
决策树信息熵(entropy),基尼系数(gini)
总是很容易忘记一些专业术语的公式,可以先理解再去记住
1.信息熵(entropy)
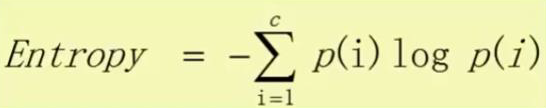
反正就是先计算每一类别的占比,然后再乘法,最后再将每一类加起来
def entropy(sr): """计算信息熵,以一个明细的观测点序列为输入 \n 参数: ---------- sr: series, 一列明细数据,非统计好的各类别占比 \n 返回值: ---------- entr: float, 变量的熵""" p = sr.distribution() e = p.binPct * np.log(p.binPct) return -e.sum()
其中distribution()的功能就是计算一个series各类的占比
def distribution(self, sort='index'): """计算单个变量的分布, 返回的数据框有两列:cnt(个数)、binPct(占比) \n 参数: ---------- sort: str, 'index' 表示按变量值的顺序排序,其他任意值表示变量值的个数占比排序""" a = self.value_counts() b = a / a.sum() df = pd.DataFrame({'cnt': a, 'binPct': b}) if sort == 'index': df = df.sort_index() return df.reindex(columns=['cnt', 'binPct'])
2.基尼系数(GINI)

具体公式如上,也是要先计算每一类别的分布
def gini_impurity(sr): """计算基尼不纯度, 以一列明细观测为输入。 \n 参数: ---------- sr: series, 一列明细数据 \n 返回值: ---------- impurity: float, 变量的基尼不纯度""" p = sr.distribution() impurity = 1 - (p.binPct * p.binPct).sum() return impurity
3.信息增益
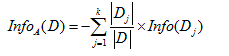
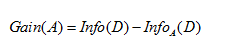
反正首先计算lable列的信息熵,然后再根据特征a的取值去分组,然后再计算组内label的信息熵,最后那原始的信息熵-sum(每组信息熵*组内占比)
def gain_entropy(sr, by): """计算随机变量的条件熵、gain. \n 参数: ---------- sr: series, 一列明细数据,非统计好的各类别占比 \n by: series, 与 sr 等长,条件明细数据。将按 by 取不同的值分组,计算各组内 sr 的熵,再加权求和 \n 返回值: ---------- gain_entr: float, 变量的熵增益""" entr = entropy(sr) d = by.distribution().binPct cond_entr = pd.Series(index=d.index) for i in d.index: ei = entropy(sr[by == i]) cond_entr[i] = ei cond_entr = (cond_entr * d).sum() return entr - cond_entr
第一个参数是label列,第二个参数是特征列


 浙公网安备 33010602011771号
浙公网安备 33010602011771号