ES 数据管理2
目录:
本文以 8.2.0 版本为例
一、 文档批量操作
1、 批量获取文档数据, 通过 _mget 的 API 来实现的
1.1 、 URL 中不指定 index 和 type, 可以通过ID批量获取不同index的数据
请求参数: docs: 文档数组参数
_index: 指定index _id: 指定id _source: 指定要查询的字段
GET _mget { "docs": [ { "_index": "es_db","_id": 1 }, { "_index": "es_db","_id": 2 } ] }
响应结果如下:
{ "docs" : [ { "_index" : "es_db", "_id" : "1", "found" : false }, { "_index" : "es_db", "_id" : "2", "_version" : 3, "_seq_no" : 7, "_primary_term" : 2, "found" : true, "_source" : { "name" : "douger chueng", "age" : 18 } } ] }
1.2 、 在 URL 中指定 index, 可以通过ID批量获取指定index的数据
GET /es_db/_mget { "docs": [ { "_type":"_doc", "_id": 3 }, { "_type":"_doc", "_id": 4 } ] }
2、 批量操作文档数据, 通过 _bulk 的API 来实现
请求参数: 第一行参数为指定操作的类型及操作对象(index, id);
第二行参数才是操作的数据
主要操作有: create、index、delete 和 update
2.1 、批量创建文档 create , 如果不指定 _id, 则会自动生成随机串为id
POST _bulk {"create":{"_index":"es_db", "_id":3}} {"id":3,"title":"douger","content":"douger666","tags":["java", "面向对象"],"create_time":1554015482530} {"create":{"_index":"es_db", "_id":4}} {"id":4,"title":"mick","content":"mickNB","tags":["java", "面向对象"],"create_time":1554015482530}
2.2 、 普通创建 或 全量替换 index
POST _bulk {"index":{"_index":"es_db", "_id":3}} {"id":3,"title":"cheung","content":"douger666","tags":["java", "面向对象"],"create_time":1554015482530} {"index":{"_index":"es_db", "_id":4}} {"id":4,"title":"lei","content":"mickNB","tags":["java", "面向对象"],"create_time":1554015482530}
2.3 、 批量修改
POST _bulk {"update":{"_index":"es_db", "_id":3}} {"doc":{"title":"吸星大法"}} {"update":{"_index":"es_db", "_id":4}} {"doc":{"title":"Go语言万岁"}}
2.4 、 批量删除
POST _bulk {"delete":{"_index":"es_db", "_id":3}} {"delete":{"_index":"es_db", "_id":4}}
二、 DSL 语言高级查询
Domain Specific Language (DSL) 领域专用语言: 叶子查询子句 和 复核查询子句

1、 无条件查询 : 查询所有, 或者使用 match_all 表示所有
GET /es_db/_doc/_search { "query":{ "match_all":{} } }
2、 有查询条件
2.1、 叶子条件查询(但字段查询条件)
2.1.1 模糊匹配
match: 通过 match 关键词模糊匹配条件内容
prefix: 前缀匹配
regexp: 通过正则表达式来匹配数据
match 的复杂用法:
query: 指定匹配的值
operator: 匹配条件类型
and : 条件分词后都要匹配
or : 条件分词后有一个匹配即可(默认)
minmum_should_match: 指定最小匹配的数量
2.1.2 精确匹配
term: 单个条件相等
terms: 单个字段属于某个值数组内的值
range: 字段属于某个范围内的值
exists: 某个字段的值是否存在
ids: 通过 ID 批量查询
2.2、 组合条件查询(多条件查询)
bool : 个条件之间有 and, or 或 not 的关系
must: 各个条件都必须满足, 即各条件是 and 的关系
should: 各条件有一个满足即可, 即各条件是 or 的关系
must_not : 不满足所有条件, 即各条件是 not 的关系
filter: 不计算相关度评分, 他不计算 _score 即相关度评分, 效率更高
constant_score: 不计算相关度评分
must/filter/shoud/must_not 等子条件是通过 term/ terms / range / ids/ exists / match 等叶子条件为参数的
2.3 、 链接查询(多文档合并查询)
父子文档查询 parent/child
嵌套文档查询 nested
2.4 、 DSL 查询语句: 查询DSL (query DSL) 和 过滤DSL (filter DSL)

# term 精确匹配
POST /es_db/_search { "query": { "term": { "title": "mick" } } } #SQL select * from es_db where title = 'mick';
# 信息模糊匹配, match 根据字段的分词器,进行分词查询 POST /es_db/_search { "from": 0, "size": 2, "query": { "match": { "address": "广州" } } } #SQL select * from user where address like '%广州%' limit 0,2;
# 多字段模糊匹配查询 与 精准查询 POST /es_db/_search { "query":{ "multi_match":{ "query":"张三", "fields":["address","name"] } } } #SQL select * from student where name like '%张三%' or address like '%张三%' ;
# 未指定字段条件查询 query_string , 含 AND 与 OR 条件 POST /es_db/_search { "query":{ "query_string":{ "query":"广州 OR 长沙" } } }
# 指定字段条件查询 query_string , 含 AND 与 OR 条件 POST /es_db/_doc/_search { "query":{ "query_string":{ "query":"admin OR 长沙", "fields":["name","address"] } } }
范围查询:
注: json 请求中字符串部分字段的含义:
range : 范围关键字
gte : 大于等于
lte : 小于等于
gt : 大于
lt : 小于
now : 当前时间
POST /es_db/_doc/_search { "query" : { "range" : { "age" : { "gte":25, "lte":28 } } } }
# SQL: select * from user where age between 25 and 28
# 分页、输出字段、排序综合查询 POST /es_db/_doc/_search { "query" : { "range" : { "age" : { "gte":25, "lte":28 } } }, "from": 0, "size": 2, "_source": ["name", "age", "book"], "sort": {"age":"desc"} }
2.6、 Filter 过滤方式查询, 不回计算相关性分值,也不会对结果排序,查询结果可以被缓存。
POST /es_db/_doc/_search { "query" : { "bool" : { "filter" : { "term":{ "age":25 } } } } }
总结:
1、 match
3、match_phase
三、 文档映射
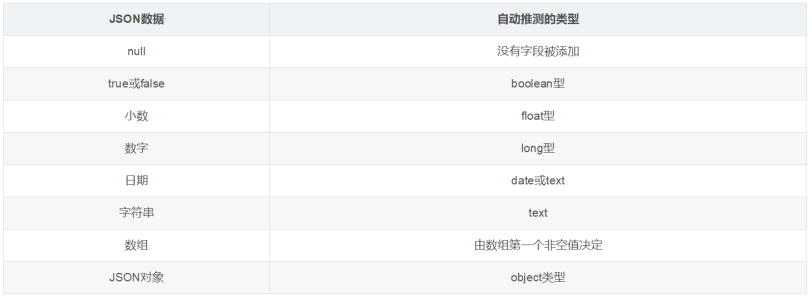
# 设置文档静态映射
# 其中 index 表示是否在倒排索引中包含该数据, store 表示是否在数据存储中包含该数据, 如果需要当作查询条件但不需要显示为结果,则可为false.
PUT /es_db { "mappings":{ "properties":{ "name":{"type":"keyword","index":true,"store":true}, "sex":{"type":"integer","index":true,"store":true}, "age":{"type":"integer","index":true,"store":true}, "book":{"type":"text","index":true,"store":true}, "address":{"type":"text","index":true,"store":true} } } }
# 获取文档映射
GET /es_db/_mapping
四、 核心类型
字符串: string , string 包含 text 和 keyword.
text:该类型被用来索引长文本,在创建索引前会将这些文本进行分词,转化为词的组合,建立索引;允许es来检索这些词,text类型不能用来排序和聚合
keyword: 该类型不能分词,可以被用来检索过滤、排序和聚合,keyword类型不可用text进行分词模糊检索
数值型: long, integer, short, byte, double, float
日期型: date
布尔型: boolean
五、 keyword 与 text 映射类型的区别
六、 创建静态映射时 指定 text 类型的 ik 分词器
PUT /es_db { "mappings":{ "properties":{ "name":{"type":"keyword","index":true,"store":true}, "sex":{"type":"integer","index":true,"store":true}, "age":{"type":"integer","index":true,"store":true}, "book":{"type":"text","index":true,"store":true,"analyzer":"ik_smart","search_analyzer":"ik_smart"}, "address":{"type":"text","index":true,"store":true} } } }
七、 对已存在的 mapping 映射进行修改
1、 重新建立一个新的索引
2、 把之前索引的数据导入新的索引里
3、删除原创建的索引
4、为新索引起个别名 - 原索引名
# 迁移数据 POST _reindex { "source": { "index": "db_index" }, "dest": { "index": "db_index_2" } } DELETE /db_index PUT /db_index_2/_alias/db_index
八、 Elasitcsearch 乐观并发控制
POST /es_db/_doc/1 { "id": 1, "name": "douger", "desc": "金仙之下无敌手", "create_date": "2022-07-04" } POST /es_db/_update/1 { "doc": { "name": "独角大王" } } GET /es_db/_doc/1 ---------------------结果---------------------------------- { "_index" : "es_db", "_id" : "1", "_version" : 2, "_seq_no" : 1, "_primary_term" : 1, "found" : true, "_source" : { "id" : 1, "name" : "独角大王", "desc" : "金仙之下无敌手", "create_date" : "2022-07-04" } } ------------------------------------------------------- POST /es_db/_update/1/?if_seq_no=1&if_primary_term=1 { "doc": { "name": "徐小凤传奇" } } GET /es_db/_doc/1 ---------------------结果---------------------------------- { "_index" : "es_db", "_id" : "1", "_version" : 3, "_seq_no" : 2, "_primary_term" : 1, "found" : true, "_source" : { "id" : 1, "name" : "徐小凤传奇", "desc" : "金仙之下无敌手", "create_date" : "2022-07-04" } } ------------------------------------------------------- # 更新报错,应为 _seq_no 已经改变了 POST /es_db/_update/1/?if_seq_no=1&if_primary_term=1 { "doc": { "name": "轩辕大陆" } }
_primary_term: 主要是用来恢复数据时处理当多个文档的_seq_no一样时的冲突,比如当一个shard宕机了,raplica需要用到最新的数据,就会根据_primary_term和_seq_no这两个值来拿到最新的document

 浙公网安备 33010602011771号
浙公网安备 33010602011771号