

df 根据某列去拆分或者合并
一、拆分
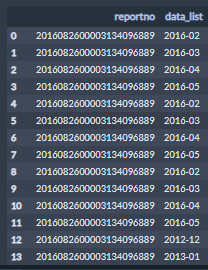
如果是拆分,那么那一列的值应该是list类型,比如:

我们需要根据data_list列去拆分,至于我怎么只挑了一个ID列和待分裂列,那是方便操作,剩余的我们可以使用merge,我就不赘述了
newvalues=np.dstack((np.repeat(t.reportno.values,list(map(len,t.data_list.values))),np.concatenate(t.data_list.values))) pd.DataFrame(data=newvalues[0],columns=['reportno','data_list'])
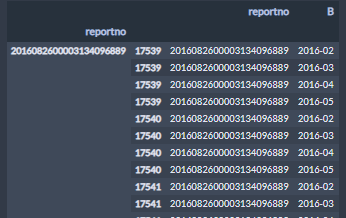
也可以这样操作,使用groupby,后面的自己处理索引的事情
t[['reportno','data_list']].groupby('reportno').apply(lambda x:pd.DataFrame({'reportno':x.reportno.repeat(x.data_list.str.len()),'B':np.concatenate(x.data_list.values)}))
二、合并
合并其实主要使用的np.concatenate,也是使用上面的例子
#t.groupby('reportno').apply(lambda x:len(set(np.concatenate(x.data_list.values)))) t.groupby('reportno').apply(lambda x:np.concatenate(x.data_list.values)) #np.concatenate里面的值是其他类型也是可以合并的,并不一定要求是list

2021-04-16补充
yixin_tmp3 = yixin_tmp2.groupby('状态匹配ID').apply(lambda x:("-".join(i for i in x['状态'])))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号