MyBatis详解(二)
前言
本篇幅是继 MyBatis详解(一)的下半部分。
MyBatis执行Sql的流程分析
【1】基于前面已经将XML文件进行build解析了并且返回了SqlSessionFactory
【1.1】那么分析SqlSessionFactory.openSession()方法是怎么返回SqlSession的,且SqlSession又是什么东西:
@Override public SqlSession openSession() { return openSessionFromDataSource(configuration.getDefaultExecutorType(), null, false); } /** * 方法实现说明:从session中开启一个数据源 * @param execType:执行器类型 * @param level:隔离级别 */ private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) { Transaction tx = null; try { // 获取环境变量 final Environment environment = configuration.getEnvironment(); // 获取事务工厂 final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment); tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit); // 创建一个sql执行器对象 // 一般情况下 若我们的mybaits的全局配置文件的cacheEnabled默认为ture就返回一个cacheExecutor,若关闭的话返回的就是一个SimpleExecutor final Executor executor = configuration.newExecutor(tx, execType); // 创建返回一个DeaultSqlSessoin对象返回 return new DefaultSqlSession(configuration, executor, autoCommit); } catch (Exception e) { closeTransaction(tx); // may have fetched a connection so lets call close() throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e); } finally { ErrorContext.instance().reset(); } }
【1.1.1】分析newExecutor方法中执行器的产生:
/** * 方法实现说明:创建一个sql语句执行器对象 * @param transaction:事务 * @param executorType:执行器类型 * @return:Executor执行器对象 */ public Executor newExecutor(Transaction transaction, ExecutorType executorType) { executorType = executorType == null ? defaultExecutorType : executorType; executorType = executorType == null ? ExecutorType.SIMPLE : executorType; Executor executor; //判断执行器的类型 // 批量的执行器 if (ExecutorType.BATCH == executorType) { executor = new BatchExecutor(this, transaction); } else if (ExecutorType.REUSE == executorType) { //可重复使用的执行器 executor = new ReuseExecutor(this, transaction); } else { //简单的sql执行器对象 executor = new SimpleExecutor(this, transaction); } //判断mybatis的全局配置文件是否开启缓存 if (cacheEnabled) { //把当前的简单的执行器包装成一个CachingExecutor executor = new CachingExecutor(executor); } //调用所有的拦截器对象plugin方法,也就是生成代理对象 executor = (Executor) interceptorChain.pluginAll(executor); return executor; }
【1.1.1.1】图示:
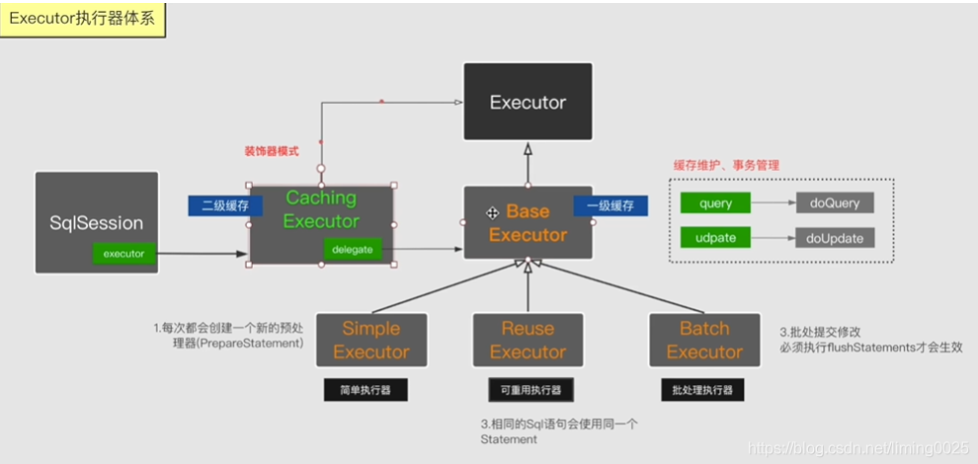
【1.1.2】分析底层如何执行JDBC【User user = (User)session.selectOne("com.mapper.UserMapper.selectById", 1);】
/** * 方法实现说明:查询我们当个对象 * @param statement:SQL语句 * @param parameter:调用时候的参数 * @return: T 返回结果 */ @Override public <T> T selectOne(String statement, Object parameter) { // 这里selectOne调用也是调用selectList方法 List<T> list = this.selectList(statement, parameter); //若查询出来有且有一个一个对象,直接返回要给 if (list.size() == 1) { return list.get(0); } else if (list.size() > 1) { //查询的有多个,那么就抛出异常 throw new TooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: " + list.size()); } else { return null; } } @Override public <E> List<E> selectList(String statement, Object parameter) { return this.selectList(statement, parameter, RowBounds.DEFAULT); } /** * @param statement: statementId * @param parameter:参数对象 * @param rowBounds :mybiats的逻辑分页对象 */ @Override public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) { try { //第一步:通过我们的statement去我们的全局配置类中获取MappedStatement MappedStatement ms = configuration.getMappedStatement(statement); //通过执行器去执行我们的sql对象 //第一步:包装我们的集合类参数 //第二步:一般情况下是executor为cacheExetory对象 return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER); } catch (Exception e) { throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e); } finally { ErrorContext.instance().reset(); } }
【1.1.2.0】分析两种方法的本质:
方法一:User user = (User)session.selectOne("com.mapper.UserMapper.selectById", 1); 源码流程: //通过statement去我们的全局配置类中获取MappedStatement MappedStatement ms = configuration.getMappedStatement(statement); public MappedStatement getMappedStatement(String id) { return this.getMappedStatement(id, true); } public MappedStatement getMappedStatement(String id, boolean validateIncompleteStatements) { if (validateIncompleteStatements) { buildAllStatements(); } // 这个mappedStatements便是在SqlSessionFactory进行build过程中parse解析出来的 return mappedStatements.get(id); } 方法二:UserMapper mapper = session.getMapper(UserMapper.class); 与 User user = mapper.selectById(1L); 源码流程: @Override public <T> T getMapper(Class<T> type) { return configuration.getMapper(type, this); } public <T> T getMapper(Class<T> type, SqlSession sqlSession) { return mapperRegistry.getMapper(type, sqlSession); } /** * 方法实现说明:通过class类型和sqlSessionTemplate获取Mapper(代理对象) * @param type:Mapper的接口类型 * @param sqlSession:接口类型实际上是我们的sqlSessionTemplate类型 */ @SuppressWarnings("unchecked") public <T> T getMapper(Class<T> type, SqlSession sqlSession) { // 直接去缓存knownMappers中通过Mapper的class类型去找mapperProxyFactory final MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type); // 缓存中没有获取到 直接抛出异常 if (mapperProxyFactory == null) { throw new BindingException("Type " + type + " is not known to the MapperRegistry."); } try { // 通过MapperProxyFactory来创建我们的实例 return mapperProxyFactory.newInstance(sqlSession); } catch (Exception e) { throw new BindingException("Error getting mapper instance. Cause: " + e, e); } }
【1.1.2.1】如果是定义了二级缓存,那么会走CachingExecutor逻辑:
/** * 方法实现说明:通过我们的sql执行器对象执行sql * @param ms 用于封装我们一个个的insert|delete|update|select 对象 * @param parameterObject:参数对象 * @param rowBounds :mybaits的逻辑分页对象 * @param resultHandler:结果处理器对象 */ @Override public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException { // 通过参数对象解析sql详细信息1339025938:1570540512:com.project.mapper.selectById:0:2147483647:select id,user_name,create_time from t_user where id=?:1:development BoundSql boundSql = ms.getBoundSql(parameterObject); CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql); return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); } @Override public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { //判断mapper中是否开启了二级缓存<cache></cache> Cache cache = ms.getCache(); // 判断是否配置了cache if (cache != null) { //判断是否需要刷新缓存 flushCacheIfRequired(ms); if (ms.isUseCache() && resultHandler == null) { ensureNoOutParams(ms, boundSql); // 先去二级缓存中获取 @SuppressWarnings("unchecked") List<E> list = (List<E>) tcm.getObject(cache, key); //也就是去PerpetualCache里面寻找 // 二级缓存中没有获取到 if (list == null) { //通过查询数据库去查询 list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); //加入到二级缓存中 tcm.putObject(cache, key, list); // issue #578 and #116 } return list; } } //没有整合二级缓存,直接去查询 return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); }
【1.1.2.1.1】事务的TransactionalCacheManager:
【1.1.2.1.1.1】它存在的意义在于:避免事务不成功的sql语句填充到了Cache里面,淘汰掉一些已经执行过的语句,相当于包装了一层。
【1.1.2.1.1.2】存储的地方:本质上会先存在自身类的属性值private final Map<Cache, TransactionalCache> transactionalCaches = new HashMap<>();
【1.1.2.1.1.3】当成功后才会提交到PerpetualCache里面。
【1.1.2.1.2】分析语句的解析【ms.getBoundSql(parameterObject)】:
public BoundSql getBoundSql(Object parameterObject) { BoundSql boundSql = sqlSource.getBoundSql(parameterObject); List<ParameterMapping> parameterMappings = boundSql.getParameterMappings(); if (parameterMappings == null || parameterMappings.isEmpty()) { boundSql = new BoundSql(configuration, boundSql.getSql(), parameterMap.getParameterMappings(), parameterObject); } // check for nested result maps in parameter mappings (issue #30) for (ParameterMapping pm : boundSql.getParameterMappings()) { String rmId = pm.getResultMapId(); if (rmId != null) { ResultMap rm = configuration.getResultMap(rmId); if (rm != null) { hasNestedResultMaps |= rm.hasNestedResultMaps(); } } } return boundSql; } //DynamicSqlSource类#getBoundSql方法 @Override public BoundSql getBoundSql(Object parameterObject) { DynamicContext context = new DynamicContext(configuration, parameterObject); //责任链处理SqlNode,编译出完整的sql rootSqlNode.apply(context); SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration); //处理sql中的#{..} Class<?> parameterType = parameterObject == null ? Object.class : parameterObject.getClass(); //将#{..}中的内容封装为parameterMapping,替换为? SqlSource sqlSource = sqlSourceParser.parse(context.getSql(), parameterType, context.getBindings()); BoundSql boundSql = sqlSource.getBoundSql(parameterObject); context.getBindings().forEach(boundSql::setAdditionalParameter); return boundSql; } //BoundSql类的结构 public class BoundSql { private final String sql; //语句 private final List<ParameterMapping> parameterMappings; private final Object parameterObject; //参数处理 private final Map<String, Object> additionalParameters; //结果集处理 private final MetaObject metaParameters; }
【1.1.2.2】如果没有定义的话,则会选择BaseExecutor的三个子类中的一个【但其实还是会走BaseExecutor的逻辑】:
//BaseExecutor类#query方法,子类重写的是doQuery,如果是使用query方法本质上还是走BaseExecutor类的 @Override public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId()); //已经关闭,则抛出 ExecutorException 异常 if (closed) { throw new ExecutorException("Executor was closed."); } // 清空本地缓存,如果 queryStack 为零,并且要求清空本地缓存。 if (queryStack == 0 && ms.isFlushCacheRequired()) { clearLocalCache(); } List<E> list; try { // 从一级缓存中,获取查询结果 queryStack++; //BaseExecutor类的属性值:protected PerpetualCache localCache; list = resultHandler == null ? (List<E>) localCache.getObject(key) : null; // 获取到,则进行处理 if (list != null) { //处理存过的 handleLocallyCachedOutputParameters(ms, key, parameter, boundSql); } else { // 获得不到,则从数据库中查询 list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql); } } finally { queryStack--; } if (queryStack == 0) { for (DeferredLoad deferredLoad : deferredLoads) { deferredLoad.load(); } // issue #601 deferredLoads.clear(); if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) { // issue #482 clearLocalCache(); } } return list; } //至于为什么会说一级缓存是session级别的,因为一旦提交或者回滚之后都会被清空 @Override public void commit(boolean required) throws SQLException { if (closed) { throw new ExecutorException("Cannot commit, transaction is already closed"); } clearLocalCache(); flushStatements(); if (required) { transaction.commit(); } } @Override public void rollback(boolean required) throws SQLException { if (!closed) { try { clearLocalCache(); flushStatements(true); } finally { if (required) { transaction.rollback(); } } } } // 清楚本地一级缓存 @Override public void clearLocalCache() { if (!closed) { localCache.clear(); localOutputParameterCache.clear(); } }
【1.1.2.3】分析queryFromDatabase方法:
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { List<E> list; //一级缓存中先占位 localCache.putObject(key, EXECUTION_PLACEHOLDER); try { //调用子类的查询方法 list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql); } finally { localCache.removeObject(key); } localCache.putObject(key, list); if (ms.getStatementType() == StatementType.CALLABLE) { localOutputParameterCache.putObject(key, parameter); } return list; } //以默认的SimpleExecutor为例查看doQuery方法 @Override public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException { Statement stmt = null; try { Configuration configuration = ms.getConfiguration(); //创建StatementHandler,主要职责是拿到链接,拿到执行者 StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql); stmt = prepareStatement(handler, ms.getStatementLog()); return handler.query(stmt, resultHandler); } finally { closeStatement(stmt); } } //分析如何创建StatementHandler public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) { StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql); statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler); return statementHandler; } //存在三种StatementHandler public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) { switch (ms.getStatementType()) { case STATEMENT: delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql); break; case PREPARED: delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql); break; case CALLABLE: delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql); break; default: throw new ExecutorException("Unknown statement type: " + ms.getStatementType()); } } //但是这三种都是继承BaseStatementHandler,因为BaseStatementHandler里面才会有resultSetHandler和parameterHandler protected BaseStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) { this.configuration = mappedStatement.getConfiguration(); this.executor = executor; this.mappedStatement = mappedStatement; this.rowBounds = rowBounds; this.typeHandlerRegistry = configuration.getTypeHandlerRegistry(); this.objectFactory = configuration.getObjectFactory(); if (boundSql == null) { // issue #435, get the key before calculating the statement generateKeys(parameterObject); boundSql = mappedStatement.getBoundSql(parameterObject); } this.boundSql = boundSql; this.parameterHandler = configuration.newParameterHandler(mappedStatement, parameterObject, boundSql); this.resultSetHandler = configuration.newResultSetHandler(executor, mappedStatement, rowBounds, parameterHandler, resultHandler, boundSql); }
【2.2】对于执行器Executor的分析,先分析接口的定义:
/** * 类的描述:sql执行器接口,主要用于维护一级缓存和二级缓存,并且提供事务管理功能 * Executor * --BaseExecutor(一级缓存) * --batchExecutor(批量执行器) * --ReUseExecutor(可重用的) * --SimpleExecutor简单的 * --CacheExecutor(加入了二级缓存) */ public interface Executor { //ResultHandler 对象的枚举 ResultHandler NO_RESULT_HANDLER = null; /** * 更新 or 插入 or 删除,由传入的 MappedStatement 的 SQL 所决定 * @param ms 我们的执行sql包装对象(MappedStatement) * @param parameter 执行的参数 */ int update(MappedStatement ms, Object parameter) throws SQLException; /** * 查询带缓存key查询 * @param ms 我们的执行sql包装对象(MappedStatement) * @param parameter:参数 * @param rowBounds 逻辑分页参数 * @param resultHandler:返回结果处理器 * @param cacheKey:缓存key * @param boundSql:我们的sql对象 * @return 查询结果集list * @throws SQLException */ <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey cacheKey, BoundSql boundSql) throws SQLException; /** * 不走缓存查询 * @param ms 我们的执行sql包装对象(MappedStatement) * @param parameter:参数 * @param rowBounds 逻辑分页参数 * @param resultHandler:返回结果处理器 * @return 结果集list * @throws SQLException */ <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException; /** * 调用存过查询返回游标对象 * @param ms 我们的执行sql包装对象(MappedStatement) * @param parameter:参数 * @param rowBounds 逻辑分页参数 * @return Cursor数据库游标 * @throws SQLException */ <E> Cursor<E> queryCursor(MappedStatement ms, Object parameter, RowBounds rowBounds) throws SQLException; // 刷入批处理语句 List<BatchResult> flushStatements() throws SQLException; //提交事务 void commit(boolean required) throws SQLException; //回滚事务 void rollback(boolean required) throws SQLException; //创建缓存key CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql); // 判断是否缓存 boolean isCached(MappedStatement ms, CacheKey key); // 清除本地缓存 void clearLocalCache(); // 延迟加载 void deferLoad(MappedStatement ms, MetaObject resultObject, String property, CacheKey key, Class<?> targetType); //获取一个事务 Transaction getTransaction(); // 关闭事务 void close(boolean forceRollback); //判断是否关闭 boolean isClosed(); // 设置包装的 Executor 对象 void setExecutorWrapper(Executor executor); }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号