了解各种AA特性
AA(Anti-Aliasing)抗锯齿想必不少玩家在游戏画质设定中经常会遇到,说通俗一点AA抗锯齿的作用:将图像边缘及其两侧的像素颜色进行混 合,然后用新生成的具有混合特性的点来替换原来位置上... AA(Anti-Aliasing)抗锯齿想必不少玩家在游戏画质设定中经常会遇到,说通俗一点AA抗锯齿的作用:将图像边缘及其两侧的像素颜色进行混 合,然后用新生成的具有混合特性的点来替换原来位置上的点以达到柔化物体外形、消除锯齿的效果。随着图形技术的不断革新,AA抗锯齿的技术也随之在不断的 发展和改进。面对游戏画质设定选项中“品种繁多”的AA抗锯齿,我们玩家应该如何选择了,你是否对没一种AA抗锯齿选项有所了解?那么今天显卡帝就来为您 详细解读AA抗锯齿的前世今生,让你开开心心对AA抗锯齿弄个明白。
显卡帝揭秘AA抗锯齿的前世今生

从本文中,网友朋友将会和显卡帝共同来探讨和解密如下问题:
一、AA抗锯齿技术的基本原理是什么;
二、Hardware AA的特点及相关AA技术;
三、Post process AA的特点及相关AA技术;
四、Hybrid AA的特点及相关AA技术;
以上目录也正是本文的大致行文思路,显卡帝希望能够通过循序渐进的分析与解读让众多玩家能够对AA抗锯齿有更深入的认识,并且能够在读完本文之后能对AA抗锯齿技术的大致分类有个清楚的认识。
详解AA抗锯齿基本原理
AA(Anti-aliasing):标准翻译为“抗图像折叠失真”。说通俗点,AA就是在栅格化图形中次像素精确级的渲染技巧。因为电脑屏幕显示单位是
像素,它是屏幕上最小的那一个个小方块。大家只要靠近电视仔细观察就会发现一个个红绿蓝色的小点,这即是像素点。然而,曲线和角的如果用方块状的像素来表
现,这显然是“不大方便的”,因为曲线和角容易产生“狗牙般”的锯齿。AA就是解决这一难题的一项技术,其目的就是让图像看起来更加平滑自然。总之,进过
AA处理过后的图像消除了锯齿所带来的“方块感”。
左边的图是非常平滑的,但右边的则显得一块一块的

从上面这张图我们可以很直观的看出未采用AA抗锯齿技术处理的图像要比采用AA抗锯齿处理过后在“方块感”上面要严重许多。
AA的前提非常简单。请看下面这个图表:
圆的平滑过渡

首先假设你要想在屏幕上表现一个圆,若圆的尺寸很大,那么通过很多很多的像素进行排列即可,但如果要表现一个小尺寸的圆,因为提供给你所控制的像素点数量 很少,故而通过像素方块所构建起来的圆最后可能是啥也不像。此刻,AA抗锯齿正好帮上了大忙。我们先将圆放大(最左边第一个圆),再将其和一个像素栅格对 齐,每个方块代表一个像素。这时你会发现栅格里的好多像素都没有填满,且填充的比例也不尽相同。然后,我们的目标就是找出这些不完全填充的格子,根据填充 的比例挑选基本色(这里是黑色)的相应比例来填充进去,即得到了第四个圆。仔细分析下这个圆,全填黑色的是那些格子里完全填充的,而某些50%填充的就填 入一个50%的灰进去,75%的就填入75%的灰,等等。最后我们将填好图的第四个圆缩小为原始大小,即得到了第5个圆,效果是不是很不错哈。不过这种方 法只部分适用于“像素艺术”领域里,因为像素点的尺寸和颜色的数量都是有限制的。
值得一提的是,AA有正确的用法也有错误的用法。正确的方法是如上面所示造成平滑过渡的感觉。错误的方法是像下图的最左边的图在黑色边线的外围全部加上50%的灰度像素:
AA有正确的用法也有错误的用法

刚刚接触AA抗锯齿时,人们往往会犯一个错误:即将每一“步”都加入一单个浅色像素。其实这种方法显的十分糟糕。中间的方法是正确的:只再需要的地方加适 合的过渡像素。虽说此刻弧线开起来平滑了些,但锯齿感还没有完全消除。最后边的则是最佳的方法:加两层过渡色,弧线看起来变的更加平滑。所以,单个的分离 像素通常不是最好的AA过渡,而同色线条或像素组可以将AA效果表达得更好。
OK,以上介绍了AA的基本前提,不过你会发现我们仅仅介绍了黑白两种颜色的情形。倘若换成彩色,又该怎么办了?其实方法和黑白情况下的AA过渡差不多,只是不再是检查黑色的百分比例,而是检查每种颜色的比例了。上图:
每一个方块代表着两种或三种不同颜色之间准备用像素来过渡

左边第一个,是黑色和白色(在上面我们已经讨论过了)。我们找到用来过渡黑与白的过渡色是一种中间灰。这个颜色是靠混合白色所占的比例之白色和黑色所占的 比例之黑色混合而得到的。同样混合红色和黄色,我们得到橙色,然后深绿+蓝色=海蓝色,在最右边我们有一点点变化:3种颜色在一起。我们用同样的方法来对 待,混合之后得到一个有点蓝的紫色。方法确实并不复杂,但这些都是在可以无颜色限制情况下使用的,因为实际情况中是不可能有一个无限色盘来做AA过渡的, 即使有也很费时间。所以我们只能用不断尝试的方法来选出合适的AA过渡色,直到成功为止。
AA前世今生之:Hardware AA
进过了前面对AA抗锯齿技术原来剖析,相比玩家对AA已经有了一个初步的认识。AA抗锯齿技术在进过几十年的发展,从离线渲染逐步过渡普及到实时渲染的时
代,AA在图形学中被广泛地用于了提升渲染质量上面。接下来,我们就对实时渲染中所使用的AA方法的前世今生做一个详细阐述。首先我们要讲的是由硬件支持
的AA方法。
图1:一个像素内部的采样点

上图是一个像素内部的采样点。16个红圈表示16个采样点,蓝色和黄色是覆盖了这个像素的两个三角形。我们通常所说的几倍抗锯齿指的就是一个像素点内的采样点数。
SSAA(Super Sampling Anti-Aliasing)超级采样抗锯齿
SSAA是最为直观的一种AA,也是很早期的一种AA抗锯齿方法。其基本思想是:这样就等于把一幅模糊的大图,通过细腻化后再缩小成清晰的小图。其实现方
法之一:先渲染一个大图,再Downsample(降低采样率),这可以等效为在每个最终像素内部做了一个均匀分布采样。更通用的描述是,每个像素分布多
个采样点(可以均匀分布、Poisson分布、随机分布、抖动分布等),每个采样点都有独立的color和depth,pixel
shader在每个采样点都执行一遍。如上图的情况,会得到1个白色,1个浅蓝色和14个黄色的采样点。最后这个像素的值是这16个采样点的平均,也就是
白色((1, 1, 1) + 浅蓝色 (0.77, 0.77, 1) + 14 * 黄色(1, 1, 0)) / 16 = (0.98,
0.98, 0.125)。在这些方法中,SSAA质量最好,毕竟是个最原始最暴力的方法。在D3D
10.1+上可以选择per-sample或者per-pixel执行pixel
shader,也就是直接支持了SSAA。性能统计(采样数为N,下同):每个像素里PS(pixel
shader)执行次数为N,占用空间N个color + N个depth。总之SSAA抗锯齿,简单直接但比较消耗资源。
MSAA(MultiSampling Anti-Aliasing)多重采样抗锯齿
MSAA是一种特殊的超级采样抗锯齿(SSAA)。MSAA首先来自于OpenGL,具体是MSAA只对Z缓存(Z-Buffer)和模板缓存
(Stencil
Buffer)中的数据进行超级采样抗锯齿的处理。其基本思想是:只对多边形的边缘进行抗锯齿处理。我们知道SSAA需要在每个采样点都执行一次PS并保
存color和depth,时间和空间开销都是相当惊人的。MSAA的出现极大地改善了这一点。MSAA在每个像素只执行一次PS,输出颜色写入所有通过
depth-stencil测试的采样本中。在Shader Model
3之前,PS的输入一定取自像素的中心;后来加入了centric插值,PS的输入属性就可以是三角形所覆盖的所有采样点的中心:
有无centric插值的对比

如图1的情况,没有centric插值的话,蓝色三角形的两个采样点将都得到纯蓝的颜色(外差而得),最终像素的颜色就是(2 * (0, 0, 1) + 14 * (1, 1, 0)) / 16 = (0.875, 0.875, 0.125)。有centric插值的话就是个更正确的浅蓝色((1, 1, 1) + (0.77, 0.77, 1)) / 2 = (0.885, 0.885, 1),最终像素颜色是(2 * (0.885, 0.885, 1) + 14 * (1, 1, 0)) / 16= (0.98, 0.98, 0.125)。如下图所示:性能统计:每个像素里PS执行次数为每个覆盖到该像素的三角形一次,占用空间N个color + N个depth。总之,MSAA对资源的消耗需求大大降低,不过在画质上略不如SSAA。
CSAA(CoverageSamplingAnti-Aliasing)覆盖采样抗锯齿
NOAA,MSAA,CSAA的对比

CSAA是NVIDIA在G80及其衍生产品首次推向实用化的AA技术,也是目前nVidia GeForce 8/9系列独享的AA技术。MSAA虽然解决了计算的问题,但存储量还是很大,尤其是采样率到了8以上。而CSAA就是在MSAA基础上更进一步的节省显 存使用量及带宽,简单说CSAA就是将边缘多边形里需要取样的子像素坐标覆盖掉,把原像素坐标强制安置在硬件和驱动程序预先算好的坐标中,这样就可以用较 少的color/depth空间来存储原先高采样数才能得到的画质。例如图1,我们用CSAA 16x(即16个采样点)来渲染,就会把一个像素分成左上、右上、左下和右下4块区域,每块区域有4个coverage采样点,但共享同一个color和 depth。对于图1的情况,结果就是,(0.25 * (0.885, 0.885, 1) + 0.25 * (0.885, 0.885, 1) + 3.75 * (1, 1, 0)) / 4 = (0.98, 0.98, 0.125)。性能统计:每个像素里PS执行次数为每个覆盖到该像素的三角形一次,占用空间M个color + M个depth,M小于N。总之,CSAA就好比取样标准统一的MSAA,能够最高效率的执行边缘取样,效能提升也相当显著。比方说16xCSAA取样性 能下降幅度仅比4xMSAA略高一点,效果却几乎和8xMSAA一样。8xCSAA有着4xMSAA的处理效果,性能消耗却和2xMSAA相同。
AA前世今生之:Post process AA
SSAA、MSAA和CSAA这几种AA方法都是由硬件直接支持的,故而带来了不小的额外资源开销。一方面AA对显存资源的消耗是巨大的,再者,这些AA
方法对Edge(边缘)的考量都是原始边界,并没有去考虑这个边缘是否真的需要AA,故而会浪费一些计算量。在GPU Gem
2的第9章Deferred Shading in S.T.A.L.K.E.R.,其首次面向游戏界宣传了Deferred
Shading(延迟渲染)的概念。,同时也提及了Deferred框架无法使用硬件MSAA的问题。虽然Deferred
Lighting解决了其中的问题,但再次渲染一遍场景的代价还是不小的。更重要的是,由于Deferred框架的引入,人们终于开始正视MSAA实际上
造成了很多时间和空间的浪费。于是乎这几年基于Post process(后处理)的AA方法蓬勃发展,大有取代硬件式AA的气势。
Edge AA
Edge AA就是Deferred Shading in S.T.A.L.K.E.R提出的方法,根据“邻居像素”的depth和normal的差异程度做一个边缘检测,每个像素可以得到一个权重,表示“像边缘的程度”:
根据这个权重,就可以把邻居像素的颜色拿来插值,得到AA的效果

在GPU Gems 3第19章Deferred Shading in Tabula Rasa中,NCsoft对Edge AA做出了一些小改进,边缘检测不再依赖于图像分辨率,且更加稳定。
Directionally Edge AA
Edge AA开创了post process AA的时代,但Edge
AA暂时在质量上还无法与硬件式AA相抗衡。随后,AMD在HPG09上的论文A Directionally Adaptive Edge
Anti-Aliasing Filter改进了Edge
AA,不再采用独立的edge点来决定AA混合的方式,而是根据edge点周围的状况确定出isoline(等值线),然后根据isoline的垂直方向
来确定混合的方向。这样一个边界就会沿着朝向来混合,还原出更加精确的sub-pixel信息。这种方法进入了AMD的驱动,只要打开Adaptive
AA就会自动启用。
MLAA(Morphological Antialiasing)形态抗锯齿
Adaptive Edge
AA提出了以线代替点的研究方向,但isoline的计算量毕竟比较大,启用了之后对渲染性能下降明显。Intel推出的完全基于CPU处理的抗锯齿解决
方案--Morphological
Antialiasing再次在这个方向作出了努力。它不计算isoline,而是把edge分门别类,总结成Z、U、L等几种特定的形状,而Z和U都可
以分解成L。
Z和U都可以分解成L

最终根据L划出一个三角形,确定混合区域,这样就省去了所有繁重的计算,提高AA速度。在AMD较新的驱动里,MLAA取代了Directionally Edge AA成为Adaptive AA的首选。MLAA的框架又派生出多个不同的方法:
CPU MLAA
Intel在HPG09上的Morphological Antialiasing一文是在CPU上实现的。代码用了非常深的分支来判断edge形状,完全是针对CPU优化的,不适合GPU硬件,也不适合实时渲染的情况。
GPU MLAA
SIGGRAPH 2010 poster的Practical morphological antialiasing on the
GPU,通过建立SAT来判断edge形状,需要log(width)+log(height)个pass。在确定了L之后,需要查询一个预计算的
512×512
R32F的纹理,里面每个texel对应了一个特定大小的L所需要混合的面积。也就是边长最大是512个像素。可以看出这种方法非常暴力,虽然可能比读回
CPU快,但开销还是很大。
Jimenez’s MLAA
GPU Pro 2里的文章Practical Morphological Anti-Aliasing提出了一个更实用的GPU
MLAA方法,命名为Jimenez’s
MLAA以示区分。在这种MLAA里,Z和U不需要分解成更简单的L,直接用一个预计算的表来做查询。每个像素根据自己在形状里的位置在查找表里寻找需要
混合的各个像素。720p的分辨率下,这种方法在一般的情况下能达到Xbox 360上3.79ms,Geforce 9800
GTX+上0.44ms。同等条件下8x MSAA需要5ms。
FXAA(Fast Approximate Anti-Aliasing)
NVIDIA在Graphics SDK 11里面提供了一个称为Fast Approximate
Anti-Aliasing的方法。该方法非常接近MLAA,但只识别长边,而不识别形状。有了长边之后,就可以根据边和像素的求交来估算每个像素中
sub-pixel的覆盖率,并进行AA混合。后来Timothy Lottes还发展出了FXAA II,质量有所下降,速度提高了,在Xbox
360上,720p的分辨率可以做到2.0ms。
No AA与FXAA的对比

另一个在GDC11上公开的AA方法称为Directionally Localized Anti-Aliasing(前面介绍的Jimenez’s MLAA和FXAA也在GDC11的时候公开的)。这种方法比较特殊,它在垂直方向模糊后的图像上做水平方向边缘检测,得到的结果合成回去就得到AA后的 图像。
左图为AA之前的,右图是经过DLAA的

DLAA的执行效率还是比较快的,据在Xbox 360上的测试来看,720p需要2.2ms。
总之:后处理式AA的方法就是试图通过Pixel像素信息估计出Sub-pixel级别的几何,然而再做AA。不同的是:Edge AA是通过独立点来估计,MLAA是通过L形来估计,FXAA和DLAA是通过线段来估计。
AA前世今生之:Hybrid AA
前面我们介绍了硬件式AA和后处理式AA抗锯齿方法,那么有没有将两者结合起来的解决方案了?这正是下面要讲的Hybrid AA(混合式AA)。我们先对MSAA的计算浪费这一事实进行下对比说明:
MSAA需要计算的edge

真正需要计算AA的edge

通过上面的对比图,我们很直观的感受到:真正需要进行AA处理的Edge边缘其实并不是特别多,而MSAA实际上是将很多的计算量浪费在了实际并不需要 AA的像素上,所以采样点越多,浪费越严重。透过前面对后处理式AA的介绍,我们知道:后处理式AA的方法就是试图通过Pixel像素信息估计出Sub- pixel级别的几何,然而再做AA。不同的是:Edge AA是通过独立点来估计,MLAA是通过L形来估计,FXAA和DLAA是通过线段来估计。而Hybrid AA的思想即是:干脆就先直接存出sub-pixel的几何,没必要进行“估计”。
SRAA(Subpixel Reconstruction Anti-Aliasing)
SRAA是NVIDIA的研究员在I3D2011上发表的新方法。它寄予的事实是,shading的变化频率一般低于几何的变化频率,所以可以在较低分辨
率上shading,而用较高分辨率恢复几何。SRAA的基本流程为,在Deferred
Shading的框架中,渲染一个高分辨率(或者带MSAA)的G-Buffer,但在shading的时候仅在普通的分辨率(或者没有MSAA)的情况
下做。累积的结果通过G-Buffer重建sub-pixel信息,来进行类似MLAA的AA计算。这种方法结合了MSAA和MLAA,优点是可以用较低
的样本数做到较高的MSAA才能得到的效果,同时不增加shading的计算量。SRAA由于原理问题,只能用在Deferred框架中。
Subpixel Reconstruction Anti-Aliasing

GPAA(Geometric Post-process Anti-Aliasing)
GPAA是Humus独立提出来的AA方法。基本思路是在渲染几何之后再次用线框模式渲染一遍,这时候可以得到每个三角形在每个pixel的覆盖率:
Geometric Post-process Anti-Aliasing
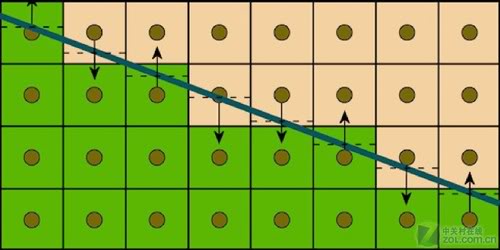
通过这个覆盖率,计算AA就显得相当容易了,结果比较如下:
对比

这种方法的代价是多了一遍线框渲染,但可以用于Forward和Deferred两种框架。遗憾的是,Humus的twitter上说这种方法实际上在1996年就被别人申请专利了。
Adaptive AA
Intel在SIGGRAPH 2010的course Deferred Rendering for Current and Future
Rendering
Pipelines上提到了一种很简单很暴力的AA方法,在edge的地方per-sample计算,在non-edge的地方per-pixel计算。
和基于post
process的方法一样,这需要执行一个边缘检测,并在stencil(模板)中标记出来,然后就可以分别计算了。下图中红线标记的地方就是检测出来的
edge:
红线标记的地方就是检测出来的edge

这种方法的结果会和SSAA一样,同时没有MSAA重复计算的毛病。
总之:Hybrid AA可以说是hardware AA 和post process AA 这两种AA方案的折中选择。优点是可以用低于hardware AA的硬件开销和计算量达到一样的效果,缺点是需要修改原有的图形渲染流水线。
总结:AA抗锯齿就是为了降低方块感
总结:AA抗锯齿就是为了降低方块感
通过前面系统的介绍,想必玩家朋友已经对AA抗锯齿有了更深入的认识。锯齿的产生是因为在3D图像中,受分辨率的制约,物体边缘总会或多或少的呈现出一些
不够平滑的“棱角”,而抗锯齿就是之通过对图像边缘进行柔化处理,使图像边缘看起来更平滑,更接近实物的物体。所以AA抗锯齿是一种提高画质并使之柔和的
渲染方法。最后我们总结下本文的核心知识点:
一、AA抗锯齿的作用:将图像边缘及其两侧的像素颜色进行混合,然后用新生成的具有混合特性的点来替换原来位置上的点以达到柔化物体外形、消除锯齿的效果;
二、我们通常所说的几倍抗锯齿,指的是是一个像素点内的采样点数;
三、AA抗锯齿按照技术发展的演进历程来分类有:Hardware AA、Post process AA 和Hybrid AA ;
四、Hardware AA(硬件式AA)特点:原理简单直接,但硬件资源消耗较大。该类别的AA技术:SSAA、MSAA和CSAA等;
五、Post process AA
(后处理式AA)特点:后处理式AA的方法就是试图通过Pixel像素信息估计出Sub-pixel级别的几何,然而再做AA。不同的是:Edge
AA是通过独立点来估计,MLAA是通过L形来估计,FXAA和DLAA是通过线段来估计。该类别的AA技术:Edge AA
、Directionally Edge AA 、MLAA和DLAA等;
六、Hybrid AA (混合式AA)特点:Hybrid AA可以说是hardware AA 和post process AA
这两种AA方案的折中选择。优点是可以用低于hardware
AA的硬件开销和计算量达到一样的效果,缺点是需要修改原有的图形渲染流水线。该类别的AA技术:SRAA 、GPAA和Adaptive AA等;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号