Level DB 小调研
一、 概况:
1、 背景:
随着信息技术的高速发展,数据存储量和流量呈现爆炸式增长。目前百度统计日 PV(日点击量)已超过 75 亿次,中国网民在百度上进行50 亿次的搜索请求,百度贴吧日 PV 十亿,每天发帖三千多万;百度知道为中国网民解决了2.3亿个问题,日均 PV4.17 亿。百度的数据总量已接近几千个PB,每天要响应几百万次的搜索请求,每天处理 100PB 数据。
如此庞大的数据量给数据储存系统带来了巨大挑战,单机PC基本无法处理如此大量的PB级数据,分机存储成为大势所趋,于是自上世纪便提出的分布式系统理论成为当下最优解,Level DB也在近年应运而生。
2、简介:
Level DB 是一个持久性数据存储量能达到 Billion 级别的非常高效的键值型C++函数库,于2011年由Google发布。在其底层实现上使用了 LSM-tree(Log Structured Merge Tree)算法,以牺牲随机读换取顺序写,从而实现了数据的高效持久化存储。
LSM-tree 的思想其实非常易于理解,就是将对数据的大量修改以增量的形式保持在内存中,当数据量达到指定的大小限制后将这些修改操作批量写入磁盘,即顺序写;读取时需要合并磁盘中的历史数据和内存中最近的修改操作。LSM 树的优势在于有效地规避了磁盘随机写入问题,但读取时可能需要访问较多的磁盘文件。
Level DB 通过将数据更多地缓存在内存中,提高数据的命中率,避免读数据时过多的访问磁盘,进而提高读数据的整体效率。它有如下特点:
1. 基于 Key/Value 的持久化存储系统,与 Redis 这种基于 Key/Value 的内存型存储系统不同之处在于,Level DB 将大部分的数据存储到磁盘介质上,这样就不会有太多的内存开销,从而提高了效率。
2. 键值是任意字节的数组。数据通过键存储排序。调用者提供一个定制的比较重载的排序顺序。前后迭代是以数据为支撑的。
3. 能够有序的存储记录的键值,在系统中相邻的键值是按照一个比较函数,依次有序的存储在介质中,这个比较方法可以自行定义,Levle DB 根据这个比较方法依次来保存记录。
4. 通过一个虚拟接口,外部活动(如文件系统操作等)就能传送,用户就能定制操作系统的相互作用。Level DB 不仅提供数据读取、写入以及删除等简单的接口,而且也提供批量存取服务。
5. 支持数据快照(可理解为只读权限的数据库。Snapshot 不但有为报表提供静态的视图服务的优点,而且当与数据库镜像结合使用时提供读写分离功能,而最重要的一点可以利用数据库快照来快速恢复数据库。)功能,通过建立瞬间的快照,能够使写操作不会影响到读操作,能够在读操作过程中始终看到一致的数据,避免脏数据等不一致性问题。
6. 支持数据压缩功能,通过使用 Snappy(Snappy 是一个以 BSD 协议开源的开发包,提供数据压缩和数据解压功能。用来压缩较为大量级的数据,其稳定性和健壮性较好。)压缩库自动压缩数据。这对不仅可以增快读/写效率而且有助于减小存储空间。
7. 只是一套 c++程序库,底层提供了抽象接口,允许用户定制,不是 SQL数据库,没有数据关系模型,单机系统没有 client-server。
集群化 Level DB 存储系统解决方案在很大程度上突破了传统意义上附属于主机的存储设备只能存放数据的范畴,而现代的存储系统以大量廉价的普通计算机为基础平台,配合复杂的管理软件来存放海量数据,并能对这些大量级的数据进行管理使其可靠、高效、合理性管理。集群化 Level DB 在大量廉价物理机上,基于 Level DB 核提供基本的数据存储服务,采取各种策略保证数据的完整性、系统的可靠性,使其存储、读写等服务有更高的效率。
二、 原理简介:
实际上 Level DB 就是一个数据存储系统和基于该系统的接口规范。它的存储介质是文件和内存,通过拍照我们能看到这样的情景:

Level DB 整体架构图
如图所示,系统的整体静态架构由六部分组成:内存中的 Mem Table 和Immutable Mem Table;磁盘的 Current 文件、Manifest 文件、Log 文件和 SSTable(Sorted Strings Table)几种主要文件。
Level DB 中的 Mem Table 文件当需要写入一条记录时,系统会先向 log 文件中插入该记录,当成功插入到 log 文件后,再去将该记录写入到 Mem Table 中,成功写入到 Mem Table 后才算完成一次基本写入成功。而说 Level DB 写入速度极快的首要原因,也正是由于它的一次写入数据只涉及到一次内存写入和磁盘写入的操作。
为尽量避免数据丢失,Level DB采用先将数据写入到 Log 文件,然后释放到系统 Memtable,一旦宕机也可以从 Log 将数据恢复到 Memtable。
在插入数据时,Memtable 达到一定大小就会将内容导出到外部文件,Levle DB 会重新生成 Log 文件和 Mem Table,旧的 Memtable 就变为了 Immutable Memtable。从字面上我们就能够看出,Mem Table 的内容 Mem Table 的内容只能进行读操作。新数据会被记录到新产生的 Log 文件和 Memtable 中,同时后台将 Immutable Memtable 到数据保存到磁盘。内存中的记录不停释放到介质中并进行 Compaction 操作后形成了 SSTable,而 SSTable 是由一类层级构成的文件,第一层为 Level 0,第二层为 Level 1,直到第 12 层为止。
SSTable 中的每个文件属于哪一层的层级,而且顺序的存储着记录的 Key值,事实上在文件中 key 值越小的记录排列的顺序越靠前。所以必然有文件中的最小 key 值与最大 key 值,当然这些信息也同样是极为重要的,Level DB 系统中的Manifest 文件负责记载 SSTable 各个文件的管理信息,例如层级信息,文件名称,最小 key 值与最大 key 值等信息。下图是 Manifest存储信息的示意图:
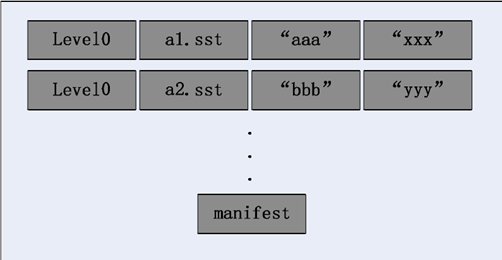
Manifest示意图
如图所示,看到两个文件,即 Level 0 的两个文件,都记在了 key 范围,a1 的 key 范围是“aaa”到“xxx”,文件 a2 的 key 范围是“bbb”到“yyy”,两者 key部分就重叠了。
Current 文件只负责记录当前系统使用的 Manifest 文件名。上面我们知道了系统的运行会不断的进行 Compaction 操作,SSTable 也随之改变,而 Manifest文件也会随之发生改变,同样会产生一个新的 Manifest 文件来记录这些信息,而Current 文件则是记录当前系统所正在使用到底是哪个 Manifest 文件。
以上为Level DB的总体架构,以下展示Level DB读写数据流程图:

Level DB 读取数据流程图
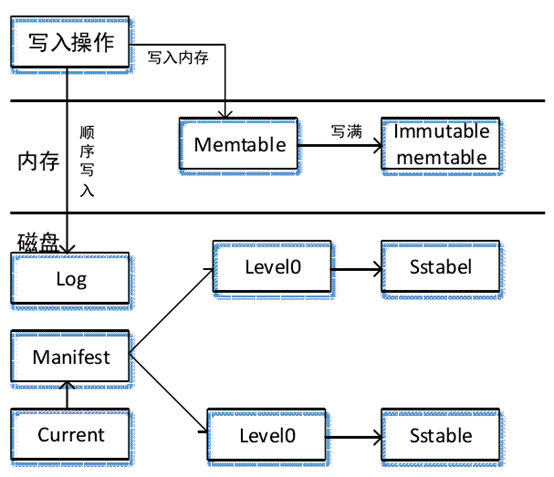
Level DB 写入数据流程图
根据 Google 给出的测试报告,Level DB 具有很高的写入速度,其随机写性能可以达到40万条记录每秒,而随机读性能也达到 6 万条记录每秒。
总而言之,Level DB 是一个非常高效的海量键值存储引擎、一个用 C++实现的类库、一个单机持久化存储系统,广泛应用于各种需要处理庞大数据量的企业中,也十分受到分布式系统研究领域学者们的青睐,近年来在云计算、集群化数据等领域表现活跃。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号