MyBatis详解(一)
MyBatis简单介绍
【1】MyBatis是一个持久层的ORM框架【Object Relational Mapping,对象关系映射】,使用简单,学习成本较低。可以执行自己手写的SQL语句,比较灵活。但是MyBatis的自动化程度不高,移植性也不高,有时从一个数据库迁移到另外一个数据库的时候需要自己修改配置,所以称只为半自动ORM框架。
传统JDBC介绍
【1】简单使用
@Test public void test() throws SQLException { Connection conn=null; PreparedStatement pstmt=null; try { // 1.加载驱动,其实这一步可以不加因为DriverManager里面会有自动加载驱动的一步 Class.forName("com.mysql.jdbc.Driver"); // 2.创建连接 conn= DriverManager.getConnection("jdbc:mysql://localhost:3306/mybatis_example", "root", "123456"); //开启事务 conn.setAutoCommit(false); // SQL语句 String sql="select id,user_name,create_time from t_user where id=? "; // 获得sql执行者 pstmt=conn.prepareStatement(sql); pstmt.setInt(1,1); // 执行查询 //ResultSet rs= pstmt.executeQuery(); pstmt.execute(); ResultSet rs= pstmt.getResultSet(); rs.next(); User user =new User(); user.setId(rs.getLong("id")); user.setUserName(rs.getString("user_name")); user.setCreateTime(rs.getDate("create_time")); System.out.println(user.toString()); } catch (Exception e) { e.printStackTrace(); } finally{ // 关闭资源 try { if(conn!=null){ conn.close(); } if(pstmt!=null){ pstmt.close(); } } catch (SQLException e) { e.printStackTrace(); } } }
【1.1】DriverManager如何自动加载驱动【利用静态代码块调用初始化方法,至于为什么要使用SPI机制,主要是为了实现解耦和可插拔,因为驱动有多种】
注:驱动展示【位于mysql-connector-java-5.1.22.jar/META-INF/services/java.sql.Driver 内容为:com.mysql.jdbc.Driver】
static { // 启动类加载器加载DriverManager类,触发静态方法执行 loadInitialDrivers(); println("JDBC DriverManager initialized"); } private static void loadInitialDrivers() { String drivers; try { drivers = AccessController.doPrivileged(new PrivilegedAction<String>() { public String run() { return System.getProperty("jdbc.drivers"); } }); } catch (Exception ex) { drivers = null; } // 加载java.sql.Driver驱动的实现 AccessController.doPrivileged(new PrivilegedAction<Void>() { public Void run() { // 1、创建一个 ServiceLoader对象,【这里就将上下文类加载器设置到ServiceLoader对象的变量上了】 ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class); // 2、创建一个迭代器对象 Iterator<Driver> driversIterator = loadedDrivers.iterator(); try{ // 3、这里调用driversIterator.hasNext()的时候,触发将 META-INF/services 下的配置文件中的数据读取进来,方便下面的next方法使用 while(driversIterator.hasNext()) { // 4、【关键】:触发上面创建的迭代器对象的方法调用。这里才是具体加载的实现逻辑,非常不好找 driversIterator.next(); } } catch(Throwable t) {} return null; } }); //判断有没有加载到 if (drivers == null || drivers.equals("")) { return; } String[] driversList = drivers.split(":"); println("number of Drivers:" + driversList.length); for (String aDriver : driversList) { try { println("DriverManager.Initialize: loading " + aDriver); Class.forName(aDriver, true, ClassLoader.getSystemClassLoader()); } catch (Exception ex) {...} } } //ServiceLoader类#hasNext方法 public boolean hasNext() { if (acc == null) { return hasNextService(); } else { PrivilegedAction<Boolean> action = new PrivilegedAction<Boolean>() { public Boolean run() { return hasNextService(); } }; return AccessController.doPrivileged(action, acc); } } private boolean hasNextService() { if (nextName != null) { return true; } if (configs == null) { try { // 1、拼凑要读取的文件的全名 // final String PREFIX = "META-INF/services/"; String fullName = PREFIX + service.getName(); // 2、根据 fullName 去到META-INF/services/目录下寻找配置文件 // 如果类加载器为空,则使用系统类加载器,如果不为空则使用指定的类加载器 if (loader == null) configs = ClassLoader.getSystemResources(fullName); else configs = loader.getResources(fullName); } catch (IOException x) { fail(service, "Error locating configuration files", x); } } while ((pending == null) || !pending.hasNext()) { if (!configs.hasMoreElements()) { return false; } // 3、使用parse方法解析配置文件中的每一行数据 pending = parse(service, configs.nextElement()); } nextName = pending.next(); return true; }
【2】当然正常情况一般是封装成类来使用的,如
//数据访问基类 public class BaseDao { // 驱动 private static String DRIVER = null; // 链接字符串 private static String URL = null; // 用户名 private static String USERNAME = null; // 密码 private static String PASSWORD = null; //初始化 static { init(); } // 初始化 private static void init() { try { // 使用Properties对象读取资源文件属性 Properties pro = new Properties(); // 获得资源文件输入流 InputStream inStream = BaseDao.class.getClassLoader().getResourceAsStream("db.properties"); // 加载输入流 pro.load(inStream); DRIVER = pro.getProperty("mysql.driverClass"); URL = pro.getProperty("mysql.jdbcUrl"); USERNAME = pro.getProperty("mysql.user"); PASSWORD = pro.getProperty("mysql.password"); Class.forName(DRIVER); } catch (Exception e) { e.printStackTrace(); } } //获取数据库连接对象 protected Connection getConnection() { Connection conn = null; try { conn = DriverManager.getConnection(URL, USERNAME, PASSWORD); } catch (SQLException e) { // TODO Auto-generated catch block e.printStackTrace(); } return conn; } /** * 关闭所有链接 * @param conn * @param stmt * @param rs */ protected void CloseAll(Connection conn, Statement stmt, ResultSet rs) { try { if (conn != null) { conn.close(); } if (stmt != null) { stmt.close(); } if (rs != null) { rs.close(); } } catch (SQLException e) { // TODO Auto-generated catch block e.printStackTrace(); } } /** * 执行 增、删、 改的公共方法 * @param sql SQL语句 * @param prams 参数 * @return 受影响的行数 */ protected int executeUpdate(String sql, Object... prams) { // 获得数据库链接对象 Connection conn = getConnection(); // 声明SQL执行者 PreparedStatement pstmt = null; try { // 获得SQL执行者 pstmt = conn.prepareStatement(sql); // 循环加载参数 for (int i = 0; i < prams.length; i++) { pstmt.setObject(i + 1, prams[i]); } // 执行executeUpdate 返回受影响行数 return pstmt.executeUpdate(); } catch (SQLException e) { e.printStackTrace(); } finally { // 关闭所有需要关闭的对象 CloseAll(conn, pstmt, null); } return 0; } /** * 执行查询 返回单个值 * @param sql SQL语句 * @param prams 参数 * @return OBJECT */ protected Object executeScaler(String sql, Object... prams) { // 获得数据库链接对象 Connection conn = getConnection(); // 声明SQL执行者 PreparedStatement pstmt = null; // 声明查询结果集 ResultSet rs = null; // 接收单个值 Object value = null; try { // 获得SQL执行者 pstmt = conn.prepareStatement(sql); // 循环加载参数 for (int i = 0; i < prams.length; i++) { pstmt.setObject(i + 1, prams[i]); } // 执行executeUpdate 返回受影响行数 rs = pstmt.executeQuery(); if (rs.next()) { value = rs.getObject(1); } } catch (SQLException e) { e.printStackTrace(); } finally { CloseAll(conn, pstmt, rs); } return value; } /** * 执行查询返回list * * @param sql SQL语句 * @param clazz 类的类型 * @return List */ public <T> List<T> executeList(String sql, Class<T> clazz, Object... prams) { // 数据集合 List<T> list = new ArrayList<T>(); // 获得数据库连接 Connection conn = getConnection(); // 声明SQL执行者 PreparedStatement pstmt = null; // 声明查询结果集 ResultSet rs = null; try { // 3. 通过链接创建一个SQL执行者 pstmt = conn.prepareStatement(sql); // 循环加载参数 for (int i = 0; i < prams.length; i++) { //内部会通过instance of判断这个参数到底是哪个类型的具体对象 pstmt.setObject(i + 1, prams[i]); } // 4 执行查询SQL 返回查询结果 rs = pstmt.executeQuery(); // 获得结果集的列信息对象 ResultSetMetaData rsmd = rs.getMetaData(); while (rs.next()) { // 通过类反射实例化 T obj = clazz.newInstance(); // 循环所有的列 for (int i = 1; i <= rsmd.getColumnCount(); i++) { /* 通过属性名称使用反射给泛型实例赋值 Begin */ // 获得每一列的列名 String cloName = rsmd.getColumnName(i); // 根据列名反射到类的字段 Field filed = clazz.getDeclaredField(cloName); // 设置私有属性的访问权限 filed.setAccessible(true); // 给泛型实例的某一个属性赋值 filed.set(obj, rs.getObject(cloName)); /* 通过属性名称使用反射给泛型实例赋值 End */ } // 将泛型实例添加到 泛型集合中 list.add(obj); } } catch (Exception e) { e.printStackTrace(); } return list; } /** * 执行查询返回JavaBean * * @param sql SQL语句 * @param clazz 类的类型 * @return JavaBean */ public <T> T executeJavaBean(String sql, Class<T> clazz, Object... prams) { // 声明数据对象 T obj=null; // 获得数据库连接 Connection conn = getConnection(); // 声明SQL执行者 PreparedStatement pstmt = null; // 声明查询结果集 ResultSet rs = null; try { // 3. 通过链接创建一个SQL执行者 pstmt = conn.prepareStatement(sql); // 循环加载参数 for (int i = 0; i < prams.length; i++) { pstmt.setObject(i + 1, prams[i]); } // 4 执行查询SQL 返回查询结果 rs = pstmt.executeQuery(); // 获得结果集的列信息对象 ResultSetMetaData rsmd = rs.getMetaData(); if (rs.next()) { // 通过类反射实例化 obj = clazz.newInstance(); // 循环所有的列 for (int i = 1; i <= rsmd.getColumnCount(); i++) { /* 通过属性名称使用反射给泛型实例赋值 Begin */ // 获得每一列的列名 String cloName = rsmd.getColumnName(i); // 根据列名反射到类的字段 Field filed = clazz.getDeclaredField(cloName); // 设置私有属性的访问权限 filed.setAccessible(true); // 给泛型实例的某一个属性赋值 filed.set(obj, rs.getObject(cloName)); /* 通过属性名称使用反射给泛型实例赋值 End */ } } } catch (Exception e) { e.printStackTrace(); } return obj; } }
【3】总结JDBC的四大核心对象
1)DriverManager(驱动管理对象):获取数据库连接;
2)Connection(数据库连接对象):获取执行sql对象;管理事务;
3)Statement(执行sql对象):executeUpdate执行DML语句(增删改)DDL语句;executeQuery 执行DQL语句;
4)ResultSet(结果集对象):
【4】传统JDBC的问题
1)数据库连接创建,释放频繁造成西戎资源的浪费,从而影响系统性能,使用数据库连接池可以解决问题。
2)sql语句在代码中硬编码,造成代码的不已维护,实际应用中sql的变化可能较大,sql代码和java代码没有分离开来维护不方便。
3)使用preparedStatement向有占位符传递参数存在硬编码问题因为sql中的where子句的条件不确定,同样是修改不方便。
4)对结果集中解析存在硬编码问题,sql的变化导致解析代码的变化,系统维护不方便。
【5】针对问题的优化
1、数据库连接创建、释放频繁造成系统资源浪费从而影响系统性能,如果使用数据库连接池可解决此问题。
优化部分,如mybatis:在SqlMapConfig.xml中配置数据连接池,使用连接池管理数据库链接。
2、Sql语句写在代码中造成代码不易维护,实际应用sql变化的可能较大,sql变动需要改变java代码。
优化部分,如mybatis:将Sql语句配置在XXXXmapper.xml文件中与java代码分离。
3、向sql语句传参数麻烦,因为sql语句的where条件不一定,可能多也可能少,占位符需要和参数一一对应。
优化部分,如mybatis:自动将java对象映射至sql语句,通过statement中的parameterType定义输入参数的类型。
4、对结果集解析麻烦,sql变化导致解析代码变化,且解析前需要遍历,如果能将数据库记录封装成pojo对象解析比较方便。
优化部分,如mybatis:自动将sql执行结果映射至java对象,通过statement中的resultType定义输出结果的类型。
Mybaits整体体系图
【1】图示
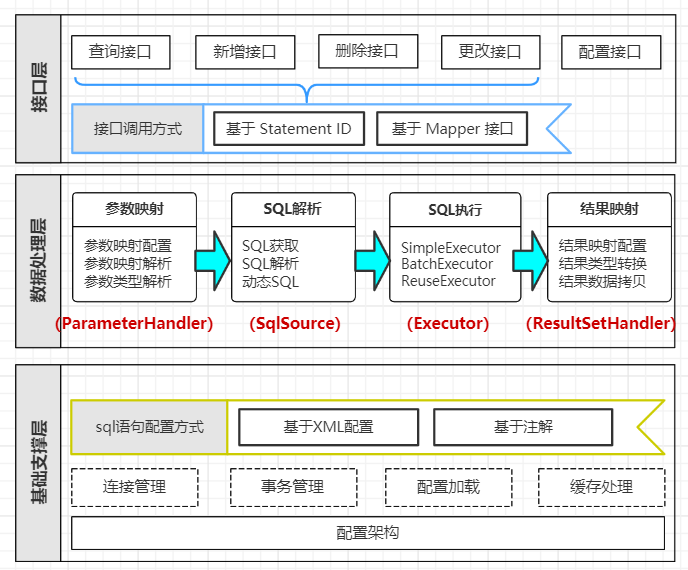
【2】分析
把Mybatis的功能架构分为三层:
1)基础支撑层:负责最基础的功能支撑,包括连接管理、事务管理、配置加载和缓存处理,这些都是共用的东西,将他们抽取出来作为最基础的组件。为上层的数据处理层提供最基础的支撑。
对应示例中的部分为: SqlSessionFactory sqlMapper = new SqlSessionFactoryBuilder().build(reader);
2)API接口层:提供给外部使用的接口API,开发人员通过这些本地API来操纵数据库。接口层一接收到调用请求就会调用数据处理层来完成具体的数据处理。
对应示例中的部分为: SqlSession session = sqlMapper.openSession();
3)数据处理层:负责具体的SQL查找、SQL解析、SQL执行和执行结果映射处理等。它主要的目的是根据调用的请求完成一次数据库操作。
对应示例中的部分为:
User user = (User)session.selectOne("com.mapper.UserMapper.selectById", 1);
或者
UserMapper mapper = session.getMapper(UserMapper.class);
User user = mapper.selectById(1L);
【3】简单示例
public static void main(String[] args) { String resource = "mybatis-config.xml"; Reader reader; try { //将XML配置文件构建为Configuration配置类 reader = Resources.getResourceAsReader(resource); // 通过加载配置文件流构建一个SqlSessionFactory DefaultSqlSessionFactory SqlSessionFactory sqlMapper = new SqlSessionFactoryBuilder().build(reader); // 数据源 执行器 DefaultSqlSession SqlSession session = sqlMapper.openSession(); try { // 执行查询 底层执行jdbc //User user = (User)session.selectOne("com.mapper.UserMapper.selectById", 1); UserMapper mapper = session.getMapper(UserMapper.class); User user = mapper.selectById(1L); session.commit(); System.out.println(user.getUserName()); } catch (Exception e) { e.printStackTrace(); }finally { session.close(); } } catch (IOException e) { e.printStackTrace(); } }
Mybaits插件的分析
【1】插件主要作用于四⼤组件对象
1)执⾏器 Executor (update, query, flushStatements, commit, rollback, getTransaction, close, isClosed 等⽅法)
2)参数处理器 ParameterHandler (getParameterObject, setParameters 等⽅法)
3)结果集处理器 ResultSetHandler (handleResultSets, handleOutputParameters 等⽅法)
4)SQL语法构建处理器 StatementHandler (prepare, parameterize, batch, update, query 等⽅法)
源码分析部分
MyBatis解析全局配置文件的源码分析
【1】分析怎么通过加载配置文件流构建一个SqlSessionFactory
public SqlSessionFactory build(Reader reader) { return build(reader, null, null); } public SqlSessionFactory build(Reader reader, String environment, Properties properties) { try { XMLConfigBuilder parser = new XMLConfigBuilder(reader, environment, properties); return build(parser.parse()); } catch (Exception e) { throw ExceptionFactory.wrapException("Error building SqlSession.", e); } finally { ErrorContext.instance().reset(); try { reader.close(); } catch (IOException e) { // Intentionally ignore. Prefer previous error. } } } // 到这里配置文件已经解析成了Configuration public SqlSessionFactory build(Configuration config) { return new DefaultSqlSessionFactory(config); }
【1.1】分析XMLConfigBuilder类怎么将xml的资源文件流解析成Configuration:
【1.1.1】新建XMLConfigBuilder过程【所以说XMLConfigBuilder并不负责解析,解析的是它里面的XPathParser类,】
/** * 创建一个用于解析xml配置的构建器对象 * @param inputStream 传入进来的xml的配置 * @param environment 我们的环境变量 * @param props:用于保存我们从xml中解析出来的属性 */ public XMLConfigBuilder(InputStream inputStream, String environment, Properties props) { /** * 该方法做了二个事情 * 第一件事情:创建XPathParser 解析器对象,在这里会把我们的 * 把我们的mybatis-config.xml解析出一个Document对象 * 第二节事情:调用重写的构造函数来构建我XMLConfigBuilder */ this(new XPathParser(inputStream, true, props, new XMLMapperEntityResolver()), environment, props); } private XMLConfigBuilder(XPathParser parser, String environment, Properties props) { //调用父类的BaseBuilder的构造方法:给configuration赋值,typeAliasRegistry别名注册器赋值,TypeHandlerRegistry赋值 super(new Configuration()); ErrorContext.instance().resource("SQL Mapper Configuration"); //把props绑定到configuration的props属性上 this.configuration.setVariables(props); this.parsed = false; this.environment = environment; this.parser = parser; } //又因为class XMLConfigBuilder extends BaseBuilder,所以看一下他的父类 public abstract class BaseBuilder { // mybatis的全局配置文件 protected final Configuration configuration; // 用于保存我们的Entity的别名 protected final TypeAliasRegistry typeAliasRegistry; // 用户保存我们java类型和jdbc数据库类型的 protected final TypeHandlerRegistry typeHandlerRegistry; public BaseBuilder(Configuration configuration) { this.configuration = configuration; this.typeAliasRegistry = this.configuration.getTypeAliasRegistry(); this.typeHandlerRegistry = this.configuration.getTypeHandlerRegistry(); } .... }
【1.1.2】parser.parse()解析过程【本质上就是从根结点开始解析】
public Configuration parse() { //若已经解析过了 就抛出异常 if (parsed) { throw new BuilderException("Each XMLConfigBuilder can only be used once."); } //设置解析标志位,保证只解析一次 parsed = true; /** * 解析我们的mybatis-config.xml的节点 * <configuration> </configuration> */ parseConfiguration(parser.evalNode("/configuration")); return configuration; } //方法实现说明:解析我们mybatis-config.xml的 configuration节点 private void parseConfiguration(XNode root) { try { // 解析 properties节点 // 如:<properties resource="mybatis/db.properties" /> propertiesElement(root.evalNode("properties")); // 解析我们的mybatis-config.xml中的settings节点 // 如:<setting name="mapUnderscoreToCamelCase" value="false"/> Properties settings = settingsAsProperties(root.evalNode("settings")); // 基本没有用过该属性 // VFS含义是虚拟文件系统;主要是通过程序能够方便读取本地文件系统、FTP文件系统等系统中的文件资源。 // Mybatis中提供了VFS这个配置,主要是通过该配置可以加载自定义的虚拟文件系统应用程序 loadCustomVfs(settings); // 指定 MyBatis 所用日志的具体实现,未指定时将自动查找。 // SLF4J | LOG4J | LOG4J2 | JDK_LOGGING | COMMONS_LOGGING | STDOUT_LOGGING | NO_LOGGING // 解析到org.apache.ibatis.session.Configuration#logImpl loadCustomLogImpl(settings); // 解析别名typeAliases节点 typeAliasesElement(root.evalNode("typeAliases")); // 解析插件节点(比如分页插件),解析到 interceptorChain.interceptors pluginElement(root.evalNode("plugins")); objectFactoryElement(root.evalNode("objectFactory")); objectWrapperFactoryElement(root.evalNode("objectWrapperFactory")); reflectorFactoryElement(root.evalNode("reflectorFactory")); // 设置settings 到 configuration 里面 settingsElement(settings); // 解析mybatis环境,解析到:org.apache.ibatis.session.Configuration#environment // 在集成spring情况下由 spring-mybatis提供数据源 和事务工厂 environmentsElement(root.evalNode("environments")); // 解析数据库厂商 databaseIdProviderElement(root.evalNode("databaseIdProvider")); // 解析类型处理器节点 typeHandlerElement(root.evalNode("typeHandlers")); // 解析mapper节点(这个是最重要的) mapperElement(root.evalNode("mappers")); } catch (Exception e) { throw new BuilderException(...); } }
【1.1.2.1】展示xml配置文件与Mapper文件
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> <!-- properties 扫描属性文件.properties --> <properties resource="db.properties"></properties> <!-- 具体可以配置哪些属性:http://www.mybatis.org/mybatis-3/zh/configuration.html#settings --> <settings> <!-- 把数据库字段映射为驼峰式的字段 --> <setting name="mapUnderscoreToCamelCase" value="true"/> <!-- 内部的属性可以配置日志,常用的日志是:LOG4J 、 STDOUT_LOGGING,用于打印执行的sql语句长什么样 --> <setting name="logImpl" value="LOG4J"/> <!-- <setting name="cacheEnabled" value="true"/>--> <!-- <setting name="lazyLoadingEnabled" value="true"/>--> <!-- <setting name="localCacheScope" value="SESSION"/>--> <!-- <setting name="jdbcTypeForNull" value="OTHER"/>--> </settings> <!-- 别名设置,常有单个设置【如com.project.entity.User,就是类的全路径】,或者按路径设置,本质上就是将其设置于 Configuration 或者 BaseBuilder中,可以用于查询返回结果的映射 --> <!-- <typeAliases>--> <!-- <typeAlias alias="User" type="com.project.entity.User"/>--> <!-- </typeAliases>--> <!-- <typeAliases>--> <!-- <package name="com.project.entity"/>--> <!-- </typeAliases>--> <!-- 插件设置 --> <!-- <plugins> <plugin interceptor="com.project.plugins.ExamplePlugin" ></plugin> </plugins>--> <!-- 类型处理器设置 --> <typeHandlers> <typeHandler handler="org.mybatis.example.ExampleTypeHandler"/> </typeHandlers> <environments default="development"> <environment id="development"> <transactionManager type="JDBC"/> <!--// mybatis内置了JNDI、POOLED、UNPOOLED三种类型的数据源,其中POOLED对应的实现为org.apache.ibatis.datasource.pooled.PooledDataSource,它是mybatis自带实现的一个同步、线程安全的数据库连接池 一般在生产中,我们会使用c3p0或者druid连接池--> <dataSource type="POOLED"> <property name="driver" value="${mysql.driverClass}"/> <property name="url" value="${mysql.jdbcUrl}"/> <property name="username" value="${mysql.user}"/> <property name="password" value="${mysql.password}"/> </dataSource> </environment> </environments> <mappers> <!-- resource:注册class类路径下的--> <mapper resource="mybatis/mapper/EmployeeMapper.xml"/> <mapper class="com.project.mapper.DeptMapper"></mapper> <package name="com.mapper"/> </mappers> </configuration>
【1.1.2.2】部分内容分析:
【1.1.2.2.1】解析 properties节点
// 本质上这个分离方式便是为了解耦 // 大体上看来加载properties有两种,一种是本地文件,一种是远程文件 // 而且加载出来的数据其实是会放置于configuration属性里面的,也就是XMLConfigBuilder类里面 private void propertiesElement(XNode context) throws Exception { if (context != null) { Properties defaults = context.getChildrenAsProperties(); String resource = context.getStringAttribute("resource"); String url = context.getStringAttribute("url"); if (resource != null && url != null) { throw new BuilderException("The properties element cannot specify both a URL and a resource based property file reference. Please specify one or the other."); } if (resource != null) { defaults.putAll(Resources.getResourceAsProperties(resource)); } else if (url != null) { defaults.putAll(Resources.getUrlAsProperties(url)); } Properties vars = configuration.getVariables(); if (vars != null) { defaults.putAll(vars); } parser.setVariables(defaults); configuration.setVariables(defaults); } } //下面便展示一下db.properties的常用内容 mysql.driverClass=com.mysql.jdbc.Driver mysql.jdbcUrl=jdbc:mysql://localhost:3306/mybatis_example?characterEncoding=utf8 mysql.user= root mysql.password= 123456
【1.1.2.2.2】解析我们的mybatis-config.xml中的settings节点
private Properties settingsAsProperties(XNode context) { if (context == null) { return new Properties(); } //分析配置的节点 Properties props = context.getChildrenAsProperties(); // 其实就是去configuration类里面拿到所有setter方法,看看有没有当前的配置项 MetaClass metaConfig = MetaClass.forClass(Configuration.class, localReflectorFactory); for (Object key : props.keySet()) { if (!metaConfig.hasSetter(String.valueOf(key))) { throw new BuilderException("The setting " + key + " is not known. Make sure you spelled it correctly (case sensitive)."); } } return props; }
【1.1.2.2.3】解析别名typeAliases节点
// 别名设置,别名设置最常用的就是对于entity【也就是实体类对象】 // 常常作用域Mapper的resultMap属性,也就是查询结果的映射,映射到对于的实体类上 // 由下面分析可以看出来是具备单个或者对包类路径的扫描 private void typeAliasesElement(XNode parent) { if (parent != null) { for (XNode child : parent.getChildren()) { if ("package".equals(child.getName())) { String typeAliasPackage = child.getStringAttribute("name"); configuration.getTypeAliasRegistry().registerAliases(typeAliasPackage); } else { String alias = child.getStringAttribute("alias"); String type = child.getStringAttribute("type"); try { Class<?> clazz = Resources.classForName(type); if (alias == null) { typeAliasRegistry.registerAlias(clazz); } else { typeAliasRegistry.registerAlias(alias, clazz); } } catch (ClassNotFoundException e) { throw new BuilderException("Error registering typeAlias for '" + alias + "'. Cause: " + e, e); } } } } }
【1.1.2.2.4】解析插件节点(比较重要)
// 对于插件的解析,很明显的有用到装饰器模式的概念,其实都是封装成了interceptor // 然后统一存放于configuration里面 private void pluginElement(XNode parent) throws Exception { if (parent != null) { for (XNode child : parent.getChildren()) { String interceptor = child.getStringAttribute("interceptor"); Properties properties = child.getChildrenAsProperties(); Interceptor interceptorInstance = (Interceptor) resolveClass(interceptor).getDeclaredConstructor().newInstance(); interceptorInstance.setProperties(properties); configuration.addInterceptor(interceptorInstance); } } } //实际上是封装成了这个类,因为Interceptor是接口,是不具备实例化能力的 @Intercepts({}) public class ExamplePlugin implements Interceptor { private Properties properties; @Override public Object intercept(Invocation invocation) throws Throwable { return invocation.proceed(); } @Override public Object plugin(Object target) { return Plugin.wrap(target, this); } @Override public void setProperties(Properties properties) { this.properties = properties; } public Properties getProperties() { return properties; } }
【1.1.2.2.5】解析mybatis环境
//这里面主要的就是事务工厂和数据源的设置 private void environmentsElement(XNode context) throws Exception { if (context != null) { if (environment == null) { environment = context.getStringAttribute("default"); } for (XNode child : context.getChildren()) { String id = child.getStringAttribute("id"); if (isSpecifiedEnvironment(id)) { TransactionFactory txFactory = transactionManagerElement(child.evalNode("transactionManager")); DataSourceFactory dsFactory = dataSourceElement(child.evalNode("dataSource")); DataSource dataSource = dsFactory.getDataSource(); Environment.Builder environmentBuilder = new Environment.Builder(id) .transactionFactory(txFactory) .dataSource(dataSource); configuration.setEnvironment(environmentBuilder.build()); } } } } //展示一下一般可以在xml里面怎么配置 <environments default="dev"> <environment id="dev"> <transactionManager type="JDBC"/> <dataSource type="POOLED"> <property name="driver" value="${jdbc.driver}"/> <property name="url" value="${jdbc.url}"/> <property name="username" value="root"/> <property name="password" value="Zw726515"/> </dataSource> </environment> <environment id="test"> <transactionManager type="JDBC"/> <dataSource type="POOLED"> <property name="driver" value="${jdbc.driver}"/> <property name="url" value="${jdbc.url}"/> <property name="username" value="root"/> <property name="password" value="123456"/> </dataSource> </environment> </environments> //其实里面的JDBC和POOLED是怎么来的呢,都是源于别名那部分的,在Configuration类构造函数里面,他就会为别名里面注册一部分常用数据 public Configuration() { typeAliasRegistry.registerAlias("JDBC", JdbcTransactionFactory.class); typeAliasRegistry.registerAlias("MANAGED", ManagedTransactionFactory.class); typeAliasRegistry.registerAlias("JNDI", JndiDataSourceFactory.class); typeAliasRegistry.registerAlias("POOLED", PooledDataSourceFactory.class); typeAliasRegistry.registerAlias("UNPOOLED", UnpooledDataSourceFactory.class); typeAliasRegistry.registerAlias("PERPETUAL", PerpetualCache.class); typeAliasRegistry.registerAlias("FIFO", FifoCache.class); typeAliasRegistry.registerAlias("LRU", LruCache.class); typeAliasRegistry.registerAlias("SOFT", SoftCache.class); typeAliasRegistry.registerAlias("WEAK", WeakCache.class); typeAliasRegistry.registerAlias("DB_VENDOR", VendorDatabaseIdProvider.class); typeAliasRegistry.registerAlias("XML", XMLLanguageDriver.class); typeAliasRegistry.registerAlias("RAW", RawLanguageDriver.class); typeAliasRegistry.registerAlias("SLF4J", Slf4jImpl.class); typeAliasRegistry.registerAlias("COMMONS_LOGGING", JakartaCommonsLoggingImpl.class); typeAliasRegistry.registerAlias("LOG4J", Log4jImpl.class); typeAliasRegistry.registerAlias("LOG4J2", Log4j2Impl.class); typeAliasRegistry.registerAlias("JDK_LOGGING", Jdk14LoggingImpl.class); typeAliasRegistry.registerAlias("STDOUT_LOGGING", StdOutImpl.class); typeAliasRegistry.registerAlias("NO_LOGGING", NoLoggingImpl.class); typeAliasRegistry.registerAlias("CGLIB", CglibProxyFactory.class); typeAliasRegistry.registerAlias("JAVASSIST", JavassistProxyFactory.class); languageRegistry.setDefaultDriverClass(XMLLanguageDriver.class); languageRegistry.register(RawLanguageDriver.class); }
【1.1.2.2.6】类型处理器解析
private void typeHandlerElement(XNode parent) { if (parent != null) { for (XNode child : parent.getChildren()) { // 根据包类路径注册 if ("package".equals(child.getName())) { String typeHandlerPackage = child.getStringAttribute("name"); typeHandlerRegistry.register(typeHandlerPackage); } else { //根据单个进行注册,属性有 handler(处理器) ,jdbcType(对应数据库类型) ,javaType(对应java类型) String javaTypeName = child.getStringAttribute("javaType"); String jdbcTypeName = child.getStringAttribute("jdbcType"); String handlerTypeName = child.getStringAttribute("handler"); Class<?> javaTypeClass = resolveClass(javaTypeName); JdbcType jdbcType = resolveJdbcType(jdbcTypeName); Class<?> typeHandlerClass = resolveClass(handlerTypeName); if (javaTypeClass != null) { if (jdbcType == null) { typeHandlerRegistry.register(javaTypeClass, typeHandlerClass); } else { typeHandlerRegistry.register(javaTypeClass, jdbcType, typeHandlerClass); } } else { typeHandlerRegistry.register(typeHandlerClass); } } } } }
【1.1.2.2.7】最重要的mapper解析,明显是有四种类型:
private void mapperElement(XNode parent) throws Exception { if (parent != null) { // 获取我们mappers节点下的一个一个的mapper节点 for (XNode child : parent.getChildren()) { // 判断我们mapper是不是通过批量注册的,如<package name="com.project.mapper"></package> if ("package".equals(child.getName())) { String mapperPackage = child.getStringAttribute("name"); configuration.addMappers(mapperPackage); } else { // 判断从classpath下读取我们的mapper,如<mapper resource="mybatis/mapper/EmployeeMapper.xml"/> String resource = child.getStringAttribute("resource"); // 判断是不是从我们的网络资源读取(或者本地磁盘得),如<mapper url="D:/mapper/EmployeeMapper.xml"/> String url = child.getStringAttribute("url"); // 解析这种类型(要求接口和xml在同一个包下),如<mapper class="com.project.mapper.DeptMapper"></mapper> String mapperClass = child.getStringAttribute("class"); // 拿<mapper resource="mybatis/mapper/EmployeeMapper.xml"/>这种进行分析 if (resource != null && url == null && mapperClass == null) { ErrorContext.instance().resource(resource); // 把我们的文件读取出一个流 InputStream inputStream = Resources.getResourceAsStream(resource); // 创建读取XmlMapper构建器对象,用于来解析我们的mapper.xml文件 XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments()); // 真正的解析我们的mapper.xml配置文件(说白了就是来解析我们的sql) mapperParser.parse(); } else if (resource == null && url != null && mapperClass == null) { // 这种从网络资源读取,与上面的大体一致就不解释了 ErrorContext.instance().resource(url); InputStream inputStream = Resources.getUrlAsStream(url); XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, url, configuration.getSqlFragments()); mapperParser.parse(); } else if (resource == null && url == null && mapperClass != null) { Class<?> mapperInterface = Resources.classForName(mapperClass); configuration.addMapper(mapperInterface); } else { // 都不是则抛出异常 throw new BuilderException(...); } } } } }
【1.1.2.2.7.1】分析addMapper方法最后是怎么解析的
// MapperRegistry类的两个属性值 // private final Configuration config; // private final Map<Class<?>, MapperProxyFactory<?>> knownMappers = new HashMap<>(); //Configuration类#addMapper方法 // 传入包路径的方法 public void addMappers(String packageName) { mapperRegistry.addMappers(packageName); } public void addMappers(String packageName) { addMappers(packageName, Object.class); } //说白了也就是从包路径下面拿到所有的类,然后调用传入类的方法 public void addMappers(String packageName, Class<?> superType) { ResolverUtil<Class<?>> resolverUtil = new ResolverUtil<>(); resolverUtil.find(new ResolverUtil.IsA(superType), packageName); Set<Class<? extends Class<?>>> mapperSet = resolverUtil.getClasses(); for (Class<?> mapperClass : mapperSet) { // 调用的也是核心方法1 addMapper(mapperClass); } } // 传入类的方法 public <T> void addMapper(Class<T> type) { mapperRegistry.addMapper(type); } // 核心方法1 // 方法实现说明:把我们的Mapper class保存到我们的knownMappers map 中 public <T> void addMapper(Class<T> type) { // 判断我们传入进来的type类型是不是接口 if (type.isInterface()) { // 判断我们的缓存中有没有该类型 if (hasMapper(type)) { throw new BindingException("Type " + type + " is already known to the MapperRegistry."); } boolean loadCompleted = false; try { // 创建一个MapperProxyFactory 把我们的Mapper接口保存到工厂类中 knownMappers.put(type, new MapperProxyFactory<>(type)); // mapper注解构造器 MapperAnnotationBuilder parser = new MapperAnnotationBuilder(config, type); // 进行解析 parser.parse(); loadCompleted = true; } finally { if (!loadCompleted) { knownMappers.remove(type); } } } }
【1.1.2.2.7.2】分析parse()方法怎么解析,其实有两种方式,一种是 XMLMapperBuilder类#parse方法,另一种是 MapperAnnotationBuilder类#parse方法
【1.1.2.2.7.2.1】分析XMLMapperBuilder类#parse方法
// XMLMapperBuilder类#parse方法 public void parse() { // 判断当前的Mapper是否被加载过 if (!configuration.isResourceLoaded(resource)) { // 真正的解析我们的 <mapper namespace="com.project.mapper.EmployeeMapper"> configurationElement(parser.evalNode("/mapper")); // 把资源保存到我们Configuration中 configuration.addLoadedResource(resource); bindMapperForNamespace(); } parsePendingResultMaps(); parsePendingCacheRefs(); parsePendingStatements(); } // 方法实现说明:解析我们的<mapper></mapper>节点 private void configurationElement(XNode context) { try { // 解析我们的namespace属性 <mapper namespace="com.project.mapper.EmployeeMapper"> String namespace = context.getStringAttribute("namespace"); if (namespace == null || namespace.equals("")) { throw new BuilderException("Mapper's namespace cannot be empty"); } // 保存我们当前的namespace 并且判断接口完全类名==namespace builderAssistant.setCurrentNamespace(namespace); // 解析缓存引用 // 示例说明:说明当前的缓存引用和DeptMapper的缓存引用一致,<cache-ref namespace="com.project.mapper.DeptMapper"></cache-ref> // 解析到org.apache.ibatis.session.Configuration#cacheRefMap<当前namespace,ref-namespace> // 异常下(引用缓存未使用缓存):org.apache.ibatis.session.Configuration#incompleteCacheRefs cacheRefElement(context.evalNode("cache-ref")); // 解析cache节点,如<cache type="org.mybatis.caches.ehcache.EhcacheCache"></cache> // 解析到:org.apache.ibatis.session.Configuration#caches // org.apache.ibatis.builder.MapperBuilderAssistant#currentCache cacheElement(context.evalNode("cache")); // 解析paramterMap节点(该节点mybaits3.5貌似不推荐使用了) parameterMapElement(context.evalNodes("/mapper/parameterMap")); // 解析resultMap节点 // 解析到:org.apache.ibatis.session.Configuration#resultMaps // 异常 org.apache.ibatis.session.Configuration#incompleteResultMaps resultMapElements(context.evalNodes("/mapper/resultMap")); // 解析sql节点 // 解析到org.apache.ibatis.builder.xml.XMLMapperBuilder#sqlFragments,其实等于 org.apache.ibatis.session.Configuration#sqlFragments,因为他们是同一引用,在构建XMLMapperBuilder 时把Configuration.getSqlFragments传进去了 sqlElement(context.evalNodes("/mapper/sql")); // 解析我们的select | insert |update |delete节点,解析到org.apache.ibatis.session.Configuration#mappedStatements // 实际上便是将每个语句都构建成mappedStatement对象 buildStatementFromContext(context.evalNodes("select|insert|update|delete")); } catch (Exception e) { throw new BuilderException("Error parsing Mapper XML. The XML location is '" + resource + "'. Cause: " + e, e); } }
【1.1.2.2.7.2.1.1】MappedStatement类结构展示
public final class MappedStatement { private String resource;//mapper配置文件名,如:UserMapper.xml private Configuration configuration;//全局配置 private String id;//节点的id属性加命名空间,如:com.lucky.mybatis.dao.UserMapper.selectByExample private Integer fetchSize; private Integer timeout;//超时时间 private StatementType statementType;//操作SQL的对象的类型 private ResultSetType resultSetType;//结果类型 private SqlSource sqlSource;//sql语句 private Cache cache;//缓存 private ParameterMap parameterMap; private List<ResultMap> resultMaps; private boolean flushCacheRequired; private boolean useCache;//是否使用缓存,默认为true private boolean resultOrdered;//结果是否排序 private SqlCommandType sqlCommandType;//sql语句的类型,如select、update、delete、insert private KeyGenerator keyGenerator; private String[] keyProperties; private String[] keyColumns; private boolean hasNestedResultMaps; private String databaseId;//数据库ID private Log statementLog; private LanguageDriver lang; private String[] resultSets; }
【1.1.2.2.7.2.1.2】解析cache节点部分cacheElement方法解析
//这里面便是二级缓存的产生 private void cacheElement(XNode context) { if (context != null) { //解析cache节点的type属性 String type = context.getStringAttribute("type", "PERPETUAL"); //根据type的String获取class类型 Class<? extends Cache> typeClass = typeAliasRegistry.resolveAlias(type); // 获取缓存过期策略:默认是LRU, // LRU - 最近最少使用:移除最长时间不被使用的对象(默认) // FIFO - 先进先出:按对象进入缓存的顺序来移除他们 // SOFT - 软引用:基于垃圾回收器状态和软引用规则移除对象 // WEAK - 弱引用:更积极的基于垃圾收集器状态和弱引用规则移除对象 String eviction = context.getStringAttribute("eviction", "LRU"); Class<? extends Cache> evictionClass = typeAliasRegistry.resolveAlias(eviction); //flushInterval(刷新间隔)属性可以被设置为任意的正整数,设置的值应该是一个以毫秒为单位的合理时间量。 默认情况是不设置,也就是没有刷新间隔,缓存仅仅会在调用语句时刷新。 Long flushInterval = context.getLongAttribute("flushInterval"); //size(引用数目)属性可以被设置为任意正整数,要注意欲缓存对象的大小和运行环境中可用的内存资源。默认值是 1024。 Integer size = context.getIntAttribute("size"); //只读)属性可以被设置为 true 或 false。只读的缓存会给所有调用者返回缓存对象的相同实例。 因此这些对象不能被修改。这就提供了可观的性能提升。而可读写的缓存会(通过序列化)返回缓存对象的拷贝。 速度上会慢一些,但是更安全,因此默认值是 false boolean readWrite = !context.getBooleanAttribute("readOnly", false); boolean blocking = context.getBooleanAttribute("blocking", false); Properties props = context.getChildrenAsProperties(); //把缓存节点加入到Configuration中 builderAssistant.useNewCache(typeClass, evictionClass, flushInterval, size, readWrite, blocking, props); } }
【1.1.2.2.7.2.1.2.0】分析缓存是如何封装的
public Cache useNewCache(Class<? extends Cache> typeClass, Class<? extends Cache> evictionClass, Long flushInterval, Integer size, boolean readWrite, boolean blocking, Properties props) { Cache cache = new CacheBuilder(currentNamespace) .implementation(valueOrDefault(typeClass, PerpetualCache.class)) .addDecorator(valueOrDefault(evictionClass, LruCache.class)) .clearInterval(flushInterval) .size(size) .readWrite(readWrite) .blocking(blocking) .properties(props) .build(); configuration.addCache(cache); currentCache = cache; return cache; } public Cache build() { setDefaultImplementations(); //这里便是设置了PerpetualCache为最基础层的cache Cache cache = newBaseCacheInstance(implementation, id); setCacheProperties(cache); //在这里利用decorators作为包装器进行包装 if (PerpetualCache.class.equals(cache.getClass())) { //便会存在LruCache【 delegate属性-》PerpetualCache】,利用了反射 for (Class<? extends Cache> decorator : decorators) { cache = newCacheDecoratorInstance(decorator, cache); setCacheProperties(cache); } //这里又会包装别的 cache = setStandardDecorators(cache); } else if (!LoggingCache.class.isAssignableFrom(cache.getClass())) { cache = new LoggingCache(cache); } return cache; } private Cache setStandardDecorators(Cache cache) { try { MetaObject metaCache = SystemMetaObject.forObject(cache); if (size != null && metaCache.hasSetter("size")) { metaCache.setValue("size", size); } if (clearInterval != null) { cache = new ScheduledCache(cache);//ScheduledCache:调度缓存,负责定时清空缓存 ((ScheduledCache) cache).setClearInterval(clearInterval); } if (readWrite) { // 将LRU 装饰到Serialized cache = new SerializedCache(cache); //SerializedCache:缓存序列化和反序列化存储 } cache = new LoggingCache(cache); //日志记录层包装 cache = new SynchronizedCache(cache); //线程同步层包装 if (blocking) { //判断是否有进行防穿透设置 cache = new BlockingCache(cache); } return cache; } catch (Exception e) { throw new CacheException("Error building standard cache decorators. Cause: " + e, e); } }
【1.1.2.2.7.2.1.2.1】对cache的分析:
//Cache本身只是一个接口,用于定义缓存 public interface Cache { String getId(); void putObject(Object key, Object value); Object getObject(Object key); Object removeObject(Object key); void clear(); int getSize(); default ReadWriteLock getReadWriteLock() { return null; } } //重点在于它的实现类 //四种具备淘汰机制的cache LruCache:(最近最少使用)防溢出缓存区 FifoCache:(先进先出) WeakCache:基于弱引用实现的缓存管理策略 SoftCache:基于软引用实现的缓存管理策略 //底层的cache PerpetualCache:真正存储缓存的地方 //额外辅助功能的cache ScheduledCache:过期清理缓存区 SynchronizedCache:线程同步缓存区 LoggingCache:统计命中率以及打印日志 SerializedCache:缓存序列化和反序列化存储 BlockingCache:防穿透
【1.1.2.2.7.2.1.2.1.1】对cache的最常用的两种淘汰策略分析:
【1.1.2.2.7.2.1.2.1.1.1】对LRU分析:【这个本质上就是利用LinkedHashMap】
public class LruCache implements Cache { private final Cache delegate; private Map<Object, Object> keyMap; private Object eldestKey; public LruCache(Cache delegate) { this.delegate = delegate; setSize(1024); } @Override public String getId() { return delegate.getId(); } @Override public int getSize() { return delegate.getSize(); } public void setSize(final int size) { keyMap = new LinkedHashMap<Object, Object>(size, .75F, true) { private static final long serialVersionUID = 4267176411845948333L; //当put进新值方法但会true时,便移除该map中最老的键和值 @Override protected boolean removeEldestEntry(Map.Entry<Object, Object> eldest) { boolean tooBig = size() > size; if (tooBig) { eldestKey = eldest.getKey(); } return tooBig; } }; } @Override public void putObject(Object key, Object value) { delegate.putObject(key, value); cycleKeyList(key); } @Override public Object getObject(Object key) { keyMap.get(key); //touch return delegate.getObject(key); } @Override public Object removeObject(Object key) { return delegate.removeObject(key); } @Override public void clear() { delegate.clear(); keyMap.clear(); } private void cycleKeyList(Object key) { keyMap.put(key, key); if (eldestKey != null) { delegate.removeObject(eldestKey); eldestKey = null; } } }
【1.1.2.2.7.2.1.2.1.1.2】对FIFO分析:【这个本质上就是利用LinkedList】
public class FifoCache implements Cache { private final Cache delegate; private final Deque<Object> keyList; private int size; public FifoCache(Cache delegate) { this.delegate = delegate; this.keyList = new LinkedList<>(); this.size = 1024; } @Override public String getId() { return delegate.getId(); } @Override public int getSize() { return delegate.getSize(); } public void setSize(int size) { this.size = size; } //可以看出都是移除头部节点,将新的塞入尾结点 @Override public void putObject(Object key, Object value) { cycleKeyList(key); delegate.putObject(key, value); } @Override public Object getObject(Object key) { return delegate.getObject(key); } @Override public Object removeObject(Object key) { return delegate.removeObject(key); } @Override public void clear() { delegate.clear(); keyList.clear(); } //加到最后,移除最前 private void cycleKeyList(Object key) { keyList.addLast(key); if (keyList.size() > size) { Object oldestKey = keyList.removeFirst(); delegate.removeObject(oldestKey); } } }
【1.1.2.2.7.2.1.3】解析sql节点部分sqlElement方法解析:
private void buildStatementFromContext(List<XNode> list) { // 判断有没有配置数据库厂商ID if (configuration.getDatabaseId() != null) { buildStatementFromContext(list, configuration.getDatabaseId()); } buildStatementFromContext(list, null); } /** * 方法实现说明:解析select|update|delte|insert节点然后创建mapperStatment对象 * @param list:所有的select|update|delte|insert节点 * @param requiredDatabaseId:判断有没有数据库厂商Id */ private void buildStatementFromContext(List<XNode> list, String requiredDatabaseId) { // 循环select|delte|insert|update节点 for (XNode context : list) { // 创建一个xmlStatement的构建器对象 final XMLStatementBuilder statementParser = new XMLStatementBuilder(configuration, builderAssistant, context, requiredDatabaseId); try { statementParser.parseStatementNode(); } catch (IncompleteElementException e) { configuration.addIncompleteStatement(statementParser); } } }
【1.1.2.2.7.2.1.3.1】深入分析是怎么解析的:
public void parseStatementNode() { // insert|delte|update|select 语句的sqlId String id = context.getStringAttribute("id"); // 判断insert|delte|update|select 节点是否配置了数据库厂商标注 String databaseId = context.getStringAttribute("databaseId"); // 匹配当前的数据库厂商id是否匹配当前数据源的厂商id if (!databaseIdMatchesCurrent(id, databaseId, this.requiredDatabaseId)) { return; } // 获得节点名称:select|insert|update|delete String nodeName = context.getNode().getNodeName(); // 根据nodeName 获得 SqlCommandType枚举 SqlCommandType sqlCommandType = SqlCommandType.valueOf(nodeName.toUpperCase(Locale.ENGLISH)); // 判断是不是select语句节点 boolean isSelect = sqlCommandType == SqlCommandType.SELECT; // 获取flushCache属性,默认值为isSelect的反值:查询:默认flushCache=false,增删改:默认flushCache=true boolean flushCache = context.getBooleanAttribute("flushCache", !isSelect); // 获取useCache属性,默认值为isSelect:查询:默认useCache=true,增删改:默认useCache=false boolean useCache = context.getBooleanAttribute("useCache", isSelect); // resultOrdered: 是否需要处理嵌套查询结果 group by (使用极少),可以将比如 30条数据的三组数据 组成一个嵌套的查询结果 boolean resultOrdered = context.getBooleanAttribute("resultOrdered", false); // 解析sql公用片段,如 //<select id="qryEmployeeById" resultType="Employee" parameterType="int"> // <include refid="selectInfo"></include> // employee where id=#{id} //</select> //将 <include refid="selectInfo"></include> 解析成sql语句 放在<select>Node的子节点中 XMLIncludeTransformer includeParser = new XMLIncludeTransformer(configuration, builderAssistant); includeParser.applyIncludes(context.getNode()); // 解析我们sql节点的参数类型 String parameterType = context.getStringAttribute("parameterType"); // 把参数类型字符串转化为class Class<?> parameterTypeClass = resolveClass(parameterType); // 查看sql是否支撑自定义语言,如 // <delete id="delEmployeeById" parameterType="int" lang="tulingLang"> // <settings> // setting name="defaultScriptingLanguage" value="tulingLang"/> // </settings> String lang = context.getStringAttribute("lang"); // 获取自定义sql脚本语言驱动 默认:class org.apache.ibatis.scripting.xmltags.XMLLanguageDriver LanguageDriver langDriver = getLanguageDriver(lang); // Parse selectKey after includes and remove them. // 解析<insert 语句的的selectKey节点, 一般在oracle里面设置自增id processSelectKeyNodes(id, parameterTypeClass, langDriver); // Parse the SQL (pre: <selectKey> and <include> were parsed and removed) // insert语句 用于主键生成组件 KeyGenerator keyGenerator; /** * selectById!selectKey * id+!selectKey */ String keyStatementId = id + SelectKeyGenerator.SELECT_KEY_SUFFIX; //把命名空间拼接到keyStatementId中 , com.tuling.mapper.Employee.saveEmployee!selectKey keyStatementId = builderAssistant.applyCurrentNamespace(keyStatementId, true); /** *<insert id="saveEmployee" parameterType="com.tuling.entity.Employee" useGeneratedKeys="true" keyProperty="id"> *判断全局的配置类configuration中是否包含以及解析过的组件生成器对象 */ if (configuration.hasKeyGenerator(keyStatementId)) { keyGenerator = configuration.getKeyGenerator(keyStatementId); } else { /** * 若配置了useGeneratedKeys 那么就去除useGeneratedKeys的配置值, * 否者就看mybatis-config.xml配置文件中是配置了 * <setting name="useGeneratedKeys" value="true"></setting> 默认是false * 并且判断sql操作类型是否为insert * 若是的话,那么使用的生成策略就是Jdbc3KeyGenerator.INSTANCE * 否则就是NoKeyGenerator.INSTANCE */ keyGenerator = context.getBooleanAttribute("useGeneratedKeys", configuration.isUseGeneratedKeys() && SqlCommandType.INSERT.equals(sqlCommandType)) ? Jdbc3KeyGenerator.INSTANCE : NoKeyGenerator.INSTANCE; } // 通过class org.apache.ibatis.scripting.xmltags.XMLLanguageDriver来解析我们的sql脚本对象. // 解析SqlNode. 注意:只是解析成一个个的SqlNode,并不会完全解析sql,因为这个时候参数都没确定,动态sql无法解析 SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass); // STATEMENT,PREPARED 或 CALLABLE 中的一个。 // 这会让 MyBatis 分别使用 Statement,PreparedStatement 或 CallableStatement,默认值:PREPARED StatementType statementType = StatementType.valueOf(context.getStringAttribute("statementType", StatementType.PREPARED.toString())); // 这是一个给驱动的提示,尝试让驱动程序每次批量返回的结果行数和这个设置值相等。 默认值为未设置(unset)(依赖驱动) Integer fetchSize = context.getIntAttribute("fetchSize"); // 这个设置是在抛出异常之前,驱动程序等待数据库返回请求结果的秒数。默认值为未设置(unset)(依赖驱动)。 Integer timeout = context.getIntAttribute("timeout"); // 将会传入这条语句的参数类的完全限定名或别名。这个属性是可选的,因为 MyBatis 可以通过类型处理器(TypeHandler) 推断出具体传入语句的参数,默认值为未设置 String parameterMap = context.getStringAttribute("parameterMap"); // 从这条语句中返回的期望类型的类的完全限定名或别名。 注意如果返回的是集合,那应该设置为集合包含的类型,而不是集合本身。 // 可以使用 resultType 或 resultMap,但不能同时使用 String resultType = context.getStringAttribute("resultType"); // 解析我们查询结果集返回的类型 Class<?> resultTypeClass = resolveClass(resultType); // 外部 resultMap 的命名引用。结果集的映射是 MyBatis 最强大的特性,如果你对其理解透彻,许多复杂映射的情形都能迎刃而解。 // 可以使用 resultMap 或 resultType,但不能同时使用。 String resultMap = context.getStringAttribute("resultMap"); String resultSetType = context.getStringAttribute("resultSetType"); ResultSetType resultSetTypeEnum = resolveResultSetType(resultSetType); if (resultSetTypeEnum == null) { resultSetTypeEnum = configuration.getDefaultResultSetType(); } // 解析 keyProperty keyColumn 仅适用于 insert 和 update String keyProperty = context.getStringAttribute("keyProperty"); String keyColumn = context.getStringAttribute("keyColumn"); String resultSets = context.getStringAttribute("resultSets"); // 为我们的insert|delete|update|select节点构建成我们的mappedStatment对象 builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType, fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass, resultSetTypeEnum, flushCache, useCache, resultOrdered, keyGenerator, keyProperty, keyColumn, databaseId, langDriver, resultSets); }
【1.1.2.2.7.2.1.3.1.1】深入分析SqlNode的生成:
@Override //方法实现说明:创建sqlSource对象 public SqlSource createSqlSource(Configuration configuration, XNode script, Class<?> parameterType) { XMLScriptBuilder builder = new XMLScriptBuilder(configuration, script, parameterType); return builder.parseScriptNode(); } public SqlSource parseScriptNode() { MixedSqlNode rootSqlNode = parseDynamicTags(context); SqlSource sqlSource; if (isDynamic) { // 动态Sql源(需要参数才能确定的sql语句) // 如:select id,user_name,create_time from t_user where id=${param1} ,这种是拼接的 sqlSource = new DynamicSqlSource(configuration, rootSqlNode); } else { // 静态Sql源(不需要通过参数就能确定的sql语句),它会在这里解析 // 如:select id,user_name,create_time from t_user where id=#{param1} ,因为是会把 #{param1} 这部分用?替换 sqlSource = new RawSqlSource(configuration, rootSqlNode, parameterType); } return sqlSource; } // 解析${} 和 动态节点 /** * 递归解析 selectById这个sql元素会解析成 * 1层 MixedSqlNode <SELECT> * 2层 WhereSqlNode <WHERE> * 2层 IfSqlNode <IF> * test="条件表达式" * * contexts= sql语句分: 1.TextSqlNode 带${} 2.StaticTextSqlNode */ protected MixedSqlNode parseDynamicTags(XNode node) { List<SqlNode> contents = new ArrayList<>(); NodeList children = node.getNode().getChildNodes(); //获得<select>的子节点 for (int i = 0; i < children.getLength(); i++) { XNode child = node.newXNode(children.item(i)); if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE || child.getNode().getNodeType() == Node.TEXT_NODE) { String data = child.getStringBody(""); // 获得sql文本 TextSqlNode textSqlNode = new TextSqlNode(data); if (textSqlNode.isDynamic()) { // 怎样算Dynamic? 其实就是判断sql文本中有${} contents.add(textSqlNode); isDynamic = true; } else { contents.add(new StaticTextSqlNode(data)); } } else if (child.getNode().getNodeType() == Node.ELEMENT_NODE) { // issue #628 String nodeName = child.getNode().getNodeName(); // 判断当前节点是不是动态sql节点{@link XMLScriptBuilder#initNodeHandlerMap()} NodeHandler handler = nodeHandlerMap.get(nodeName); if (handler == null) { throw new BuilderException("Unknown element <" + nodeName + "> in SQL statement."); } handler.handleNode(child, contents); // 不同动态节点有不用的实现 isDynamic = true; // 怎样算Dynamic? 其实就是判断sql文本动态sql节点 } } return new MixedSqlNode(contents); } // SqlNode的类型 // ChooseSqlNode // ForEachSqlNode // IfSqlNode // StaticTextSqlNode // TextSqlNode // MixedSqlNode:如果某阶段还包含其他SqlNode节点,用这个进行包装 // SetSqlNode // WhereSqlNode // TrimSqlNode //如示例: <select id="selectById" resultMap="result" > select id,user_name,create_time from t_user <where> <if test="id>0"> and id=#{id} </if> </where> </select> //划分情况: MixedSqlNode StaticTextSqlNode WhereSqlNode MixedSqlNode IfSqlNode MixedSqlNode StaticTextSqlNode
【1.1.2.2.7.2.2】分析MapperAnnotationBuilder类#parse方法
// MapperAnnotationBuilder类#parse方法 public void parse() { String resource = type.toString(); // 是否已经解析mapper接口对应的xml if (!configuration.isResourceLoaded(resource)) { // 根据mapper接口名获取 xml文件并解析,解析<mapper></mapper>里面所有东西放到configuration loadXmlResource(); // 添加已解析的标记 configuration.addLoadedResource(resource); assistant.setCurrentNamespace(type.getName()); parseCache(); parseCacheRef(); // 获取所有方法 看是不是用了注解 Method[] methods = type.getMethods(); for (Method method : methods) { try { if (!method.isBridge()) { // 是不是用了注解 用了注解会将注解解析成MappedStatement parseStatement(method); } } catch (IncompleteElementException e) { configuration.addIncompleteMethod(new MethodResolver(this, method)); } } } parsePendingMethods(); }
参数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号