
1、背景
1993年,Agrawal提出了关联规则(Association Rule)问题,旨在发现顾客购货篮内商品间令人感兴趣的关系。
“啤酒和尿布” 沃尔玛利用NCR数据挖掘工具意外的发现:跟尿布一起购买最多的商品竟是啤酒!
今天,关联规则已广泛应用于金融、营销以及生物信息学等领域。
2、概念
1)基本概念:
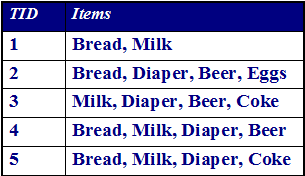
项集:一个或多个项目的集合。 例如: {Milk, Bread, Diaper} ,包含k 个项目的项集称为k-项集
绝对支持度 (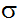 ):某一项集出现的次数。 比如 ({Milk, Bread,Diaper}) = 2
):某一项集出现的次数。 比如 ({Milk, Bread,Diaper}) = 2
相对支持度(s): 包含某一项集的事务在全体事务中的比例。比如. s({Milk, Bread, Diaper}) = 2/5
频繁项集: 支持度不小于给定最小支持度阈值(minsup)的项集
2)关联规则
(1)关联规则:寻找给定的数据集中项目之间令人感兴趣的关系
形如 X ![]() Y的蕴涵式, 其中 X 和Y是项集,且X
Y的蕴涵式, 其中 X 和Y是项集,且X![]() Y=
Y=![]() 。 比如: {Milk, Diaper}
。 比如: {Milk, Diaper}![]() {Beer}
{Beer}
3)规则评价参数
支持度 (s) 同时包含X和Y的事务占全部事务的百分比
可信度 (c) 包含项集X的事务中也包含Y的百分比

4)关联规则挖掘的一般流程
- 找出满足最小支持度阈值的所有频繁项集。
- 由频繁项集产生满足最小可信度阈值的强关联规则。
- 这两步中,第二步较容易。关联规则挖掘的总体性能由第一步决定。
3、算法
1)Apriori算法
其核心是基于两阶段频繁项集思想的递推算法。第一步,简单统计所有含一个元素项集出现的频数,并找出那些不小于最小支持度的项集,即一维最大项集。第二步,从第二步开始循环处理直到再没有最大项集生成,循环过程:第k步中,根据第k-1步生成(k-1)维最大项集产生k维候选项集,然后对数据库进行搜索,得到候选项集的支持度,与最小支持度进行比较,从而找到k为最大项集。
2)FP-Growth算法
3)复杂关联规则挖掘
序列模式挖掘
频繁子图挖掘

 浙公网安备 33010602011771号
浙公网安备 33010602011771号