sklearn.linear_model.LogisticRegression-逻辑回归分类器
参考:https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
在了解逻辑回归原理(见逻辑回归原理总结)的基础上,进一步对sklearn库中的LogisticRegression类进行介绍。
语法格式
class sklearn.linear_model.LogisticRegression(penalty='l2', *, dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver='lbfgs', max_iter=100, multi_class='auto', verbose=0, warm_start=False, n_jobs=None, l1_ratio=None)
常用参数解释:
- penalty: 指定正则项,也称惩罚项,接受
"l1","l2","elasticnet"(添加"l1"和"l2"罚分),"None"(不添加罚分)。默认为"l2"。实际应用时,一般penalty选择"l2"正则化就可以解决过拟合问题;当"l2"正则化预测效果不理想时,,再考虑"l1"正则化。另外,当我们想进行特征选择,使一些不重要的特征系数归零时,也可以考虑"l1"正则化。 - solver: 在逻辑回归损失函数的优化问题中使用的算法,接受
‘lbfgs’,‘liblinear’,‘newton-cg’,‘newton-cholesky’,‘sag’,‘saga’,default="lbfgs"。对于小数据集,选择"liblinear"合适,对于大数据集,选择"sag"和"saga"更快;对于多类问题,仅"newton-cg"、"sag","saga"和"lbfgs"处理多项损失;"liblinear"则仅限于 one-versus-rest 方案;‘newton-cholesky’对于n_samples >> n_features的情况是一个很好的选择,特别是对于具有稀有类别的one-hot encoded分类特征,它仅限于二元分类和多类分类的one-versus-rest reduction。注:算法的选择取决于所选择的penalty。"liblinear"和"saga"支持"l1";"newton-cg","sag","liblinear","saga","newton-cholesky"和"lbfgs"支持"l2";"saga"支持"elasticnet";"newton-cg","sag","saga","newton-cholesky"和"lbfgs"支持“None”。只有在具有大致相同scale的特征上,“sag”和“saga”才能实现快速收敛。 - dual: 接受布尔值,表示是否选择对偶。默认为
False。dual公式仅适用于使用liblinear的l2惩罚选项。当n_samples > n_features时选择dual=False更优。 - tol: 接受float, default=1e-4。表示迭代终止的误差阈值。
- C: float,表示正则化系数的倒数。 default=1.0,表示损失函数与正则项的比例为1:1。C值越小,表明正则化越强。
- random_state: 接受int, RandomState instance, default=None,用来设置随机数种子。当
solver== "sag", "saga"或"liblinear"时,使用此参数来洗牌数据。 - multi_class: 分类方式的选择,接受
"ovr"、"multinomial"和"auto",default="auto"。当solver='liblinear'时,'multinomial'不可用。如果数据是二分类或者solver= 'liblinear',' auto '选择' ovr ',否则选择'multinomial'。 - class_weight: 指定分类模型中各种类型的权重。
default=None表示所有类的权重都为1;定义{class_label: weight},如class_weight={0:0.4, 1:0.6},表明类别0的权重为40%,而类别1的权重为60%;'balanced'使用y值自动计算权重,某种类别样本量越多,则权重越低,样本量越少,则权重越高。提高某种类别的权重,相比不考虑权重,会有更多的样本分类划分到高权重的类别。这一参数的设置可帮助解决误分类的代价很高和类别不平衡问题。注:对于样本不平衡问题,除了使用class_weight='balanced'调节样本权重,还可以在调用fit函数时,通过sample_weight来调节每个样本权重。若两种方式都用,则真正权重为class_weight*sample_weight
代码示例
数据准备
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_breast_cancer
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
#导入数据
mydata = load_breast_cancer()
X = mydata.data
print(X.shape)
#(569, 30)
y = mydata.target
print(y.sum())
#357
#选择训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=100,stratify=y)
print(y_test.sum())
#107使用逻辑回归模型进行二分类—penalty和C
#L1正则化
LR_classifier_l1 = LogisticRegression(penalty="l1",solver="liblinear",random_state=200,max_iter=1000)
LR_classifier_l1 = LR_classifier_l1.fit(X_train,y_train)
print(LR_classifier_l1.coef_) #查看每个特征对应的参数
# output
# [[ 6.14368826 0.03201005 -0.43422785 -0.00929713 0. 0.
# 0. 0. 0. 0. 0. 0.
# 0.3325014 -0.06415746 0. 0. 0. 0.
# 0. 0. 0. -0.27739672 -0.138606 -0.02189744
# 0. 0. -1.20617611 0. 0. 0. ]]
print((LR_classifier_l1.coef_ != 0).sum(axis=1)) #特征不为0的数目
#[10]
#L2正则化,并确实合适的C值
LR_train_L2 = []
LR_test_L2 = []
for i in np.linspace(0.05,1.5,19):
LR_classifier_l2 = LogisticRegression(penalty="l2",solver="liblinear",random_state=200,C=i,max_iter=1000)
LR_classifier_l2 = LR_classifier_l2.fit(X_train,y_train) #根据给定的训练数据拟合模型
LR_classifier_l2.coef_ #查看每个特征对应的参数
(LR_classifier_l2.coef_ != 0).sum(axis=1) #特征不为0的数目
LR_train_L2.append(accuracy_score(LR_classifier_l2.predict(X_train),y_train))
LR_test_L2.append(accuracy_score(LR_classifier_l2.predict(X_test),y_test))
graph = [LR_train_L2,LR_test_L2]
label = ["LR_train_L2","LR_test_L2"]
color = ["black","red"]
plt.figure(figsize=(5,5))
for i in range(len(graph)):
plt.plot(np.linspace(0.05,2,19),graph[i],color[i],label=label[i])
plt.legend(loc=2)
plt.show()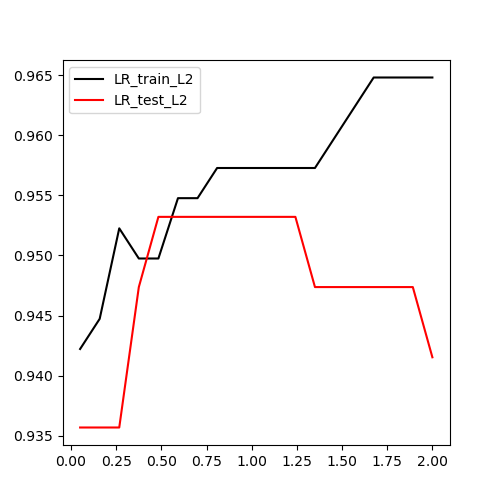
从上图可以看到,随着C值的增大,模型在训练集上的准确率呈逐渐增高趋势,但模型在测试集上则是先增高再下降,下降趋势的出现表明模型出现了过拟合。所以,C值应该选在0.8附近较合适。
使用逻辑回归模型进行二分类—属性
#使用逻辑回归模型进行二分类
LR_classifier_l1 = LogisticRegression(random_state=111,max_iter=10000).fit(X_train,y_train)
# 逻辑回归模型的属性
print(LR_classifier_l1.classes_) #返回分类器分类标签列表
# output
# [0 1]
print(LR_classifier_l1.coef_) #决策函数中特征的系数
# output
# [[ 1.15410426 0.230134 -0.43059984 0.04216892 -0.13415419 -0.2501231
# -0.44823279 -0.24323952 -0.1323144 -0.03414666 -0.10272575 0.29095627
# 0.9318758 -0.1548415 -0.0174981 -0.01001751 -0.05839226 -0.03094008
# -0.03626974 -0.0030106 0.08336832 -0.51150695 -0.19406931 -0.0158237
# -0.2188137 -0.54375324 -0.8737799 -0.41954908 -0.43748696 -0.07587481]]使用逻辑回归模型进行二分类—方法
#使用逻辑回归模型进行二分类
LR_classifier_l1 = LogisticRegression(random_state=111,max_iter=10000)
#逻辑回归模型类的方法
LR_classifier_l1.fit(X_train,y_train) #根据给定的训练数据拟合模型。
print(LR_classifier_l1.predict(X_test)) #预测测试集样本的类别标签,返回标签列表。当设置multi_class="multinomial",使用softmax函数来查找每个类的预测概率。
# output
# [1 1 0 1 1 1 0 0 1 1 1 1 1 1 0 1 1 1 1 1 1 0 1 1 1 0 1 0 0 1 0 0 1 1 0 0 0
# 0 0 0 1 1 1 1 1 0 0 0 0 1 1 0 0 1 1 1 0 0 1 1 0 1 1 1 1 1 1 1 1 1 0 1 1 1
# 0 1 1 0 0 1 1 0 1 0 1 1 0 1 0 1 0 1 1 1 1 0 1 1 1 1 1 0 1 1 1 1 0 1 1 1 1
# 0 1 0 1 1 1 1 0 1 1 1 0 1 1 1 1 1 0 0 0 1 1 1 1 0 0 0 1 0 0 0 0 0 1 1 1 1
# 0 1 0 0 1 1 0 1 0 1 1 1 0 1 0 1 0 0 1 1 0 1 0]
print(LR_classifier_l1.predict_proba(X_test)) #概率估计,返回预测属于某标签的概率
# output
# [[5.78861498e-03 9.94211385e-01]
# [1.91288023e-05 9.99980871e-01]
# ...
# [2.04978266e-04 9.99795022e-01]]
print(LR_classifier_l1.score(X_test,y_test)) #返回给定测试数据和标签的平均精度
# 0.9473684210526315
print(LR_classifier_l1.get_params()) #获取模型的参数
# output
# {'C': 1.0, 'class_weight': None, 'dual': False, 'fit_intercept': True,
# 'intercept_scaling': 1, 'l1_ratio': None, 'max_iter': 10000,
# 'multi_class': 'auto', 'n_jobs': None, 'penalty': 'l2', 'random_state': 111,
# 'solver': 'lbfgs', 'tol': 0.0001, 'verbose': 0, 'warm_start': False}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号