pandas对象读取及保存
Input/output相关函数
pandas.read_excel—将Excel文件读入pandas数据框
支持读取xls, xlsx, xlsm, xlsb, odf, ods和odt文件扩展名,支持单个sheet或sheet列表
语法格式
pandas.read_excel(io, sheet_name=0, *, header=0, names=None, index_col=None, usecols=None, squeeze=None, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, parse_dates=False, date_parser=None, thousands=None, decimal='.', comment=None, skipfooter=0, convert_float=None, mangle_dupe_cols=True, storage_options=None)
常用的几个参数解释:
- io: 文件路径,也可以是URL。
- sheet_name: 接受字符串、整数、列表、None。默认为0,代表加载第一个sheet;输入
"sheet1"加载名字为"sheet1"的表;[1, 2, "sheet3"]表示加载第1、2个和名字为"sheet3"的sheet;None表示加载所有。 - header: 接受整数及整数列表。默认为0,表示第一行作为列标签。[1, 3]则表示第2和4行被组合为列标签。如果没有列标签则使用
None。 - names: 作用是给数据框添加列名。默认为
None。 - usecols: 接受str, list-like, or callable。默认为
None,表示解析所有列;"A,C,D:F"表示解析A,C,D,E,F列;[1,2,4]表示解析第2,3和5列;["name", "age"]表示解析列名为name, age的列。 - index_col: 接受整数及整数列表,添加行标签。默认为
None,表示无行标签。[1, 3]则表示第2和4列被组合为行标签。 - comment: 接受字符,默认为
None。注释字符串和当前行结束之间的任何数据都将被忽略。
代码示例
准备如下图所示的test.xlsx文件
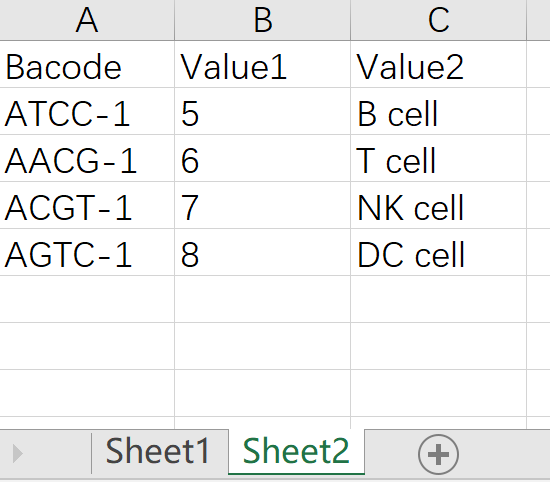
编写脚本
import pandas as pd
df = pd.read_excel("./input/test.xlsx", sheet_name="Sheet2")
print(df, "\n")
df1 = pd.read_excel(open("./input/test.xlsx", "rb"), sheet_name="Sheet2")
print(df1, "\n")
df2 = pd.read_excel("./input/test.xlsx", sheet_name="Sheet2", usecols="A:B") #usecols="A:B"等同于usecols="A,B"等同于usecols=[0,1],但usecol不能写成[0:1],会报错
print(df2, "\n")
df3 = pd.read_excel("./input/test.xlsx", sheet_name="Sheet2", usecols=[0,1], names=["index","Value"])
print(df3)输出结果
Bacode Value1 Value2
0 ATCC-1 5 B cell
1 AACG-1 6 T cell
2 ACGT-1 7 NK cell
3 AGTC-1 8 DC cell
Bacode Value1 Value2
0 ATCC-1 5 B cell
1 AACG-1 6 T cell
2 ACGT-1 7 NK cell
3 AGTC-1 8 DC cell
Bacode Value1
0 ATCC-1 5
1 AACG-1 6
2 ACGT-1 7
3 AGTC-1 8
index Value
0 ATCC-1 5
1 AACG-1 6
2 ACGT-1 7
3 AGTC-1 8pandas.DataFrame.to_excel—将对象写入Excel表
语法格式
DataFrame.to_excel(excel_writer, sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=_NoDefault.no_default, inf_rep='inf', verbose=_NoDefault.no_default, freeze_panes=None, storage_options=None)
常用的几个参数解释:
- excel_writer:文件路径或ExcelWriter(适用于写入多个sheet表)。
- sheet_name: 包含数据框的sheet,默认为"Sheet1"。
- na_rep: 缺失值处理方式。默认为“”。
- float_name: 为浮点数格式化字符串。
float_format="%.2f"表示保留两位小数点。 - columns: 可选项,接受序列或字符串列表,指出要写入的列。
- header: 添加列名。默认值为True。如果给出一个字符串列表,则假定它是列名的别名。
- index: 写行名,接受字符串列表和布尔值。默认为True,表示写入行名。
- engine: 可选项,常用的模式有'openpyxl'和'xlsxwriter'。其中xlsxwriter不支持append操作。
代码示例
编写脚本
import pandas as pd
df = pd.read_excel("./input/test.xlsx", sheet_name="Sheet2")
print(df, "\n")
#将单个对象写入一个.xlsx文件,只需要指定目标文件名
df.to_excel("./newfile/output.xlsx", index=False, sheet_name="expression")运行后会输出一个./newfile/output.xlsx文件,内容如下:
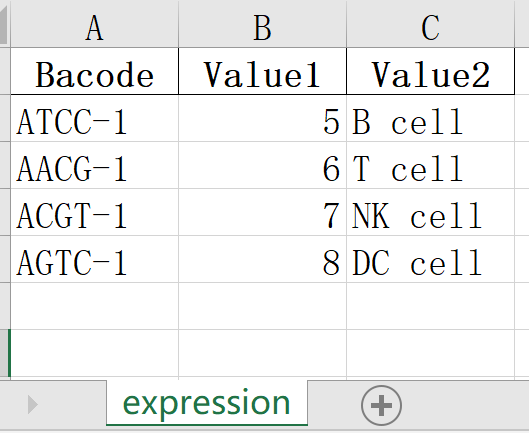
编写脚本
import pandas as pd
df = pd.read_excel("./input/test.xlsx", sheet_name="Sheet2")
print(df, "\n")
#写入多个sheet,必须创建一个ExcelWriter对象和目标文件名,并在文件中指定要写入的工作表。
#使用已经存在的文件名创建ExcelWriter对象将导致现有文件的内容被擦除。
df1 = df.copy()
with pd.ExcelWriter("./newfile/output.xlsx") as writer:
df.to_excel(writer, sheet_name="value1")
df1.to_excel(writer, sheet_name="value2")运行后会覆盖上一步生成的output.xlsx内容,并重新生成如下内容:
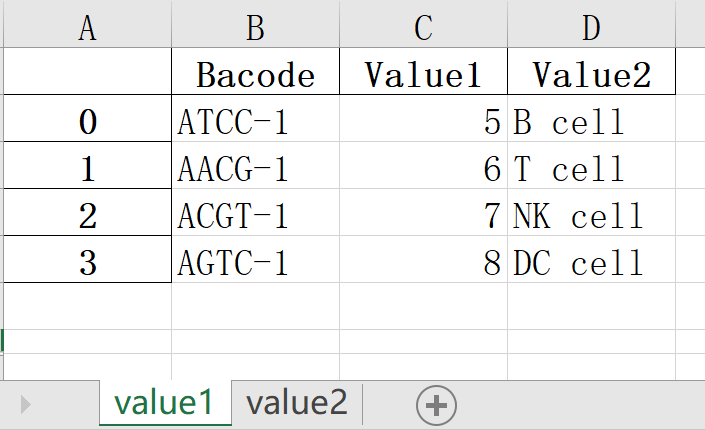
编写脚本
import pandas as pd
df = pd.read_excel("./input/test.xlsx", sheet_name="Sheet2")
print(df, "\n")
#ExcelWriter也可以被用来扩展已存在的文件
with pd.ExcelWriter("./newfile/output.xlsx", mode="a", engine='openpyxl') as writer:
df.to_excel(writer, sheet_name="value3")运行后会在上方excel基础上再添加一个名为value3的sheet。
pandas.read_csv—将csv文件读入pandas数据框,与pandas.read_excel类似
pandas.DataFrame.to_csv—将对象写入csv文件,与pandas.DataFrame.to_excel类似

 浙公网安备 33010602011771号
浙公网安备 33010602011771号