scrapy
Scrapy,Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。
Scrapy结构
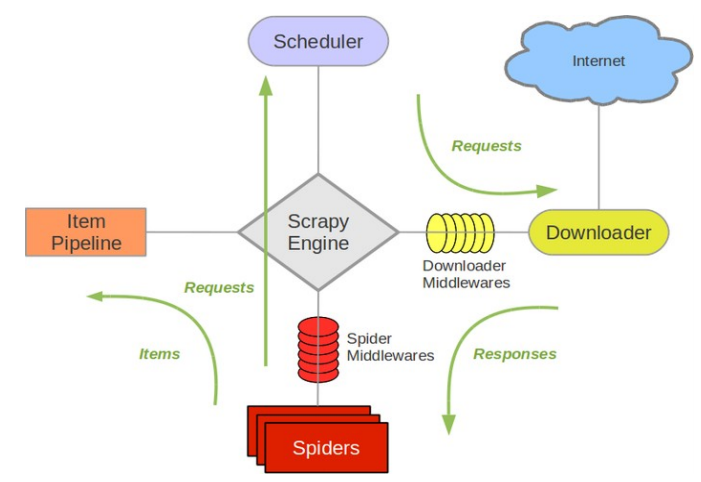
Scrapy的工作方式
- 从初始的URL开始,Scheduler会将URL交给Downloader进行下载
- 下载完之后交给Spiders进行分析
- Spider分析出来的结果一方面传给Scheduler需要进一步爬取得链接,另一方面将需要保持的数据送到Item Pipeline里,进行后续的处理,例如分析,过滤,存储等
- 在数据流动的通道里可以安装各种中间件,进行一些其他的处理
Scrapy结构
-
引擎(Scrapy Engine)
Scrapy Engine 是控制数据流在系统组件间的流动,并在相应的动作上触发对应的事件
-
调度器(Scheduler)
Scheduler从Scrapy Engine里接受requests,并将其放入队列中,以便在Scrapy Engine发出请求后返回给他们
-
下载器(Downloader)
Downloader获取网页的数据,然后将数据发给Scrapy Engine,进而将数据给Spiders
-
蜘蛛(Spiders)
Spiders是用户分析Downloader发送过来的response,然后提取response中我们想要的数据item,也可以将需要进一步爬取的链接发送给Scheduler
Spiders爬取流程:
-
-
- 先初始化请求URL列表,并指定下载处理response的回调函数
- 在parse回调解析response并返回字典,Item对象,Request对象或他们的迭代对象
- 在回调函数里面,使用选择器解析页面内容,并生成解析后的结果Item
- 最后返回的这些Item通常会被持久化到数据库中(使用Item Pipeline)或者使用Feed exports将其保存到文件中
-
不同类型的Spiders:
-
-
- CrawSpider:链接爬取蜘蛛,属性rules:Rule对象列表,定义规则
-

-
-
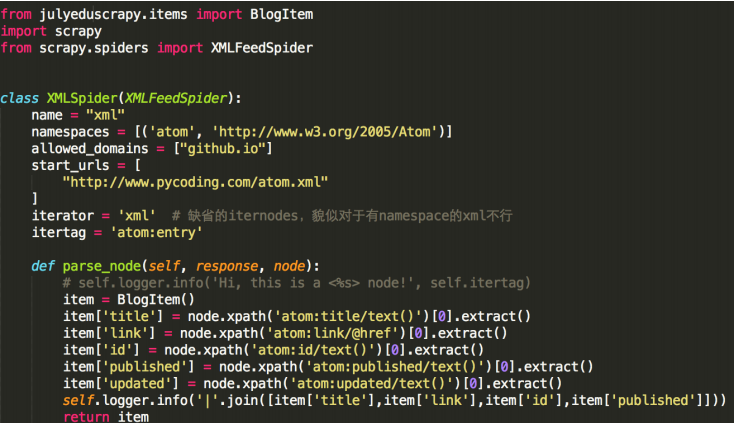
- XMLFeedSpider:XML订阅蜘蛛,通过某个指定的节点遍历
-
-
-
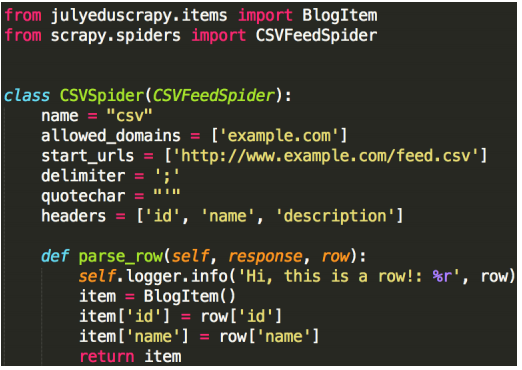
- CSVFeedSpider:类似XML订阅蜘蛛,逐行迭代,调用parse_row()解析
-
-
项目管道(Item Pipeline)
当一个item被Spiders爬取到后传给Item Pipeline后,多个组件就会按照顺序处理这个item
常用场景:
-
-
- 清理HTML数据
- 验证被抓取的数据
- 重复性检查
- 将抓取的数据存储到数据库中
-
常用的方法:
-
-
- open_spider(self,spider):蜘蛛打开的执行
- close_spider(self,spider):蜘蛛关闭时执行
- from_crawler(self,crawler):可访问核心组件比如配置和信号,并注册钩子函数的Scrapy中
- process_item(self,item,spider):定义的Item pipeline会默认调用该方法对Item进行处理,它返回Item类型的值或者抛出DropItem异常
-
-
下载器中间件(Downloader Middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。
-
蜘蛛中间件(Spider Middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。
-
调度中间件(Scheduler Middlewares)
调度中间件是介于Scrapy引擎和调度之间的中间件,主要工作是处从Scrapy引擎发送到调度的请求和响应
Script项目创建
在命令行里进入到某一个目录,输入scrapy startproject '项目名',那么就可以创建出一个scrapy项目了