Hadoop综合大作业
1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)进行词频统计。
到网上下载经典长篇英文小说just a gril,保存到gril.txt。
启动hadoop集群
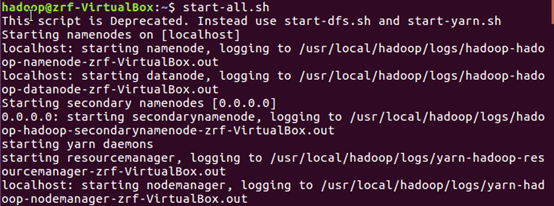
将wc文件夹的gril.txt上传文件至hdfs的word文件夹

启动hive

创建原始文档表
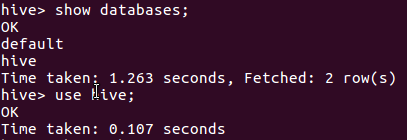

导入文件内容并查看

用HQL进行词频统计,结果放在表gril_count里
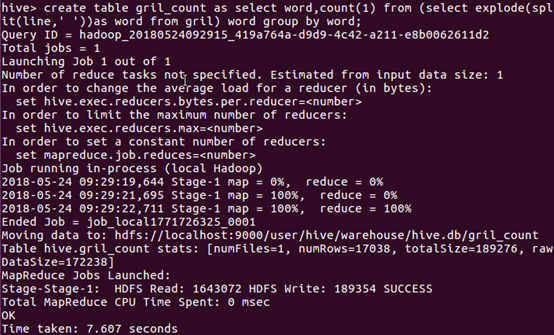
查看统计结果

2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
对虎扑NBA体育湖人新闻网进行爬取数据分析,并根据新闻做了词频统计,产生的csv如下
将csv通过WinSCP放入虚拟机wc文件夹下,并上传到dfs,并启动hive

创建表hu并将csv数据导入到表中


查看前20条数据

分析结果:湖人队在进入重建之后,以沃顿教练为主体,库兹马、英格拉姆等年轻球员为重点培养对象。
