MQ详解
什么是MQ?
【1】MQ:MessageQueue,消息队列。 队列,是一种FIFO 先进先出的数据结构。消息由生产者发送到MQ进行排队,然后按原来的顺序交由消息的消费者进行处理。QQ和微信就是典型的MQ。
为什么要用MQ(MQ的优点)?
MQ的作用主要有以下三个方面:
【1】异步
例子:快递员发快递,直接到客户家效率会很低。引入菜鸟驿站后,快递员只需要把快递放到菜鸟驿站,就可以继续发其他快递去了。客户再按自己的时间安排去菜鸟驿站取快递。
作用:异步能提高系统的响应速度、吞吐量。
【2】解耦
例子:《Thinking in JAVA》很经典,但是都是英文,我们看不懂,所以需要编辑社,将文章翻译成其他语言,这样就可以完成英语与其他语言的交流。
作用:
1、服务之间进行解耦,才可以减少服务之间的影响。提高系统整体的稳定性以及可扩展性。
2、另外,解耦后可以实现数据分发。生产者发送一个消息后,可以由一个或者多个消费者进行消费,并且消费者的增加或者减少对生产者没有影响。
【3】削峰
例子:长江每年都会涨水,但是下游出水口的速度是基本稳定的,所以会涨水。引入三峡大坝后,可以把水储存起来,下游慢慢排水。
作用:以稳定的系统资源应对突发的流量冲击。
MQ的缺点
【1】系统可用性降低
系统引入的外部依赖增多,系统的稳定性就会变差。一旦MQ宕机,对业务会产生影响。这就需要考虑如何保证MQ的高可用。
【2】系统复杂度提高
引入MQ后系统的复杂度会大大提高。以前服务之间可以进行同步的服务调用,引入MQ后,会变为异步调用,数据的链路就会变得更复杂。并且还会带来其他一些问题。比如:如何保证消费不会丢失?不会被重复调用?怎么保证消息的顺序性等问题。
【3】消息一致性问题
A系统处理完业务,通过MQ发送消息给B、C系统进行后续的业务处理。如果B系统处理成功,C系统处理失败怎么办?这就需要考虑如何保证消息数据处理的一致性。
常用的MQ产品
【1】Kafka、RabbitMQ和RocketMQ。我们对这三个产品做下简单的比较,重点需要理解他们的适用场景。
【2】图示:

【3】分别分析三种消息中间件
1.RabbitMQ:消息可靠性很高,功能非常全面,很多高级功能都是从这里衍生出来的,如死信队列,延迟队列。缺点在于吞吐量很低,消息积累会影响消费的性能,而且erlang的语言使用的比较少,定制比较难。适用于公司内部系统的请求扭转的流程。
2.Kafka:行业的老大哥,基本上是大数据场景必用的组件之一,吞吐量不可挑战,集群性能很好。之前是依赖zookeeper搭建集群,但是新版本会逐渐抛弃zookeeper。但是会存在丢消失的可能,而且功能单一,很多高级功能都没有,如死信队列。最早就是用来做日志分析的。
3.RocketMQ:最开始是借鉴Kafka,后面逐步优化。吞吐量基本和Kafka是一个量级的,功能也很全面,如RabbitMQ有的都有,还有其他没有的事务功能。缺点是开源版不如云上商业版。如延迟队列,开源会有固定的限制。
MQ使用中的常见问题
【1】如何保证消息不丢失?
1)分析哪些环节会有丢消息的可能
(1)图示
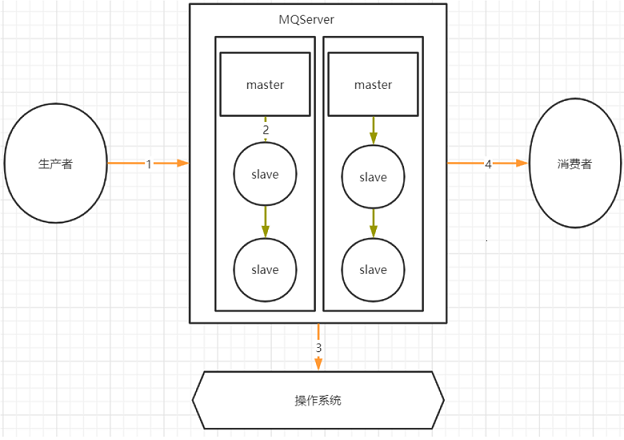
(2)分析
1.其中,1,2,4三个场景都是跨网络的,而跨网络就肯定会有丢消息的可能。
2.而3这个环节,通常MQ存盘时都会先写入操作系统的缓存page cache中,然后再由操作系统异步的将消息写入硬盘。这个中间有个时间差,就可能会造成消息丢失。如果服务挂了,缓存中还没有来得及写入硬盘的消息就会丢失。这也是任何用户态的应用程序无法避免的。
2)分析怎么处理的
1.为保证消息不丢失,发送端的ACK应答必须是多个节点写入的应答 兼 采用多次重试的方式(预防网络抖动),其次消息中间件内部持久化,消费端是消费后手动应答。
2.在发送端还应该:区分业务的关键性,如果消息不影响主体业务(如,消息通知要做的事情可以延迟很久,但因某些缘故,消息发不出去),这时候采用将消息落盘,然后调用定时任务的形式,延时检查发送。
3.在消费端还应该:对消费失败的消息进行次数检测,如果多次失败(有可能参数异常,有可能流程出了问题),应该落盘(避免消息堆积),告知程序员处理。
【2】如何保证消息幂等性?
1)分析哪些环节会造成消息重复消费
1.MQ的自动重试功能:如网络抖动时,生产者发送得不到MQ的回应尝试多次发送;消费者做完任务,返回给MQ的应答丢失,导致MQ发给了另一个消费者去消费消息。
2.代码BUG导致消息多次发送。
2)分析怎么处理的
1.首先在MQ上我们是不能保证消息的幂等性的,所以我们只能在业务中处理。
2.处理幂等问题的关键是要给每个消息一个唯一的标识(但这个不能是MQ给我们的消息ID,因为它依旧解决不了生产者发送多次的问题)
3.需要我们自行构建分布式唯一ID(如雪花算法),能够添加一个具有业务意义的数据作为唯一键会更好,这样能更好的防止重复消费问题对业务的影响。比如,针对订单消息,那就用订单ID来做唯一键。
4.如订单ID来做唯一键,就算真的出现了很不幸的两个消费者同时消费两条重复的数据,那么在进行MYSQL写入的时候,事务处理与唯一键索引,将是兜底保证业务执行幂等性的关键。
5.当然,采用redis的Setnx(要设置超时时间)作为CAS锁保证只有一个线程执行业务也是可以的,成功后还可以设置标记值来标记该业务已经做完,等下次重复的消息过来时候,进行redis检验的时候就会自动丢弃这些重复的消息。【这里面需要衡量的是业务的处理速度,与占用redis的内存空间,虽然有过期时间,但是在这段时间内这些数据依旧会占用空间,如果处理速度很快,则占用的空间越多】
【3】如何保证消息的顺序?
1)原因:某些场景下,需要保证消息的消费顺序,例如一个下单过程,需要先完成扣款,然后扣减库存,然后通知快递发货,这个顺序不能乱。如果每个步骤都通过消息进行异步通知的话,这一组消息就必须保证他们的消费顺序是一致的
2)分析该怎么处理(基于MQ无法保证,那么更多是在业务层面实现)
方案一:为保证消息的有序性,采用用同步发送的模式去发消息,然后消息发往同一个队列里面,然后采用一个消费者去进行消费。
方案二:为保证高性能,采用用异步发送的模式去发消息,然后消息发往同一个队列里面,然后采用一个消费者去进行消费。消费者端接收后,因为可能消息群是乱序的(异步发送模式),所以构建内存队列(优先级队列),将消息排序消费(每个内存队列只允许一个线程消费,可拓展为多个内存队列多个线程)
针对这种,容易出现消息堆积的情况,可扩展为多个队列,每个队列都有唯一的一个消费者。在发送端建立消息组ID,根据组ID进行hash决定这一组消息分配至哪个队列里面。但是又容易出现数据倾斜的问题,则可以考虑构建hash环与增加虚拟节点的想法,将数据更加均匀的分布。
【4】数据堆积如何处理?
1)线上有时因为发送方发送消息速度过快,或者消费方处理消息过慢,可能会导致MQ积压大量未消费消息。此种情况如果积压了上百万未消费消息需要紧急处理,可以修改消费端程序,让其将收到的消息快速转发到其他队列,然后再启动多个消费者同时消费。
2)由于消息数据格式变动或消费者程序有bug,导致消费者一直消费不成功,也可能导致MQ积压大量未消费消息。此种情况可以将这些消费不成功的消息转发到其它队列里去(类似死信队列),后面再慢慢分析死信队列里的消息处理问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号