【PA】模板攻击 matlab代码总结(三)
一 原理
模板攻击 - 火腿烧豆腐 - 博客园 (cnblogs.com)
大多数的序列密码算法相对来说抵抗边信道攻击的能力比较强。由于序列密码算法没有和密钥相依赖的计算分支所以时间攻击和简单功耗攻击无法奏效。而在很多场合差分功耗攻击和差分电磁攻击很难获取足够的测量次数,以成功的进行攻击。针对这种情况有研究者提出了模板攻击( Tem plate Attack)的概念。
模板攻击方法最早由 Rohatgi 等人在 2002 年的密码硬件与嵌入式系统国际会议(Cryptographic H ardw are and Embedded Systems, CHES’2002)上提出[34]。随后在 CHES’2005 上,Agraw al 等人也发表文章提出将模板攻击方式与差分功耗攻击(Differential Pow er Attack , DPA )相结合的模板加强 DPA 攻击(Template-Enhanced DPA attack)[35]。2006 年,Archambeau 等人在 CHES’2006 上发表文章提出从测
量样本中选取有效点构成样本的主子空间(principal subspaces)以减小模板攻击的运算量的方法[36]。也是在此次会议上,Gierlichs 等人将模板攻击和随机方法进行比较,利用基于 T 检验的算法评价了模板攻击的效率[37]。欧美学者的研究结果表明,模板攻击是一种十分有效的边信道攻击方式。从信息论的角度上来考虑,在可能得到的样本曲线数量有限时,模板攻击方式可能是最强有力的攻击方式了[34] 。
针对密码芯片的模板攻击仍旧是边信道攻击的一种。Rohatgi 等人实现的模板攻击是根据加密芯片在运行过程中泄漏出来的功耗信息的数据相关性和操作相关性来实现攻击[34]。简单而言,模板攻击是先对密码算法的密钥空间中所有的密钥分别构建一个具备泄漏信息特征的模板,随后根据获取到的一次或有限次的泄漏信息数据来寻找最匹配的模板,进而推断最可能的正确密钥或者有效的缩小密钥搜索空间的一种攻击方式。由这里可以看出进行模板攻击的前提是攻击者能够获取并完全控制一个与目标芯片相同或者类似的芯片。因为只有这样,攻击者才可以不受限制的多次调用一个与目标芯片相同或者类似的芯片,以构建模板。随后将从目标设备上获取的信息与模板对比匹配。匹配效果最佳的模板对应的密钥就是最可能的正确密钥。
模板攻击可以分为两个步骤。第一步模板构建。第二步模板匹配。根据 Chari等人的工作[34],我们来说明进行攻击的每一步的工作。
1.首先是模板构建阶段。
在真正的对目标芯片进行攻击之前,需要预先为每个可能的密钥都构建一个模板。这里的模板即是一条能耗曲线。该模板反映了与密钥对应的电磁曲线的统计特性。也就是说模板反映了电磁曲线上所有点的概率分布特性。它是按照密钥值来分类。模板的数量与算法的密钥空间中所有可能的密钥总数一致。即如果算法所有可能的密钥总数为 n 个,那么我们需要建立的模板总数即为 n 个。具体的构建方法如下。
首先对每个密钥,在使用这个密钥进行加密时测量边信道信息获取对应该密钥的数据。【?是同密钥同明文,还是可以同密钥不同明文?】此时,需要测量多次,以使得结果更加精确。假设一共测试了 m 次,获得了 m 个原始样本曲线,每个原始样本曲线上有个l个采样点。随后对所有的 m 次采样结果,求平均值。所有的均值向量组成均值矩阵 M 。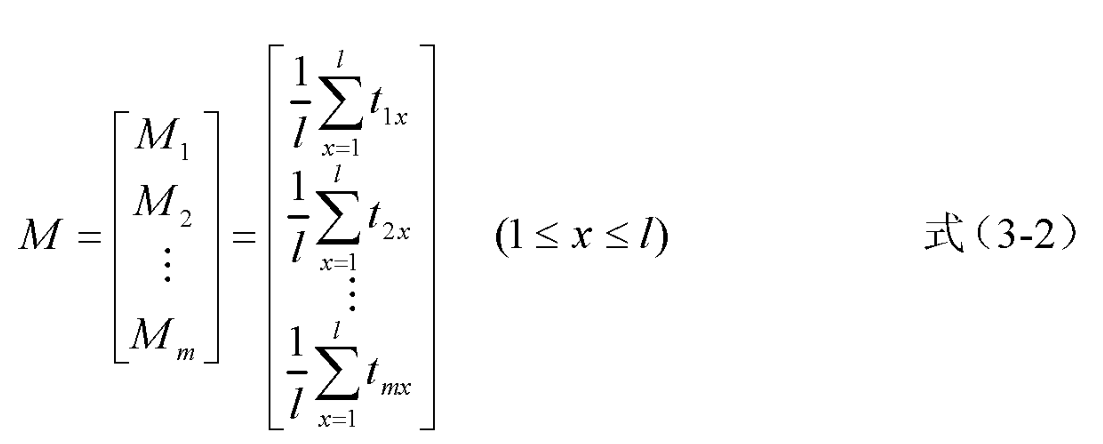
在求取平均值的过程中,每次测量的噪声得到了抑制。因为所有的原始样本曲线都是在加密芯片执行同一个操作时获取的,所以每一次测量存在的随机噪声可以用单个样本曲线与样本均值做差来求得。所有密钥的噪声可以组成噪声矩阵 N。协方差可以用来描述两个随机变量的线性相关性,用噪声矩阵中的两个随机变量Nu 、Nv 之间的协方差来表示两者之间的相关性。![]()
为了描述噪声矩阵中每两个随机变量两两之间的协方差,我们可以建立如下的协方差矩阵,记为 COV。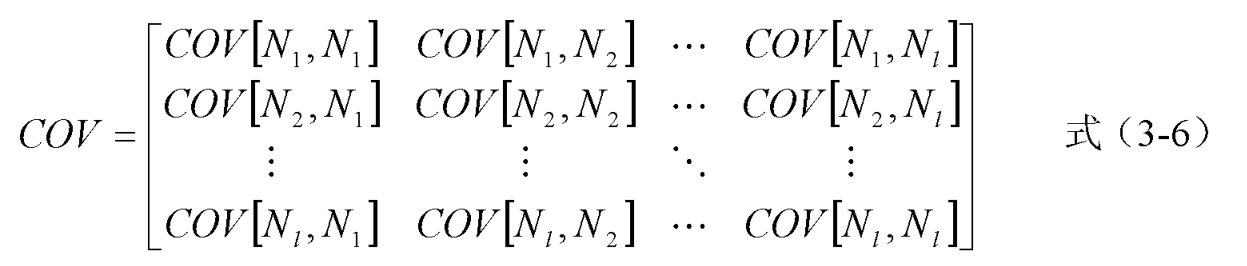
至此,我们就可以为每一个密钥定义一个 2 元组 T,该二元组由均值矩阵M和协方差矩阵 COV 构成。如下式表示。![]()
到这里,我们就为一个密钥建立了一个模板 T。随后重复这样的工作,直到所有的密钥都建立其对应的模板为止。
2.模板匹配阶段(实际攻击阶段)
通过完全被控制的芯片完成了所有模板的构建后,当目标芯片工作时时,使用采集样本曲线同样的方式,就可以采集到芯片运行时的样本曲线。将该曲线与建立好的模板进行比较。根据极大似然法则,匹配概率最大的模板就是匹配得最好的模板。而该模板对应的密钥就是最可能的正确密钥。 记采集到的曲线为 t,匹配概率为 PNi ,匹配模板的公式如下:
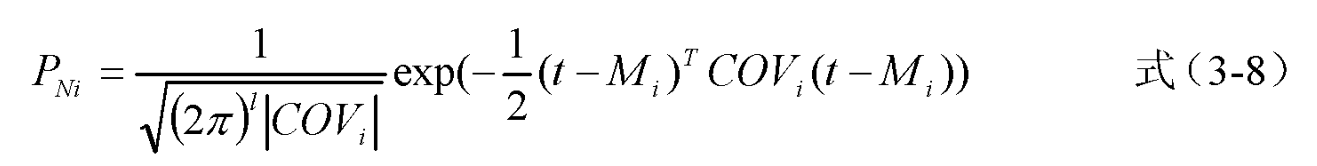
样本量越大,模板就会越准确,所以为了准确的给一个密钥创建这样的一个模板,需要采集尽可能多的电磁样本。这也是为什么模板攻击的前提是攻击者需要完全掌握一个与目标芯片相同或者近似的设备。因为只有这样,攻击者才可以按照自己的意图,进行大量的实验,采集到足够的样本曲线。
由于在实际的测量过程中,每个原始样本曲线的采样点数量非常庞大,增加了计算和分析的难度所以在实际分析的过程中可以先对采集到的原始样本曲线进行预处理。从所有的采样点中选取少部分和密钥密切相关的有效点组成样本曲线,而舍弃大部分的采样点。
根据 Rechberger[39]的研究,我们可以将每次测量的噪声与均值两两作差后的绝对值求和,取计算结果大的一部分点为实际构建模板所用的样本点。这样在精确度降低不多的情况下,既可以保证攻击的有效性,又提高了攻击的时效性。经过预处理之后,选取出的采样点则重新组成一个新的矩阵,我们称之为样本矩阵。然后使用这个样本矩阵代替原始数据矩阵进行建立模板的工作。
对密钥过长问题,可以通过分段处理的方式,来降低处理的难度和计算量。例如若密钥长度为 n1,那么我们所需要建立的模板数量就是 2n1个。但是如果进行分段处理,将总长为 n1的密钥分为长为 n2的小段。这样对每一段密钥需要建立的模板总数就是 2n2个。对整个密钥,需要建立的模板总数即为 2n2 (n1/ n2)个。明显的,前一个模板数量 2n1大于 2n2 (n1/ n2)。考虑到,还可以利用已经建立的模板来匹配其后的曲线,则所需要的模板总数还将减少。
二 部分代码
%% Creating templates
%% Configuration section:
key_byte = 1;
num_traces_templates = 100;
%% Initialisation section
load('interesting_points_sbox_output.mat')
% create new template object
disp('Creating templates ...');
input = textin(1:num_traces_templates,key_byte);%明文
k = repmat(knownkey(key_byte),num_traces_templates,1);%真实密钥
test_hw_sbox_out = HW(S(bitxor(input,k)+1)+1)';%S盒输出
%% Template Creation
% Templates for parts of a round: HW(S(D+K))
disp('Preparing templates ...');
templates = [];
for i=0:8
elem_des = sprintf('HW(S(K+D)) %d',i);
fprintf(1,elem_des);
fprintf(1,'\n');
indices = find(test_hw_sbox_out == i);
% 相同的H放在一起
for t=1:length(indices)
traces_in(t,:) = pear_traces(indices(t),:);
end
mean_vec=mean(traces_in);% 均值向量
cov_mat=diag(cov(traces_in))';%协方差矩阵
elements = struct('mean_vec',mean_vec,'cov_mat',cov_mat,'elem_des',elem_des);
templates = [templates;elements];
end
save templates.mat templates
%% Testing templates
%% Configuration section
load('data_test_47.mat')
load('interesting_points_sbox_output.mat', 'interesting_points_sbox_output')
key_byte = 1;
num_traces_testing=7 ;
%% Testing
% Prepare the intermediate values and then perform the template matching.
% Count the correct matches and output the classification performance.
disp('Testing templates ...');
traces_text = traces(1:num_traces_testing,interesting_points_sbox_output);
test_input = textin(1:num_traces_testing,key_byte);
% test_keyvals = repmat(knownkey(key_byte),num_traces_testing,1);
test_keyvals = keylist(1:num_traces_testing,key_byte);
test_hw_sbox_out = HW(S(bitxor(test_input,test_keyvals)+1)+1)';
load('file_000001.mat');
templates = elements;
% Initialise statistics for performance evaluation
classification_performance=zeros(1,9);
clear HW S traces textin key_byte test_input textout
%%
for i=1:num_traces_testing
trace = traces_text(i,:);
% Testing for HW(S(D+K))
logp_match = template_matching(trace,templates');
[val,pos] = min(abs(logp_match));
% do the statistics
classification_performance(pos) = classification_performance(pos) + (pos-1==test_hw_sbox_out(i));
end
%% Results
% Print the classification performance
fprintf(1,'\r\nClassification performance of the template: %2.2f %% \n',sum(classification_performance)/num_traces_testing*100);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号