 当任务量大、每个任务又小的时候,需要频繁的创建和销毁过程,对计算机压力较大
- 进程池技术很好的解决了上述问题
2. 原理
创建一定数量的进程来处理事件,事件处理完进程不退出而是继续处理其他事件,直到所有事件都处理完毕再一同销毁。增加进程的复用性,降低资源消耗
3. 步骤
from multiprocessing import Pool
(1) pool = Pool(processes)
功能:创建进程池对象
参数:指定创建进程数量,默认根据系统自动判定
(2) pool.apply_async(func,args,kwds)
功能:将进程事件加入到进程池
参数:func 进程事件函数
args 给进程事件元组传参
kwds 给进程事件字典传参
(3) pool.close
功能:关闭进程池
(4) pool.join
功能:回收进程池
from multiprocessing import Pool
from time import sleep
# 进程池事件函数
def worker(msg):
sleep(2)
print(msg)
# 创建进程池
pool = Pool()
for i in range(1,11):
msg = "hello %d"%i
pool.apply_async(func=worker,args=(msg,))
# 关闭进程池
pool.close()
# 回收进程池
pool.join()
四、进程间通信(IPC)
1. 必要性
进程空间独立,资源不会共享。此时在进程间数据传输的时候,需要一定的方法手段
2. 方法
各个系统之间都有不同的处理方法
以linux系统为例
2.1 管道通信
2.1.1 通信原理
在内存中开辟管道空间,生成管道对象,多个进程使用同一管道进行读写操作
2.1.2 步骤
from multiprocessing import Pipe
(1) fd1,fd2 = Pipe(duplex = True)
功能:创建管道
参数:默认为True(双向管道),False表示单向管道
返回值:表示管道两端读写对象
双向管道(全双工)均可读写
单向管道(半双工)fd1只读,fd2只写
(2) fd.recv()
功能:从管道读取内容
返回值:读取到的内容负
(3) fd.send(data)
功能:向管道写入内容
参数:要写入的数据
2.1.3 整体代码
'''
管道通信
父进程和子进程之间数据的交互
'''
from multiprocessing import Process,Pipe
import time,os
# 创建管道
fd1,fd2 = Pipe(True)
def fun(name):
time.sleep(3)
# 写入管道
fd1.send({name:os.getpgid()})
jobs = []
for i in range(5):
p = Process(target=fun,args=(i,))
jobs.append(p)
p.start()
for i in range(5):
# 读取管道
data = fd1.recv()
print(data)
for i in jobs:
i.join()
2.2 消息队列

2.2.1 原理
在内存中建立队列模型(在虚拟内存中建立),进程通过队列存取消息实现通信
2.2.2 实现方法
from multriprocessing import Queue
(1) a = Queue(maxsixe = 0)
功能:创建消息队列
参数:最多存放消息的个数
(2) q.put(data,[block,timeout])
功能:向队列存入消息
参数:data: 要存入的内容
block:设置阻塞(当队列满了就会发生阻塞)False为非阻塞(可选参数)
timeout:超时时间(可选参数)
(3) q.get([block,timeout])
功能:从队列中取出消息
参数:block : False 为非阻塞
timeout : 超时时间
(4) q.fill() 判断队列是否为满
(5) q.empty() 判断队列是否为空
(6) q.qsize() 获取队列中消息个数
(7) q.close() 关闭队列

2.2.3 整体代码
'''
消息队列
'''
from multiprocessing import Queue,Process
from time import sleep
# 创建消息队列
q = Queue(3)
#
def fun1():
for i in range(3):
sleep(1)
q.put((1,3))
def fun2():
for i in range(4):
try:
a,b = q.get(timeout = 3)
except:
return
print("SUM : ",a + b)
p1 = Process(target=fun1)
p2 = Process(target=fun2)
p1.start()
p2.start()
p1.join()
p2.join()
2.3 共享内存
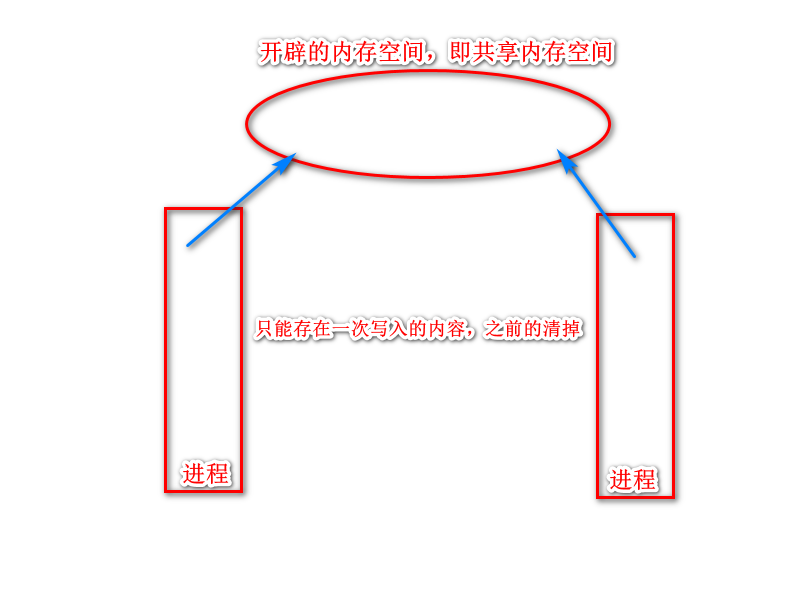
2.3.1 原理
在内存中开辟一块空间,进程可以写入和读取内容,但是每次写入内容都会覆盖之前的内容。
2.3.2 实现方法
from multiprocessing import Value,Array
(1)obj = Value(ctype,data)
功能:创建共享内存
参数:ctype 共享内存类型(i,f,c)
data 共享内存初始数据
常用:
c、i、f

(2) obj.value
对该属性修改查看(即共享内存读写)
from multiprocessing import Process,Value
import time
import random
# 创建共享内存
money = Value('i',5000)
# 操作共享内存
def man():
for i in range(30):
time.sleep(0.2)
money.value += random.randint(1,1000) # 生成随机整数
def gir():
for i in range(30):
time.sleep(0.18)
money.value -= random.randint(100,800)
m = Process(target=man)
g = Process(target=gir)
m.start()
g.start()
m.join()
g.join()
print("一个月剩余:",money.value)
(3) obj.Array(ctype,data)
功能:创建共享内存
参数:ctype 内存类型
data 列表表示共享内存初始数据,整数表示共享内存开辟数据元素的个数
(4) obj进行遍历或者索引方式获取值,也可以通过索引直接赋值
from multiprocessing import Process,Array
# 创建贡献内存
shm = Array('i',[1,2,3,4])
#
def fun():
for i in shm:
print(i,end=" ")
shm[1] = 200 # 修改内存数据
p = Process(target=fun)
p.start()
p.join()
for i in shm:
print(i,end=' ')
(5) obj.value()
用于整体打印共享内存中的字节串
2.3.3 整体代码
from multiprocessing import Process,Array
# 创建贡献内存
#shm = Array('i',[1,2,3,4]) # 开辟并写入数据列表
# shm = Array('i',5) # 开辟5个大小
shm = Array('c',b'Hello')
#
def fun():
for i in shm:
print(i)
shm[0] = b'h' # 修改内存数据
p = Process(target=fun)
p.start()
p.join()
for i in shm:
print(i,end=' ')
print(shm.value) # 专门打印字符串的函数
2.4 信号量
完全不同于管道、消息、共享内存,也叫信号灯集
2.4.1 原理
给定一个数量对多个进程可见,多个进程都可以操作数量的增减,并根据数量决定行为
2.4.2 步骤
from multiprocessing import Semaphore
(1) sem = Semaphore(num)
功能:创建信号量对象
参数:信号量对象
返回值:信号量对象
(2) sem.acquire()
功能:消耗一个信号量,当信号量为0时会阻塞
(3) sem.release() 增加一个信号量
(4) sem.get_value()获取信号量值
2.4.3 整体代码
from multiprocessing import Semaphore,Process
from time import sleep
import os
# 创建信号量
sem = Semaphore(3)
# 要求系统中最多允许3个进程同时执行该事件
def fun():
sem.acquire() # 消耗信号量
print("%d执行该事件"%os.getpid())
sleep(3)
print("%d执行结束"%os.getpid())
sem.release() # 增加信号量
jobs = []
for i in range(5):
p = Process(target = fun)
jobs.append(p)
p.start()
for i in jobs:
i.join()
print(sem.get_value()) # 打印所有的信号量
当在父进程中创建对象(文件对象、套接字对象、进程间通信对象),子进程从父进程中拷贝对象时父子进程对该对象的使用会有属性的相互影响。如果在父子进程各自创建则无影响

 浙公网安备 33010602011771号
浙公网安备 33010602011771号