82. 删除排序链表中的重复元素 II
题目:
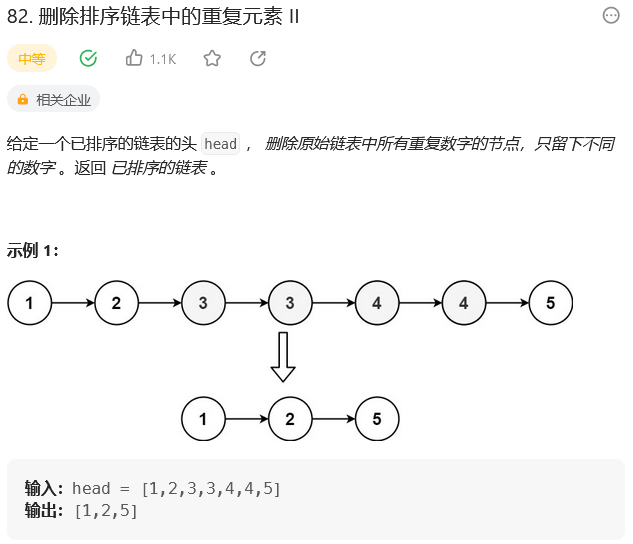
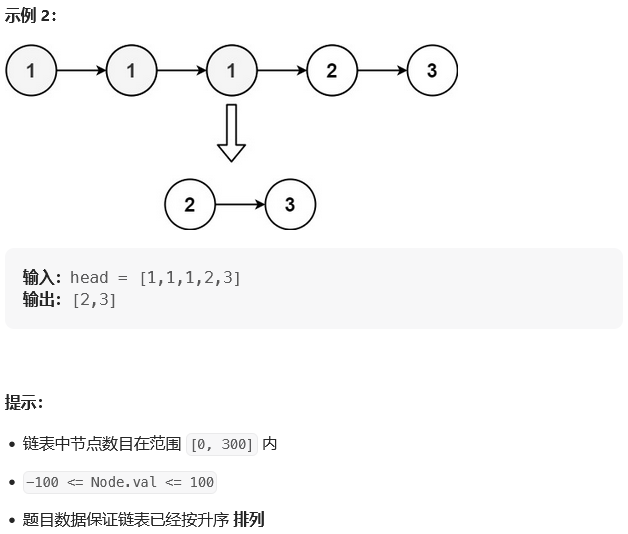
思路:
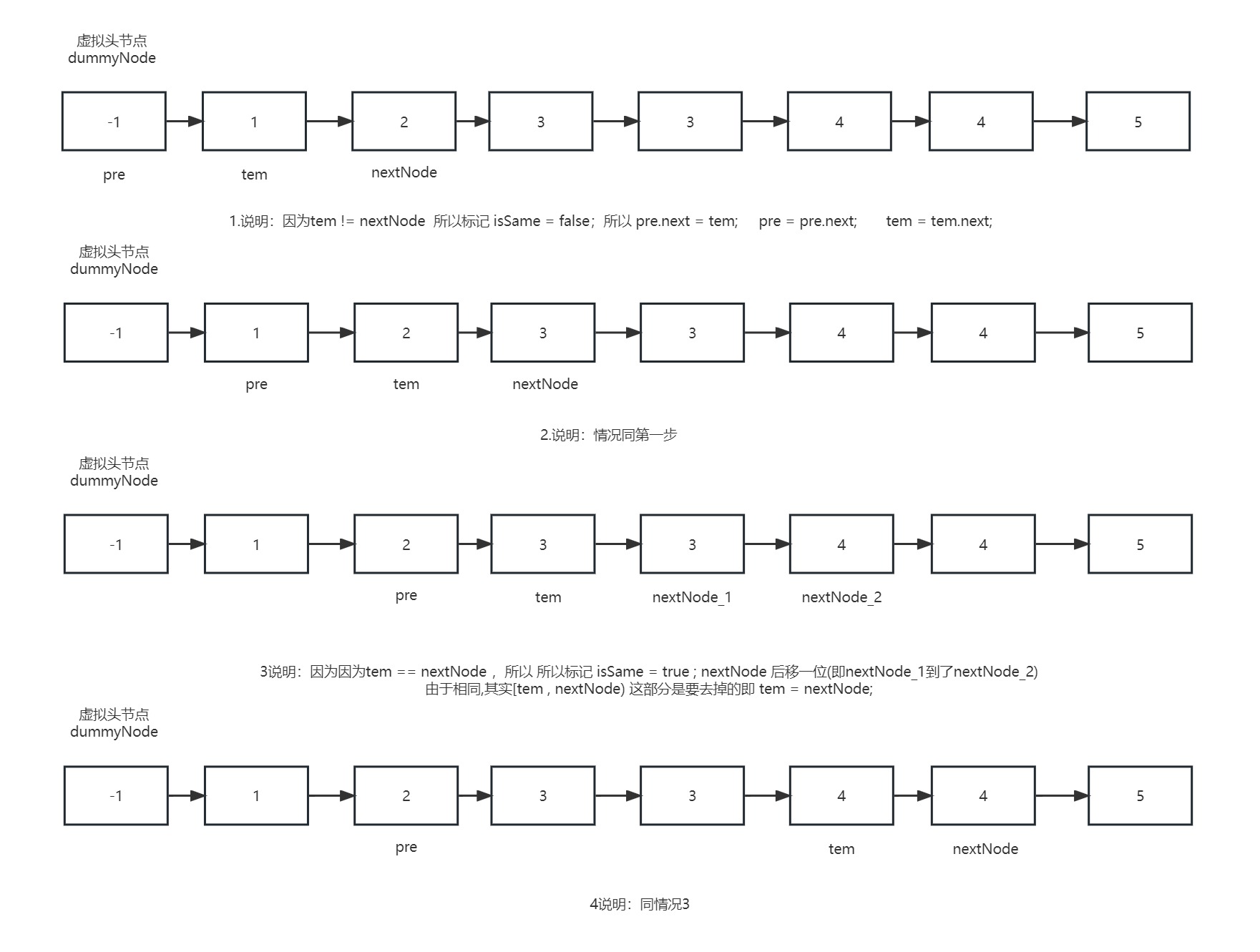
【1】逻辑如图:(由于最后的pre是会存在以前的链接指向的,这个是需要清除的)
代码展示:
//时间0 ms 击败 100% //内存42.1 MB 击败 5.69% //时间复杂度:O(n),其中 n 是链表的长度。 //空间复杂度:O(1)。 /** * Definition for singly-linked list. * public class ListNode { * int val; * ListNode next; * ListNode() {} * ListNode(int val) { this.val = val; } * ListNode(int val, ListNode next) { this.val = val; this.next = next; } * } */ class Solution { public ListNode deleteDuplicates(ListNode head) { // 因为头节点有可能发生变化,使用虚拟头节点可以避免复杂的分类讨论 ListNode dummyNode = new ListNode(-1); ListNode pre =dummyNode , tem = head; boolean isSame; while (tem != null){ // 判断标志,判断当前元素是否与下一个元素相等 isSame = false; ListNode nextNode = tem.next; // 如果出现相等的情况,就直接找到不相等的元素 while (nextNode != null && tem.val == nextNode.val){ isSame = true; nextNode = nextNode.next; } if (isSame){ // 出现相等的话,相等的都要舍弃 // 所以遍历指针直接跳到不等的地方 tem = nextNode; }else { // 如果是不存在相等的情况就需要纳入到返回的链表里面 pre.next = tem; pre = pre.next; // 且遍历指针要偏移到下一位 tem = tem.next; } } // 返回结果切断旧链接 pre.next = null; return dummyNode.next; } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号