7.Spark SQL
1.分析SparkSQL出现的原因,并简述SparkSQL的起源与发展。
原因:设计一个统一的计算引擎解决所有的各类型计算,包含计算类型:
1.离线批处理;
2.交互式查询
3.图计算
4.流失计算
5.机器学习/迭代计算
6.Spark R 科学计算,数据分析
Shark 建立在 Hive 代码的基础上,只修改了内存管理、物理计划、执行 3 个模块中的部分逻辑。
Shark 通过将 Hive 的部分物理执行计划交换出来(“swapping out the physical execution engine part of Hive"),
最终将 HiveQL 转换为 Spark 的计算模型,使之能运行在 Spark 引擎上,从而使得 SQL 査询的速度得到 10 ~ 100 倍的提升。
此外, Shark 的最大特性是与 Hive 完全兼容,并且支持用户编写机器学习或数据处理函数,对 HiveQL 执行结果进行进一步分析。
2. 简述RDD 和DataFrame的联系与区别。
DataFrame被称为SchemaRDD。DataFrame使Spark具备了处理大规模结构化数据的能力。在Spark中,DataFrame是一种以RDD为基础的分布式数据集,因此DataFrame可以完成RDD的绝大多数功能,在开发使用时,也可以调用方法将RDD和DataFrame进行相互转换。DataFrame的结构类似于传统数据库的二维表格,并且可以从很多数据源中创建,例如结构化文件、外部数据库、Hive表等数据源。
3.DataFrame创建
spark.read.text("file:///home/hadoop/people.txt").show()
spark.read.json("file:///home/hadoop/people.json").show()
spark.read.format("text").load("file:///home/hadoop/people.txt").show()
spark.read.format("json").load("file:///home/hadoop/people.json").show()
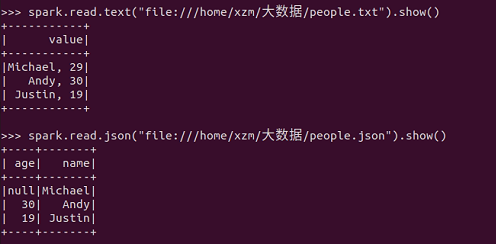
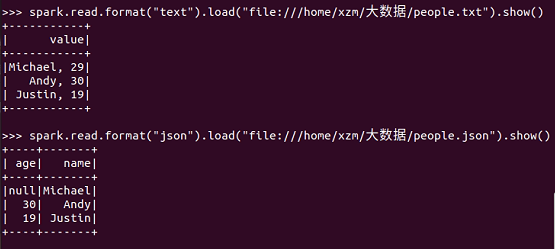
描述从不同文件类型生成DataFrame的区别。
用相同的txt或json文件,同时创建RDD,比较RDD与DataFrame的区别。
同时创建RDD
sc.textFile("file:///home/hadoop/people.txt").collect()
sc.textFile("file:///home/hadoop/people.json").collect()

3.2 DataFrame的保存
df.write.text(dir)
df.write.json(dri)
df.write.format("text").save(dir)
df.write.format("json").save(dir)
df.write.format("json").save(dir)

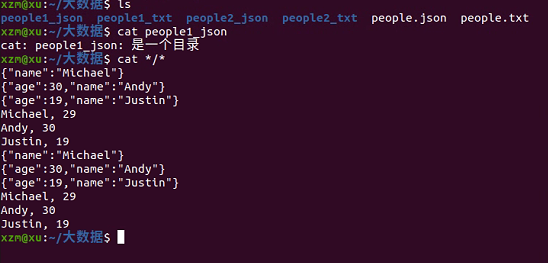
4.选择题:
-
1单选(2分)关于Shark,下面描述正确的是:C
A.Shark提供了类似Pig的功能
B.Shark把SQL语句转换成MapReduce作业
C.Shark重用了Hive中的HiveQL解析、逻辑执行计划翻译、执行计划优化等逻辑
D.Shark的性能比Hive差很多 -
2单选(2分)下面关于Spark SQL架构的描述错误的是:D
A.在Shark原有的架构上重写了逻辑执行计划的优化部分,解决了Shark存在的问题
B.Spark SQL在Hive兼容层面仅依赖HiveQL解析和Hive元数据
C.Spark SQL执行计划生成和优化都由Catalyst(函数式关系查询优化框架)负责
D.Spark SQL执行计划生成和优化需要依赖Hive来完成 -
3单选(2分)要把一个DataFrame保存到people.json文件中,下面语句哪个是正确的:A
A.df.write.json("people.json")
B.df.json("people.json")
C.df.write.format("csv").save("people.json")
D.df.write.csv("people.json") -
4多选(3分)Shark的设计导致了两个问题:AC
A.执行计划优化完全依赖于Hive,不方便添加新的优化策略
B.执行计划优化不依赖于Hive,方便添加新的优化策略
C.Spark是线程级并行,而MapReduce是进程级并行,因此,Spark在兼容Hive的实现上存在线程安全问题,导致Shark不得不使用另外一套独立维护的、打了补丁的Hive源码分支
D.Spark是进程级并行,而MapReduce是线程级并行,因此,Spark在兼容Hive的实现上存在线程安全问题,导致Shark不得不使用另外一套独立维护的、打了补丁的Hive源码分支 -
5 多选(3分)下面关于为什么推出Spark SQL的原因的描述正确的是:AB
A.Spark SQL可以提供DataFrame API,可以对内部和外部各种数据源执行各种关系操作
B.可以支持大量的数据源和数据分析算法,组合使用Spark SQL和Spark MLlib,可以融合传统关系数据库的结构化数据管理能力和机器学习算法的数据处理能力
C.Spark SQL无法对各种不同的数据源进行整合
D.Spark SQL无法融合结构化数据管理能力和机器学习算法的数据处理能力 -
6多选(3分)下面关于DataFrame的描述正确的是:ABCD
A.DataFrame的推出,让Spark具备了处理大规模结构化数据的能力
B.DataFrame比原有的RDD转化方式更加简单易用,而且获得了更高的计算性能
C.Spark能够轻松实现从MySQL到DataFrame的转化,并且支持SQL查询
D.DataFrame是一种以RDD为基础的分布式数据集,提供了详细的结构信息 -
7多选(3分)要读取people.json文件生成DataFrame,可以使用下面哪些命令:AC
A.spark.read.json("people.json")
B.spark.read.parquet("people.json")
C.spark.read.format("json").load("people.json")
D.spark.read.format("csv").load("people.json") -
8单选(2分)以下操作中,哪个不是DataFrame的常用操作:D
A.printSchema()
B.select()
C.filter()
D.sendto() -
9多选(3分)从RDD转换得到DataFrame包含两种典型方法,分别是:AB
A.利用反射机制推断RDD模式
B.使用编程方式定义RDD模式
C.利用投影机制推断RDD模式
D.利用互联机制推断RDD模式 -
10多选(3分)使用编程方式定义RDD模式时,主要包括哪三个步骤:ABD
A.制作“表头”
B.制作“表中的记录”
C.制作映射表
D.把“表头”和“表中的记录”拼装在一起

 浙公网安备 33010602011771号
浙公网安备 33010602011771号