python之路(五)--常用模块
python的常用模块
模块是为完成某一功能所需的一段程序或子程序。
模块的种类
- 内置模块
- 第三方模块
- 自定义模块
模块的导入方法
-
import module_name
导入指定的module_name模块,使用的话module_name.funcname(),如果有嵌套(import 文件夹名.module_name)的也需要写全,文件夹.module_name.funcname这样
-
form module_name import funcname
导入指定的module_name模块中的funcname,不需要加模块名,直接用函数就可以,如果有嵌套(form 文件夹名 import module_name),可以不加文件夹名,module_name.funcname,也可以使用as取一个别名
-
form module_name import *
"*"" 表示,该模块的所有公共对象都被导入到 当前的名称空间,也就是任何导入所有不是以”_”开始的。
模块中常用的全局变量
- __name__:如果为主文件,那些__name__等于 __main__,否则等于模块名
- __file__:当前文件的路径
- __doc__:获取当前文件的注释
- __package:如果是当前文件为None,导入其他文件,指定文件所在的包,用 . 分隔
sys模块
sys模块是用来获取操作系统和编译器的一些配置,设置及操作
1 sys.argv 获取命令行参数,第一个元素是程序本身路径
2 sys.exit(n) 退出程序,返回n,正常退出的话返回0
3 sys.version 获取Python解释程序的版本信息
4 sys.path 返回模块的搜索路径
5 sys.platform 返回操作系统平台名称(window为win32,linux为linux2)
6 sys.stdin 输入相关
7 sys.stdout 输出相关
8 stdout 是一个类文件对象;调用它的 write 函数可以打印出你给定的任何字符串,与print
9 不同的是,print会换行,为sys.stdout.write输出的不会换行,例如:
 进度条的显示
进度条的显示

1 import sys,time 2 for i in range(100): 3 sys.stdout.write("\r") 4 sys.stdout.write("%s%% | %s"%(int(i),int(i)*"*")) 5 sys.stdout.flush() 6 time.sleep(0.1)
10 sys.stderror 错误相关
time模块
在python中通常有这几种方式来表示时间:
- 时间戳(timestamp)
通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量,即time.time()
- 格式化的时间字符串
xxxx-xx-xx xx:xx,即:time.strftime()
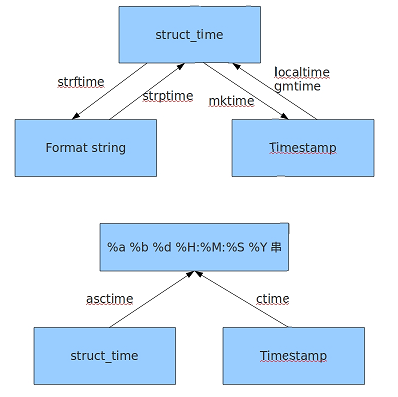
- 元组(struct_time)
返回struct_time的函数主要有gmtime(),localtime(),strptime()。下面列出这种方式元组中的几个元素:
| 属性(Attribute) | 值(Values) | |
|---|---|---|
| tm_year(年) | 比如2018 | |
| tm_mon(月) | 1 - 12 | |
| tm_mday(日) | 1 - 31 | |
| tm_hour(时) | 0 - 23 | |
| tm_min(分) | 0 - 59 | |
| tm_sec(秒) | 0 - 61 | |
| tm_wday(weekday) | 0 - 6(0表示周日) | |
| tm_yday(一年中的第几天) | 1 - 366 | |
| tm_isdst(是否是夏令时) | 默认为-1 |
1 time.time():返回当前时间的时间戳。
2 time.localtime([st]):将一个时间戳转换为当前时区的struct_time。参数未提供,则以当前时间为准
3 time.gmtime([st]):和localtime()方法类似,将一个时间戳转换为UTC时区的struct_time。
4 UTC(Coordinated Universal Time,世界协调时)亦即格林威治天文时间,世界标准时间。在中国为UTC+8
5 time.mktime([st])将一个struct_time转化为时间戳。
6 time.ctime:把一个时间戳转化为time.asctime()的形式。如果参数未给或者为None,会默认time.time()为参数
7 time.asctime(st_time):把一个表示时间的元组或者struct_time表示为这种形式:Mon Feb 26 20:48:16 2018。如果没有参数,将会将time.localtime()作为参数传入。
8 time.strftime(format,st)把一个代表时间的元组或者struct_time转化为格式化的时间字符串。如果st未指定,将传入time.localtime()。
如果元组中任何一个元素越界,ValueError的错误将会被抛出。例如:
print(time.strftime("%Y-%m-%d %X", time.localtime()))#输出为2018-02-26 20:50:47
10 time.strptime(string[, format]):把一个格式化时间字符串转化为struct_time。实际上它和strftime()是逆操作。
%a 本地(locale)简化星期名称 %A 本地完整星期名称 %b 本地简化月份名称 %B 本地完整月份名称 %c 本地相应的日期和时间表示 %d 一个月中的第几天(01 - 31) %H 一天中的第几个小时(24小时制,00 - 23) %I 第几个小时(12小时制,01 - 12) %j 一年中的第几天(001 - 366) %m 月份(01 - 12) %M 分钟数(00 - 59) %p 本地am或者pm的相应符 一 %S 秒(01 - 61) 二 %U 一年中的星期数。(00 - 53星期天是一个星期的开始。)第一个星期天之前的所有天数都放在第0周。 三 %w 一个星期中的第几天(0 - 6,0是星期天) 三 %W 和%U基本相同,不同的是%W以星期一为一个星期的开始。 %x 本地相应日期 %X 本地相应时间 %y 去掉世纪的年份(00 - 99) %Y 完整的年份 %Z 时区的名字(如果不存在为空字符) %% ‘%'字符
转换关系:
datetime模块
datetime是基于time模块封装的,里面有几个类:datetime、date、time、timedelta、datetime_CAPI、tzinf
常用用法:
print(datetime.datetime.now()) #获取当前时间,输出格式:2018-02-26 21:18:49.104680 print(datetime.date.today()) #返回当前日期,输出格式:2018-02-26 print(datetime.datetime.utcnow())#获取UTC时间,格式:2018-02-26 13:20:54.444105 print(datetime.date.fromtimestamp(time.time()))#根据给定的时间戮,返回一个date对象
os模块
os模块提供了多数操作系统的功能接口函数.对目录或者文件的新建/删除/查看文件属性,还提供了对文件以及目录的路径操作。比如说:绝对路径,父目录。当os模块被导入后,它会自适应于不同的操作系统平台
1 os.sep 可以取代操作系统特定的路径分隔符。windows下为 “\\”,Linux下为"/" 2 os.linesep 当前平台使用的行终止符。例如,Windows使用'\r\n',Linux使用'\n'而Mac使用'\r'。 3 os.pathsep 输出用于分割文件路径的字符串,系统使用此字符来分割搜索路径,例如POSIX上':',Windows上的';' 4 os.getcwd() 获取当前工作目录 5 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd 6 os.curdir 返回当前目录: ('.') 7 os.pardir 获取当前目录的父目录字符串名:('..') 8 os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname 9 os.makedirs('dirname1/dirname2') 可生成多层递归目录 10 os.remove(file) 删除一个文件 11 os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 12 os.rmdir('dirname') 删除单级空目录,若目录不为空报错;相当于shell中rmdir dirname 13 os.listdir('dirname') 列举目录下的所有文件,并以列表方式打印 14 os.rename("oldname","new") 重命名文件/目录 15 os.replace(src,dest) 重命名文件/目录,如果dest表示的是文件,存在则覆盖原来的文件,不报错;若是目录,存在则会报错 16 os.stat('path/filename') 获取文件/目录信息,相当于C语言中stat函数 17 os.name 字符串指示当前使用平台。win下为'nt'; Linux下为'posix' 18 os.getenv() 获取一个环境变量,如果没有返回none 19 os.putenv(key, value) 设置一个环境变量值 20 os.environ[] 获取环境变量的值 21 os.system(command) 用来运行shell命令。 22 os.popen("bash command") 运行shell命令,生成对象,可赋给变量,再用read读取 23 os.path.abspath(path) 返回path的绝对路径。 24 os.path.split(path) 将path分割成目录和文件名,以元组返回 25 os.path.dirname(path) 返回path中的目录,结果不包含'\' 26 os.path.basename(path) 返回path最后的文件名,如果path以/或\结尾,那么就会返回空值 27 os.path.exists(path) 判断path是否为存在,存在为True,不存在为False 28 os.path.join(path1,path2,...) 将path进行组合,若其中有绝对路径,则之前的path将被删除 29 os.path.isabs(path) 判断path是否为绝对路径,是返回True,否返回False 30 os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False 31 os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False 32 os.path.getmtime(path) 文件或文件夹的最后修改时间 33 os.path.getatime(path) 文件或文件夹的最后访问时间 34 os.path.getctime(path) 文件或文件夹的创建时间
path=os.path.abspath(os.curdir) #H:\python编程\new print(os.path.split(path)) print(os.path.split(".")) #('H:\\python编程', 'new') #('', '.')‘ print(os.path.dirname(path)) #H:\python编程 print(os.path.basename(path)) #new print(os.path.join("H:\\python编程", "new")) print(os.path.join("H:\\python编程\\new","H:\\python编程\\new_dir")) #H:\python编程\new #H:\python编程\new_dir print(os.path.isabs(path)) print(os.path.isfile(path)) print(os.path.getatime(path)) print(os.path.getctime(path)) print(os.path.getmtime(path)) #1519656857.1664195 #1517967877.2101693 #1519656857.1664195
re模块
re模块提供了正则表达式相关操作,通过这个接口,python可以使用正则表达式
特殊意义的字符
- . ::匹配除换行符以外的任意字符
- * : 匹配前面的字符0次或多次
- +: 匹配前面的字符1次或多次
- ?: 匹配前面的字符0次或1次
- *?,+?,??:'*'、'+'和'?'限定符是贪婪的; 它们匹配尽可能多的文本。有时这个行为不是想要的,在限定符之后加上'?'将使得匹配以非贪婪的或最小的方式进行;因为它将匹配尽可能少的字符
- {}:固定重复次数
- {m}:重复m次
- {m,n}:重复m到n次
- {m,}:重复m次以上
- ():作为一个组
- []:用来表示一个字符集合
- ^ :匹配字符串的开始,但是在字符集中有另一种用法:[^xxx]表示除了xxx以外的
- $ :匹配字符串的结尾
- \ :转义
- \ + 元字符:去点元字符特殊的功能
- \ + 普通字符:实现普通字符的特殊功能
- \d :匹配任何的十进制数,相当于[0-9]
- \D :匹配任何非数字字符,相当于[^0-9]
- \s :匹配任何空白字符,相当于[\t\r\n\f\v]
- \S :匹配任何非空白字符,相当于[^ \t\r\n\f\v]
- \w :匹配任何字母数字字符,相当于[a-zA-Z0-9]
- \W :匹配任何非字母数字字符,相当于[^a-zA-Z0-9]
- \b :匹配一个单词的边界,也就是指单词和空格间的位置
- \ + 数字:对应分组的功能,引用序号对应字组所匹配的
对于\这个字符,如果我们想匹配一个普通的\字符的话,就需要写成"\\\\"这样子,这是因为python解释器将“\\”解释为一个\,而正则表达式也需要将"\\"解释为一个\,还有一种简便的写法是r“\\”,在前面加一个r即可,向python解释说这就是一个普通的字符串,然后正则表达式就可以匹配一个\,即将"\\"就可以匹配一个普通的\字符
- | :或
- (?P<name>..):添加一个字典对象到re.groupdict()中
-
match
从起始位置开始匹配,匹配成功返回一个MatchObject对象,未匹配成功返回None
re.match(pattern, string, flags=0)-
-
- re.I :使匹配对大小写不敏感
- re.L:做本地化识别匹配
- re.M:多行匹配,影响^和$
- re.S:是.匹配包括多行在内的所有字符
-
match
1 import re 2 str_list="1abc2dfhdg2abc3rethgt3abc324" 3 r=re.match("(?P<python>\dabc\d)+",str_list) 4 print(type(r)) 5 print(r.group()) # 获取匹配到的所有结果 6 print(r.groups()) # 获取模型中匹配到的分组结果 7 print(r.groupdict()) # 获取模型中匹配到的分组结果 8 print(re.match("2abc",str_list)) 9 10 #######输出######### 11 <class '_sre.SRE_Match'> 12 1abc2 13 ('1abc2',) 14 {'python': '1abc2'} 15 None
-
search
扫描字符串,寻找的第一个由该正则表达式模式产生匹配的位置,并返回相应的MatchObject对象,没有的话返回None
re.search(pattern, string, flags=0),和match一样,区别就是search,扫描整个字符串去匹配第一个,而match只是从开头开始匹配
search
str_list="abc2dfhdg2abc3rethgt3abc324" r=re.search("(?P<python>\dabc\d)+",str_list) print(r.group()) # 获取匹配到的所有结果 print(r.groups()) # 获取模型中匹配到的分组结果 print(r.groupdict()) # 获取模型中匹配到的分组结果 #####输出######## 2abc3 ('2abc3',) {'python': '2abc3'}
-
findall
获取所有非重复的匹配列表;如果有一个组则以列表形式返回,且每一个匹配均是字符串;如果模型中有多个组,则以列表形式返回,且每一个匹配均是元祖;
re.findall(pattern, string, flags=0),pattern,string,flags和match,search差不多,不同的是pattern可以使空,如果为空的话,会出现比string的个数还要多一个的空字符
findall
r=re.findall("(?P<python>\dabc\d)+",str_list) print(type(r)) print(r) r=re.findall("","sdfds") print(r) #######输出######## <class 'list'> ['2abc3', '3abc3'] ['', '', '', '', '', '']
-
split
将字符串拆分的模式的匹配项
re.split(pattern, string, maxsplit=0, flags=0)
pattern: 正则表达式模型 string : 要匹配的字符串 maxsplit:分割个数 flags : 匹配模式
1 str_list="abc2dfhdg2abc3rethgt3abc324" 2 print(re.split("\dabc\d",str_list)) #无分组 3 print(re.split("(\dabc\d)",str_list)) #有分组 4 5 ######输出####### 6 ['abc2dfhdg', 'rethgt', '24'] 7 ['abc2dfhdg', '2abc3', 'rethgt', '3abc3', '24']
-
sub
替换匹配成功的指定位置字符串
re.sub(pattern, repl, string, count=0, flags=0)
pattern: 正则表达式模型 repl : 要替换的字符串或可执行对象 string : 要匹配的字符串 count : 匹配个数 flags : 匹配模式
1 str_list="abc2dfhdg2abc3rethgt3abc324" 2 print(re.sub("\dabc\d","*linux*",str_list)) 3 4 #########输出######## 5 abc2dfhdg*linux*rethgt*linux*24
-
subn
和sub一样,执行相同的操作,但返回一个元组,同时返回替换字符串的个数
re.subn(pattern, repl, string, count=0, flags=0)
1 str_list="abc2dfhdg2abc3rethgt3abc324" 2 print(re.subn("\dabc\d","*linux*",str_list)) 3 4 ##########输出########## 5 ('abc2dfhdg*linux*rethgt*linux*24', 2)
hashlib模块
hashlib 是一个提供了一些流行的hash算法的 Python 标准库.其中所包括的算法有 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
1 import hashlib 2 3 def register(username,passwd): 4 with open("data.txt",'r+') as file: 5 for line in file: 6 line_list=line.split("||") 7 if line_list[0]==username: 8 print("username is exist!") 9 return 10 Emd5=hashlib.md5(bytes("pythonlinux",encoding="utf-8")) #创建一个MD5对象 11 Emd5.update(bytes(passwd,encoding="utf-8")) #对passwd进行加密 12 Epasswd=Emd5.hexdigest() #获取加密后的字符串 13 info="%s||%s\n"%(username,Epasswd) 14 file.write(info) 15 16 def login(username,passwd): 17 Emd5 = hashlib.md5(bytes("pythonlinux", encoding="utf-8")) 18 Emd5.update(bytes(passwd, encoding="utf-8")) 19 Epasswd = Emd5.hexdigest() 20 with open("data.txt","r+") as file: 21 for line in file: 22 line_list=line.strip().split("||") 23 if line_list[0]==username and line_list[1]==Epasswd: 24 print("login success") 25 return 26 register("python","123") 27 login("python","123") 28 29 ############# 30 其他的算法的用法和md5一样
pickle模块
用于python特有的类型 和 python基本数据类型间进行转换
pickle中的函数dumps、dump、loads、load
-
- loads:直接从bytes对象中读取序列化的信息,而非从文件中读取。
- load:将序列化的对象从文件file中读取出来
- dumps:将数据转变为只有python认识的字符串
- dump:将数据转变为只有python认识的字符串,并写入文件中
import pickle s=[11,22,33,44,55] str_dict='{"dict":"list","k1":"1"}' st=pickle.dumps(str_dict) print(type(st),st) li=pickle.loads(st) print(type(li),li) #########输出######### <class 'bytes'> b'\x80\x03X\x18\x00\x00\x00{"dict":"list","k1":"1"}q\x00.' <class 'str'> {"dict":"list","k1":"1"}
json模块
用于字符串和 python基本数据类型间进行转换,与pickle不同的是,json可以与不同的语言进行交互
json中的函数dumps、dump、loads、load
-
- loads:用于将列表,元祖,字典形式的字符串转变为真的的列表,元祖,字典。注意:列表,字典,元祖形式的字符串如果里面的元素是字符串的话,必须要用双引号""括起来,否则报错
- load:打开文件,并将列表,元祖,字典形式的字符串转变为真的的列表,元祖,字典,
- dumps:将数据转变为所有语言都认识的字符串
- dump:将数据转变为所有语言都认识的字符串,并写入文件中
import json string="[11,22,33,44,55]" str_dict='{"dict":"list","k1":"1"}' #str_dict="{'dict':'list','k1':'1'}" 这个出错 li=json.loads(str_dict) print(type(li),li) st=json.dumps(li) print(type(st),st) ########输出######## <class 'dict'> {'dict': 'list', 'k1': '1'} <class 'str'> {"dict": "list", "k1": "1"}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号