


不知道大家有没有过这个疑问,为什么网易云的算法推荐做的那么令人惊喜? 关于这个问题我也想过,为什么网易云可以做的这么好,推荐的这么到位,他们的算法团队是如何去描述一个首歌,描述一个用户的。点进这个问题后,我看了当时排名第一的回答,答主介绍了一个算法,“潜在因子(Latent Factor)”。看完这个算法让我对算法这个逻辑玩具,有了一些新的体会。
这里我尝试描述一下这个“潜在因子(Latent Factor)”算法,就用人大高材生 nick lee 的例子来说明吧:
这里假设我们又三个用户分别为: 张三、李四、王五; 有音乐类别:小清新、重口味、优雅、伤感、五月天;并且有四个音乐:音乐A、音乐B、音乐C。我们可以先构造一下矩阵:
一、用户-潜在因子矩阵Q,表示不同的用户对于不用元素的偏好程度,1代表很喜欢,0代表不喜欢。比如下面这样:

二、潜在因子-音乐矩阵P,表示每种音乐含有各种元素的成分,比如下表中,音乐A是一个偏小清新的音乐,含有小清新这个Latent Factor的成分是0.9,重口味的成分是0.1,优雅的成分是0.2……

利用这两个矩阵,我们能得出张三对音乐A的喜欢程度是:张三对小清新的偏好*音乐A含有小清新的成分+对重口味的偏好*音乐A含有重口味的成分+对优雅的偏好*音乐A含有优雅的成分+……


即:0.6*0.9+0.8*0.1+0.1*0.2+0.1*0.4+0.7*0=0.69
每个用户对每首歌都这样计算可以得到不同用户对不同歌曲的评分矩阵。(注,这里的破浪线表示的是估计的评分,接下来我们还会用到不带波浪线的R表示实际的评分):
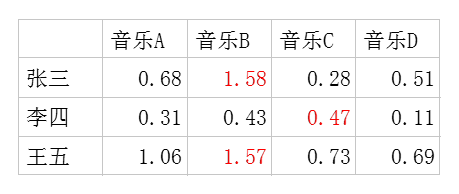
因此我们队张三推荐四首歌中得分最高的B,对李四推荐得分最高的C,王五推荐B。
如果用矩阵表示即为:
下面问题来了,这个潜在因子(latent factor)是怎么得到的呢?
由于面对海量的让用户自己给音乐分类并告诉我们自己的偏好系数显然是不现实的,事实上我们能获得的数据只有用户行为数据。我们沿用 邰原朗的量化标准:单曲循环=5, 分享=4, 收藏=3, 主动播放=2 , 听完=1, 跳过=-2 , 拉黑=-5,在分析时能获得的实际评分矩阵R,也就是输入矩阵大概是这个样子:

事实上这是个非常非常稀疏的矩阵,因为大部分用户只听过全部音乐中很少一部分。如何利用这个矩阵去找潜在因子呢?这里主要应用到的是矩阵的UV分解。也就是将上面的评分矩阵分解为两个低维度的矩阵,用Q和P两个矩阵的乘积去估计实际的评分矩阵,而且我们希望估计的评分矩阵

图:UV分解
和实际的评分矩阵不要相差太多,也就是求解下面的目标函数:
这里涉及到最优化理论,在实际应用中,往往还要在后面加上2范数的罚项,然后利用梯度下降法就可以求得这P,Q两个矩阵的估计值。这里我们就不展开说了。例如我们上面给出的那个例子可以分解成为这样两个矩阵:

这两个矩阵相乘就可以得到估计的得分矩阵:

将用户已经听过的音乐剔除后,选择分数最高音乐的推荐给用户即可(红体字)。
在这个例子里面用户7和用户8有强的相似性:

从推荐的结果来看,正好推荐的是对方评分较高的音乐:

以上就是潜在因子算法的例子,再次感谢 nick lee 。
为什么我会写这篇博客呢?
因为看到这个回答的时候,我想到了我大一时做数学建模竞赛时的场景,当时也是两个人每天没日没夜的去研究如何给那个问题建模,建模后如何用可实现的方法得到模型中需要的数据。其实现在回头看看对一个问题进行建模时,在我们确定好问题的求解要求,也就是目标后。会分为两种人:
一种是先找找到一个模型的解法,然后把问题套到模型中,因为该模型已经在细节上有了很好的处理,这个时候只需要跑这个模型去验证。
另一种是确定出对问题描述最后的参数,然后去根据这些参数去建立模型,但是这些参数的产生并没有现成的方法来获得,这个的时候就需要我们自己去寻找得到这个参数的方法,正如 "潜在因子" 算法中的对歌曲的描述,从 “图UV分解” 中我们可以看到,这个模型中其实并没有真正的小清新、五月天这种分类,“图UV分解”中的factor在这个解决方法中是可变的。
所以通过以上分析,面对网易云音乐的推荐分析,如果采用潜在因子算法,那么这个流程是这样的:
我们构想了一个模型,User对对不同种类的音乐的喜爱程度,Music中这些种类的元素程度,通过这两个数据的收集,可以求出特定的User对一首特定的Music的喜爱程度,然后就可以按照这个结果对User进行推荐了;这样分析下去,我们首先想到的就是如何对Music进行分类,如何确定分类最好,结果这里的这个算法,并没有去实现对音乐进行分类,而是通过用户听歌时的操作,我们可以假设这个操作来源于私人FM,通过这个FM我们能得到用户对听过歌曲的操作:单曲循环, 分享, 收藏, 主动播放 , 听完, 跳过 , 拉黑,我们对这些操作进行评分:单曲循环=5, 分享=4, 收藏=3, 主动播放=2 , 听完=1, 跳过=-2 , 拉黑=-5。然后得到User对每一首歌的一个基本喜好程度,但是仅根据这些数据我们依然,不能对歌曲进行推荐,因为我们只得到了该User对已听过歌曲的喜好,对没有听过的歌曲我们一无所知。但是通过UV分解我们去可以得到一个factor,这个factor就把User和Music联系起来的,无论是听过的还是没有听过的。所这个模型在技术上的处理就只有UV分解了。
那么为什么要说是 “从网易云音乐到算法体会” ? 其实是在这个里面有很多是编程人员要做到的。
首先用户数量是很大的,歌曲数量也是很大的,那么User对Music操作的那个矩阵就会是一个很大的矩阵,而且考虑到每个User听歌量的大小相对于曲库的数量是很小的,所以这个矩阵一定是一个相当稀疏的稀疏矩阵,那么稀疏矩阵的各种操作这个时候就派上用场了,这时闯入开发人员脑子里的就是矩阵的稀疏表示,稀疏矩阵的转置,稀疏矩阵的加减乘除,UV分解等算法。我在做大创时,看到prince算法,也就是一个基因预测算法,我当时无论是在编写这个算法,还是在编写排序分算法的时候,都没有感受到有什么难度存在,当时就是觉得:咦,这些被引用了这么多遍的论文,经典算法为什么会如此简单,在我看来他们不就是简单的统计学么,然后再通过图型分析结果嘛,好看的就是好的算法,不好的就是不好的算法。当时觉得那些算法并没有什么“牛逼”的地方,Dijkstra's Algorithm不知道比你们高到哪里去了。我所谓的搞研究难道就是为那些统计学家编写这些低级的算法吗?ACM都不知道比你们有挑战性到哪里去了。但是现在我理解了,我作为一个程序员或与那不是我该和那些科学家去比较的地方,我应该做的是完成一个智能的系统,不在需要想我一样的“码畜”写那些低级的统计代码(其实也不是很低级,有些还是很难的,嘿嘿),这个系统才是我们程序员的努力方向。
当然正如上次有幸得到阿里中间件的大触的指引说的其实程序员最后的发展并不是技术水平,编写代码的水平而是对sense。现在我对这个sense的理解就是这个问题值不值得我把它抽象出来,值不值得我为他写个智能的系统(可以这么说网易云的推荐系统才是这个产品的核心)。
望自己在这条路上走出一番天地!

