

Python 读取dpf表格的内容
主要是读取一些api接口的文档数据。
下面介绍一下几种情况
1、表格的起始位置并非在每页的首行或者最后一行
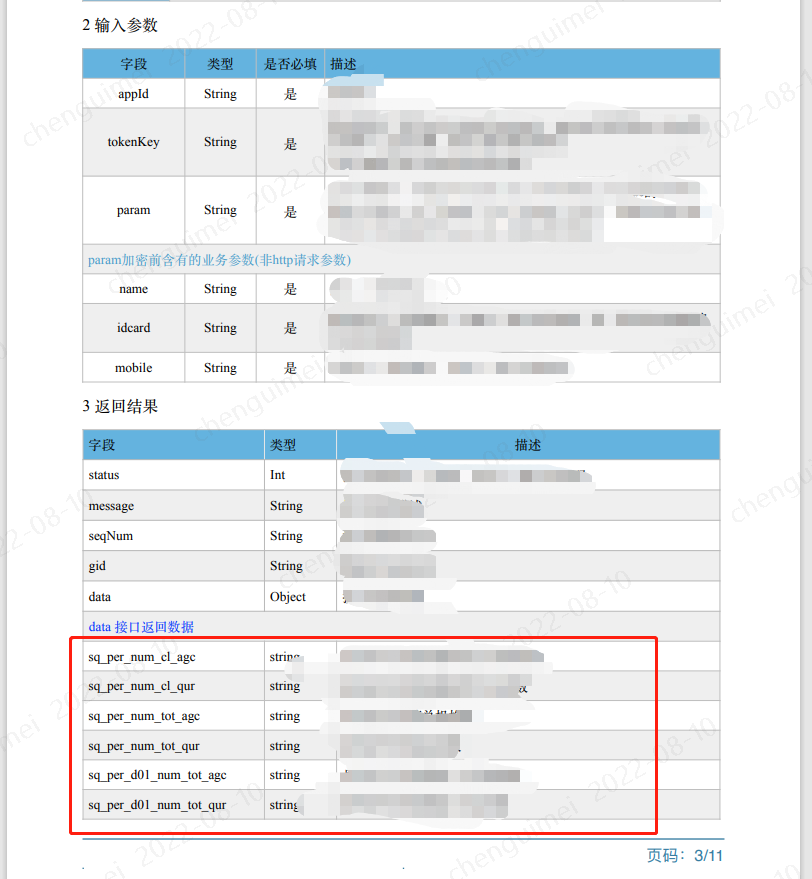
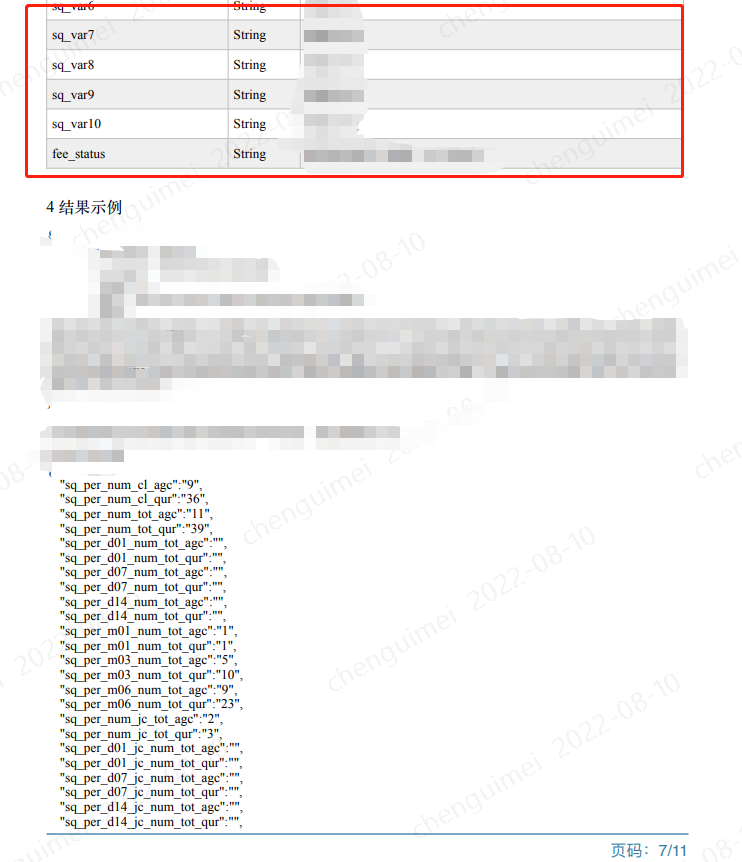
我们只需要红框中的数据
import pdfplumber import pandas as pd import numpy as np #%% 申请司南 # 创建仅有表头的 dataframe 数组 pdf_df = pd.DataFrame(columns=['字段', '类型', '描述']) # 获取 pdf 文件对象 pdf_mt = pdfplumber.open("xxx.pdf") # 因为我需要获取的资产负债表在 51-53页 但是索引从0开始 所以切片取 50-52即可 for i in range(2,7): print(i) if i==2: pdf_pg =[pdf_mt.pages[i].extract_tables()[-1][7:]] elif i==7: pdf_pg = [pdf_mt.pages[i].extract_tables()[0]] else: pdf_pg = pdf_mt.pages[i].extract_tables() pdf_df = pdf_df.append(pd.DataFrame(np.array(pdf_pg[0]),columns=['字段', '类型', '描述'])) pdf_df.to_excel('xxxx.xlsx')
我的代码是在Spyder上面跑的,看着有些字段显示有点问题,但是导到Excel是没有问题的

2、表格中存在合并单元格的
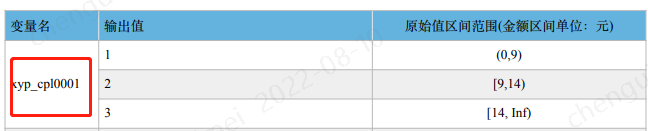
导入时数据变成这样
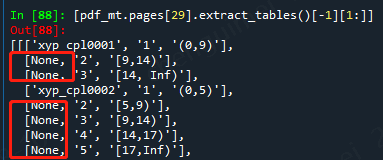
下面这样处理
pdf_df = pd.DataFrame(columns=['变量名', '输出值', '原始值区间范围(金额区间单位:元)']) # 获取 pdf 文件对象 pdf_mt = pdfplumber.open("xxx.pdf") # 因为我需要获取的资产负债表在 51-53页 但是索引从0开始 所以切片取 50-52即可 l=[] for i in range(29,60): print(i) if i==29: pdf_pg =[pdf_mt.pages[i].extract_tables()[-1][1:]] else: pdf_pg = pdf_mt.pages[i].extract_tables() for i in pdf_pg[0]: if i[0]!=None: l.append(i[0]) elif i[0]==None: i[0] = l[-1] pdf_df = pdf_df.append(pd.DataFrame(np.array(pdf_pg[0]),columns=['变量名', '输出值', '原始值区间范围(金额区间单位:元)'])) pdf_df.to_excel('xxx.xlsx')

就这样了。。。。。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号