

Redis 数据结构的底层实现 (一) RealObject,embstr,sds,ziplist,quicklist
一.realObject
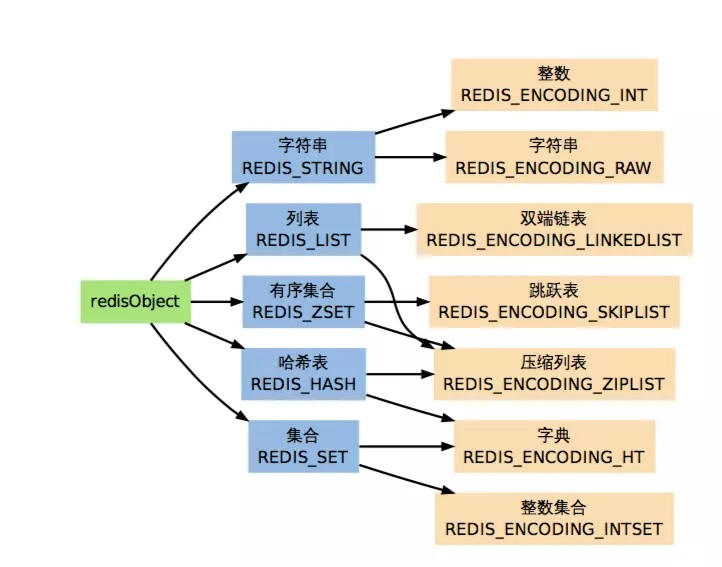
Redis使用 string list zset hash set 五大数据类型来存储键和值。在每次生成一个键值对时,都会生成两个对象,一个储存键一个储存值。redis定义了RealObject结构体表示他们
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* lru time (relative to server.lruclock) */
int refcount;
void *ptr;
} robj;
1.type
redis 的对象有五种类型,分别是string list zset hash set,type就是用来标识这五种类型的。
/* Object types */ #define OBJ_STRING 0 #define OBJ_LIST 1 #define OBJ_SET 2 #define OBJ_ZSET 3 #define OBJ_HASH 4
(在redis中,键总是一个字符串对象,而值可以是字符串、列表、集合等对象)
2.编码类型encoding
redis的对象的实际编码方式由encoding参数指定,也就是ptr指针指向的数据以何种底层实现存放。
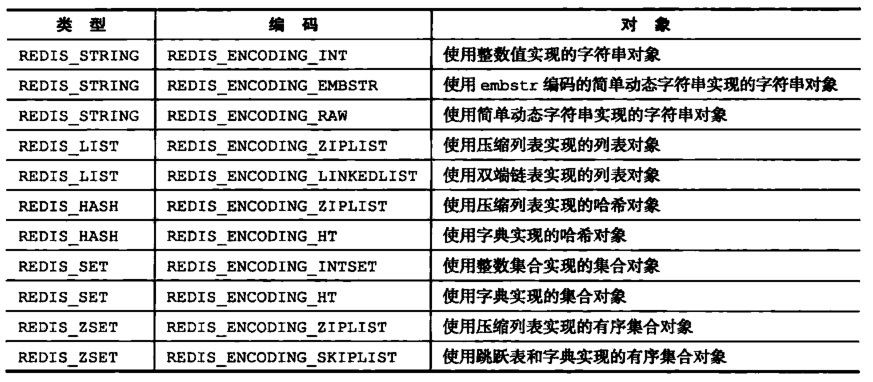
/* Objects encoding. Some kind of objects like Strings and Hashes can be * internally represented in multiple ways. The 'encoding' field of the object * is set to one of this fields for this object. */ #define OBJ_ENCODING_RAW 0 /* Raw representation -- 简单动态字符串sds*/ #define OBJ_ENCODING_INT 1 /* Encoded as integer -- long类型的整数*/ #define OBJ_ENCODING_HT 2 /* Encoded as hash table -- 字典dict*/ #define OBJ_ENCODING_ZIPMAP 3 /* Encoded as zipmap -- 3.2.5版本后不再使用 */ #define OBJ_ENCODING_LINKEDLIST 4 /* Encoded as regular linked list -- 双向链表*/ #define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist -- 压缩列表*/ #define OBJ_ENCODING_INTSET 6 /* Encoded as intset -- 整数集合*/ #define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist -- 跳表*/ #define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding -- embstr编码的sds*/ #define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists -- 由双端链表和压缩列表构成的高速列表*/
可以通过 object encoding key 指令查看值对象的编码
3.访问时间lru
表示该对象最后一次呗访问的时间,占用24bit。保存该值的目的是为了计算对象的空转时长,便于决定是否应该释放该键。
4.引用计数refcount
c语言不具备自动内存回手机制,所以为每个对象设定了引用计数。
- 当创建一个对象时,记为1;
- 当被一个新的程序使用时,引用计数++;
- 不再被一个程序使用时,引用计数--;
- 当引用计数为0时,释放该对象。回收内存。
void decrRefCount(robj *o) {
// 引用计数为小于等于0,报错
if (o->refcount <= 0) serverPanic("decrRefCount against refcount <= 0");
// 引用计数等于1,减1后为0
// 须要释放整个redis对象
if (o->refcount == 1) {
switch(o->type) {
// 依据对象类型。调用不同的底层函数对对象中存放的数据结构进行释放
case OBJ_STRING: freeStringObject(o); break;
case OBJ_LIST: freeListObject(o); break;
case OBJ_SET: freeSetObject(o); break;
case OBJ_ZSET: freeZsetObject(o); break;
case OBJ_HASH: freeHashObject(o); break;
default: serverPanic("Unknown object type"); break;
}
// 释放redis对象
zfree(o);
} else {
// 引用计数减1
o->refcount--;
}
}
5.ptr指向实际存放的对象
二、OBJ_ENCODING_RAW
RAW编码方式使用简单动态字符串sds来保存字符串对象
struct sdshdr {
unsigned int len; //buf中已经占用的空间的长度
unsigned int free;//buf中剩余的可用空间长度
char buf[];//数据存放位置
};
- 其中buf[]结束并不依赖于‘\0’,使用len判断结束,可以保存二进制流对象。其中buf[]是一个柔性数组(flexible array member 详见https://blog.csdn.net/sunlylorn/article/details/7544301)
- 预分配,可以减少修改字符串长度增长时造成的再次分配
三、OBJ_ENCODING_EMBSTR
从Redis 3.0 版本开始,字符串引入了embstr编码方式,长度小于OBJ_ENCONDING_EMBSTR_SIZE_LIMIT的字符串将以EMBSTR方式存储。
EMBSTR方式的意思是 embedded string,字符串的空间将会和redisObject对象的空间一起分配,两者分配在同一个内存块中。
redis中内存分配使用的是jemalloc,jemalloc分配内存的时候是按照8,16,32,64作为块的单位进行飞扑的。为了保证采用这种编码方式的字符串能被jemalloc分配在同一个块(chunk)中,该块长度不能超过64,故字符串长度限制OBJ_ENCONDING_EMBSTR_SIZE_LIMIT = 64 - sizeof('\0') -sizeof(robj) -sizeof(sdshdr) =39.
这样可以有效减少内存分配的次数,提高内存分配的效率,降低碎片率。
结构同样适用 sdshdr(见上文)
四、OBJ_ENCODING_ZIPLIST
链表(list),哈希(hash),有序集合(zset)在成员较少,成员值较小的时候都采用压缩链表(ziplist)编码方式进行存储。
这里成员较少,成员值较小的标准可以通过配置项进行设置
hash-max-ziplist-entries 512 hash-max-ziplist-value 64 list-max-ziplist-entries 512 list-max-ziplist-value 64 zset-max-ziplist-entries 128 zset-max-ziplist-value 64
事实上,ziplist是一个经过特殊编码的双向链表(底层是一个数组),他设计的目的是为了提高存储效率。
一个普通的双向链表,链表中每一项都会占用独立的一块内存,各个项之间用指针连接起来,这样会带来大量的内部碎片(不利于局部性原理缓存加载对应块内存),而且指针也会占用额外的内存。而ziplist将表中每一项存放在前后连续的地址空间内,它其实是一个list而不是一个链表。
area |<---- ziplist header ---->|<----------- entries ------------->|<-end->|
size 4 bytes 4 bytes 2 bytes ? ? ? ? 1 byte
+---------+--------+-------+--------+--------+--------+--------+-------+
component | zlbytes | zltail | zllen | entry1 | entry2 | ... | entryN | zlend |
+---------+--------+-------+--------+--------+--------+--------+-------+
^ ^ ^
address | | |
ZIPLIST_ENTRY_HEAD | ZIPLIST_ENTRY_END
|
ZIPLIST_ENTRY_TAIL
area |<------------------- entry -------------------->|
+------------------+----------+--------+---------+
component | pre_entry_length | encoding | length | content |
+------------------+----------+--------+---------+
- zlbytes:4bytes 表示ziplist占用的字节总数(包括zlbytes本身占用的4个bytes)
- zltail : 4bytes 表示ziplist表中最优一项(entry)在表中的偏移(字节数)。可以很方便的找到最后一项,从而可以进行O(1)的push和pop
- zllen : 2bytes 表示ziplist中数据项(entry)的个数。zllen字段因为只有16bit,所以能够表示的最大值就是2^16 -1。如果entry中存放的个数小于等于 2^16 -2 ,那么zllen就表示实际的数据个数,如果zllen为全1(>=2^16 -1),那么数据的个数就需要遍历整个entry(也可以取zltail偏移量计算)。
- entry : xbytes 表示真正存放数据的数据项,长度不固定。同时,entry也有自己的内部结构,下文会解释。
- zlend :1bytes ziplist 的结束标记,固定值等于255(全1)。
- 其中 zlbytes zltail zllen等值按照低位编址实现。(实际值:0x12345678 高位编址-0x12345678 低位编址-0x78563412)
entry
- prevrawlen:表示前一个数据项占用的总字节数。这个字段的用处是为了让ziplist能够从后向前遍历(从后一项的位置,秩序要向前便宜prevrawlen个字节,就能够找到前一项)。这个字段采用变长编码。
- len:表示当前数据项的长度。采用变长编码
- data:保存数据。
变长编码
prevrawlen: 它有两种可能,要么是1个字节,或者是5个字节
1.如果前面一个数据项字节占用小于等于253,那么prevrawlen就占用一个字节
2.如果前一个entry占用字节数大于等于254,那么第一个字节就是254,后四个字节表示一个整形值,表示prevrawlen的大小。
3.255不出现在entry的第一个字节,因为它表示结束。
len:len字段更加复杂,它根据第一个字节的不同 ,一共分为9种情况。(以下用二进制表示)
1.|00xxxxxx| - 1 byte。第一个字节最高两位是00,那么len字段占1个字节,剩余的6个bit用来表示长度,最多可以表示63.
2.|01xxxxxx|xxxxxxxx| - 2 bytes。 第一个字节最高两位是01,那么len字段占2个字节,剩余的14个bit用来表示长度,最多16383(2^14-1)。
3.|10______|xxxxxxxx|xxxxxxxx|xxxxxxxx|xxxxxxxx| - 5bytes。
第一个字节最高两位是10,len字段占5个字节,总共使用32个bit来表示长度(2-7位舍弃不用),最多表示2^32-1。
(在前三种情况下,data都是按字符串存储的,从下面一种情况开始,开始按整数来存储)。
4.|11000000| - 1 byte。 len字段占用一个字节,后面的data数据储存位2个字节的int16_t类型。
5.|11010000| - 1 byte。 len字段占用一个字节,后面的data存储为4个字节的int32_t类型。
6.|11100000| - 1 byte。 len字段占用一个字节,后面的data存储为8个字节的int64_t类型。
7.|11110000| - 1 byte。 len字段占用一个字节,后面的data存储为3个字节长的整数。
8.|11111110| - 1 byte。len字段占用一个字节,后面的data存储为1个字节长的整数。
9.|1111xxxx| - 1byte。这是一种特殊情况,xxxx从1到13一共13个值,就用这13种情况表示真正的数据。(0001-1101一共13个值表示0-12,这种情况下data于len字段合二为一了。)
hash与zipliist
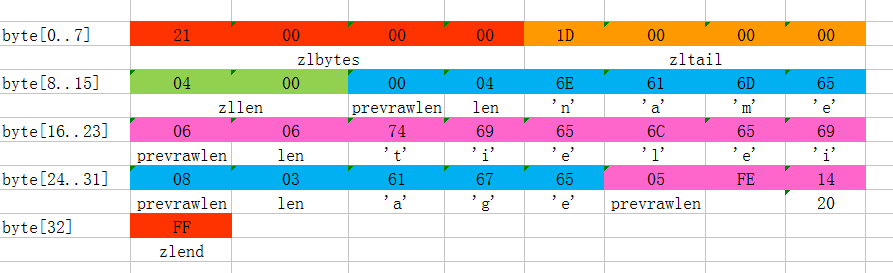
这个ziplist一共包含33个字节。从byte[0]-byte[32],每个字节的值采用16进制表示。
总结一下,这个ziplist里存了4个数据项,分别为:
字符串:name 字符串:tielei
字符串:age 整数:20
其实这个ziplist是通过两个hset命令创建出来的。
hset user:100 name tielei hset user:100 age
当我们为某个key第一次执行hset key field value时,redis会创建一个hash结构,这个新创建的hash底层就是一个ziplist。
// object.c
robj *createHashObject(void) { unsigned char *zl = ziplistNew(); robj *o = createObject(OBJ_HASH, zl); o->encoding = OBJ_ENCODING_ZIPLIST; return o; }
上面的代码负责创建一个新的hash结构,实际上,它创建了一个 type = OBJ_HASH但encoding = OBJ_ENCODING_ZIPLIST的robj对象。
(每当执行一次hset命令,插入的field和value分别作为一个新的数据项插入到ziplist中)。
当然随着数据的插入,hash的层的这个ziplist就可能会转成dict。
ziplist的插入逻辑
在ziplist的entry中插入一段新的数据,会返回一个新的ziplist,替换原来传入的旧的ziplist。因为ziplist是一段连续的地址空间,对他的追加操作,会引发内存的realloc,因此ziplist的内存位置可能会发生变化。
1.先把插入结点后面结点的prevrawlen写入新entry 然后把新结点的长度写入后一个结点的prevrawlen
2.然后计算插入后的空间大小,调用allocator的zrealloc,数据拷贝。
3.然后就是将插入位置后的数据向后挪动,插入新entry。
五、OBJ_ENCODING_LINKEDLIST 和 OBJ_ENCODING_QUICKLIST
在redis 3.2之前 一般的链表采用LINKEDLIST编码。
在redis 3.2版本开始,所有的链表都采用QUICKLIST编码。
两者都是使用基本的双端链表数据结构,区别是QUICKLIST每个结点的值都是使用ZIPLIST进行存储的。
// 3.2版本之前
typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr,void *key);
unsigned long len;
} list;
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
// 3.2版本
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned int len; /* number of quicklistNodes */
int fill : 16; /* fill factor for individual nodes */
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
} quicklist;
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
什么意思呢,比如,一个包含三个结点的quicklist,如果每个结点的ziplist又包含四个数据项,那么对外表现上,这个list就总共包含12个数据项。这样的设计,实际上是对于时间和空间的一种折中。
- linkedlist便于在表的两端进行push和pop操作,但是它的内存开销较大。首先,它的每个节点除了要保存数据之外还要额外保存两个指针;其次,双向链表的各个节点是单独的内存块,地址不连续,容易产生内存碎片,还容易造成抖动。
- ziplist由于是一整块连续的内存,存储效率很高,但不利于添加和删除操作,每次都会重新realloc,尤其是当ziplist很长的时候,一次realloc造成的开销特别的大,查询的开销也特别的大。
于是quicklist集合了两个结构的有点,但多少是合理的长度呢,redis系统中用户可以自定义这个值。
list-max-ziplist-size -2
这个参数可正可负,取正值 n 的时候,这个正值表示的就是每个ziplist的长度最多不能超过n。
当取复制的时候 只能取 -1 ~ -5 这五个值,表示按照字节数来限定每个ziplist节点的长度。
- -1 每个quicklist节点大小不能超过4Kb
- -2 每个quicklist节点大小不能超过8Kb
- -3 每个quicklist节点大小不能超过16Kb
- -4 每个quicklist节点大小不能超过32Kb
- -5 每个quicklist节点大小不能超过64Kb
节点的压缩
另外,quicklist的设计目标是用来存储很长的数据链表的,当链表很长的时候,最容易被访问的是两端的数据,中间的数据被访问的概率比较低,如果应用场景符合这个特点,list还提供了一个选项,可以把中间的数据节点进行压缩,而两边不被压缩,参数
list-compress-depth 0
就是用来完成这个设置的,数值表示两边不被压缩的节点个数
- 其中 0 是个特殊值,表示都不压缩,这是 redis的默认值。
- 1表示quicklist两端各有1个节点不压缩,中间的节点压缩。
- 2表示quicklist两端各有2个节点不压缩,中间的节点压缩
- 3......
- 对于quicklist的压缩算法,采用LZF---一种无损压缩算法。https://www.cnblogs.com/pengze0902/p/5998843.html
quicklist的数据结构(quicklist.h)
/* quicklistNode is a 32 byte struct describing a ziplist for a quicklist.
* We use bit fields keep the quicklistNode at 32 bytes.
* count: 16 bits, max 65536 (max zl bytes is 65k, so max count actually < 32k).
* encoding: 2 bits, RAW=1, LZF=2.
* container: 2 bits, NONE=1, ZIPLIST=2.
* recompress: 1 bit, bool, true if node is temporarry decompressed for usage.
* attempted_compress: 1 bit, boolean, used for verifying during testing.
* extra: 12 bits, free for future use; pads out the remainder of 32 bits */
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
/* quicklistLZF is a 4+N byte struct holding 'sz' followed by 'compressed'.
* 'sz' is byte length of 'compressed' field.
* 'compressed' is LZF data with total (compressed) length 'sz'
* NOTE: uncompressed length is stored in quicklistNode->sz.
* When quicklistNode->zl is compressed, node->zl points to a quicklistLZF */
typedef struct quicklistLZF {
unsigned int sz; /* LZF size in bytes*/
char compressed[];
} quicklistLZF;
/* quicklist is a 32 byte struct (on 64-bit systems) describing a quicklist.
* 'count' is the number of total entries.
* 'len' is the number of quicklist nodes.
* 'compress' is: -1 if compression disabled, otherwise it's the number
* of quicklistNodes to leave uncompressed at ends of quicklist.
* 'fill' is the user-requested (or default) fill factor. */
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned int len; /* number of quicklistNodes */
int fill : 16; /* fill factor for individual nodes */
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
} quicklist;
quicklistNode结构代表quicklist的一个节点
- prev 指向前一个节点
- next 指向后一个节点
- zl 数据指针。如果当前节点没有被压缩,它指向一个ziplist;否则,它指向一个quicklistLZF结构
- sz 表示zl指向的ziplist的总大小,如果他被压缩了,那么它指压缩前的ziplist大小。
- count表示ziplist里面包含的数据项的个数,
- encoding 表示ziplist是否被压缩
- container 保留字段,表示一个quicklistNode是直接存数据,还是使用ziplist存数据,或者采用其他结构类存数据。但是在目前实现中是一个固定值2,表示ziplist存数据
- recompress 这个节点之前被压缩没有,当我们使用lindex这样的命令查看某一项本来被压缩的数据时,需要把数据暂时解压,这时就设置recompress=1 做一个标记,等空闲时候再次把数据重新压缩。
- attemped_compress
- extra 其他扩展字段 目前弃用
quicklistLZF结构表示一个被压缩的ziplist。
- sz 表示压缩后的ziplist大小
- compress 柔性数组(flexible array member) 存放数据压缩后的ziplist字节数组
quicklist是真正的保存quicklist的结构
- count 所有ziplist数据项的总和
- len quicklistNode节点的个数
- fill ziplist大小的摄者 存放 list-max-ziplist-size
- compress 节点压缩深度 存放 list-compress-depth
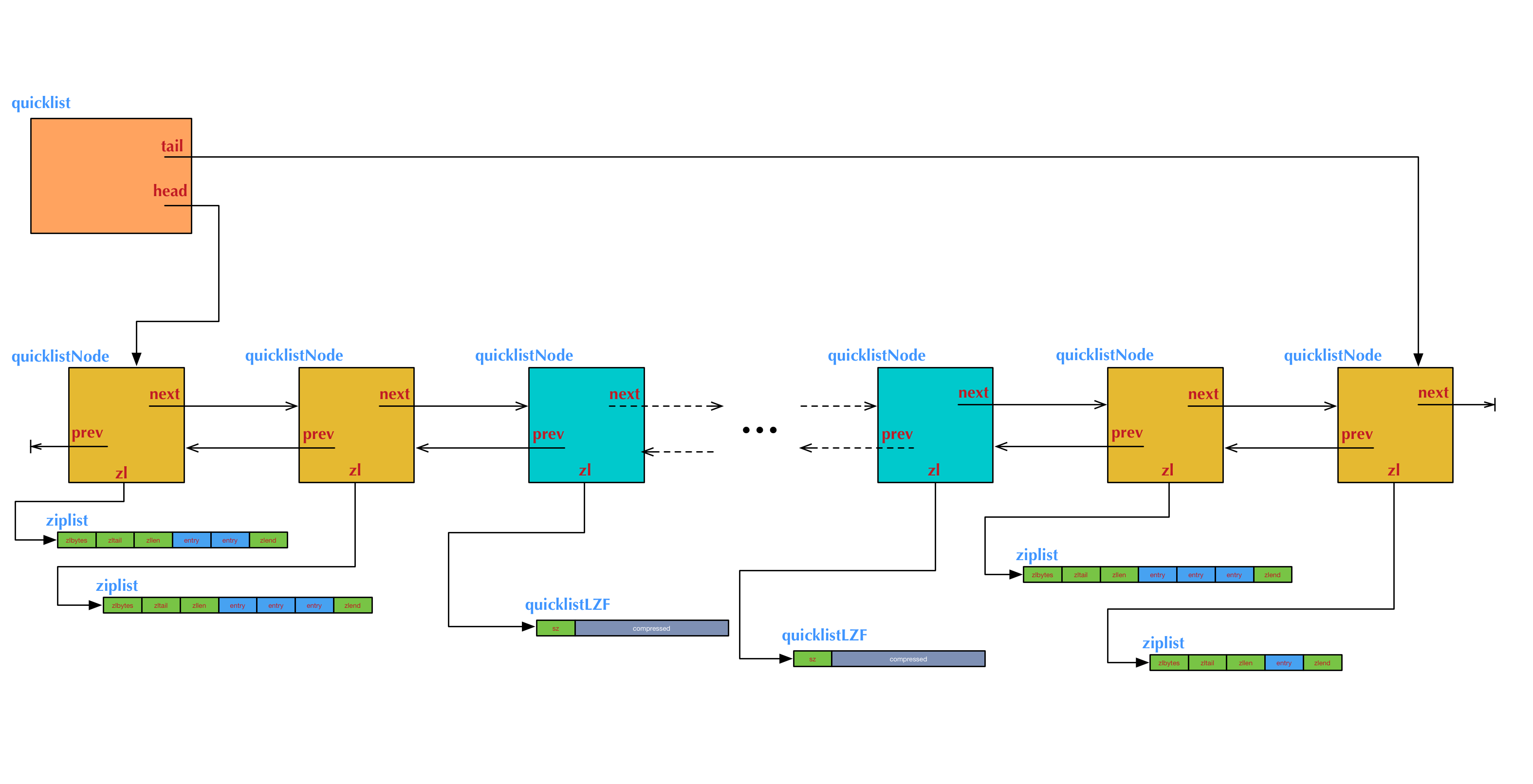
上图为一个quicklist结构图 对应的fill和compress 配置 为
list-max-ziplist-size 3 list-compress-depth 2
其中左右两端各有两个黄色节点,是没有被压缩的,他们的数据指针zl直接指向ziplist结构。中间的蓝色节点是lzf压缩过的,zl指针指向quicklistLZF结构。
左侧头结点上的ziplist有两项数据,右侧头结点有1项。
quicklist插入
- 头尾节点插入时,如果对应节点的ziplist大小没有超过限制,则新数据直接被插入对应ziplist;如果超过限制,那么新建一个quicklistNode节点,把待插入节点插入新的ziplist中。
- 如果插入的位置是链表中间部分,当插入位置所在的ziplist没达到大小限制,直接插入对应ziplist;
- 当所在的ziplist大小超过了限制,但插入的位置在ziplist两端,如果相邻节点的ziplist没有超过大小限制,那么就插入相邻节点
- 如果相邻节点的大小超过了限制,那么新建一个quicklistNode,插入对应节点
- 对其他情况,需要吧当前ziplist分裂成两个节点,然后在其中一个节点中插入数据。

