
df.drop_duplicates()返回删除重复行(或者列)的DataFrame
drop_duplicates()
可以删除重复的行,返回的是删除重复行后的df
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False, ignore_index=False)
参数
- subset:column label or sequence of labels, optional,需要删除的列,默认是全部的列
- keep:{‘first’, ‘last’, False}, default ‘first’,确定要保留的重复项(如果有),first和last分别是第一次和最后一次,false则是删除所有的重复项
- inplace:bool, default False,是否覆盖原来的df
- ignore_index:bool, default False
返回
如果inplace=Ture,则返回删除重复项的df
官网例子
df = pd.DataFrame({ 'brand': ['Yum Yum', 'Yum Yum', 'Indomie', 'Indomie', 'Indomie'], 'style': ['cup', 'cup', 'cup', 'pack', 'pack'], 'rating': [4, 4, 3.5, 15, 5] }) df ''' brand style rating 0 Yum Yum cup 4.0 1 Yum Yum cup 4.0 2 Indomie cup 3.5 3 Indomie pack 15.0 4 Indomie pack 5.0 '''
默认情况下,它将基于所有列删除重复的行
df.drop_duplicates() ''' brand style rating 0 Yum Yum cup 4.0 2 Indomie cup 3.5 3 Indomie pack 15.0 4 Indomie pack 5.0 '''
要删除特定列上的重复项,请使用subset
df.drop_duplicates(subset=['brand']) ''' brand style rating 0 Yum Yum cup 4.0 2 Indomie cup 3.5 '''
要删除重复项并保持最后一次出现,请使用keep
df.drop_duplicates(subset=['brand', 'style'], keep='last') ''' brand style rating 1 Yum Yum cup 4.0 2 Indomie cup 3.5 4 Indomie pack 5.0 '''
===============20210430补充删除重复列============================
原来数据
import pandas as pd df1 = pd.DataFrame({'name':['张三','李四','王五','张三'],'age':[18,19,20,18]}) df2 = pd.DataFrame({'name':['张三','李四','王五','张三'],'id':[300,260,280,300]}) df3 = pd.concat([df1,df2],axis=1) #concat无how
输出df1,df2,df3
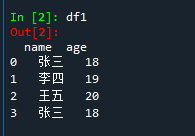
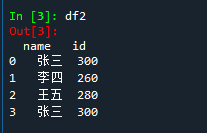
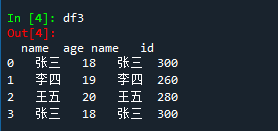
删除重复行
df3.drop_duplicates()
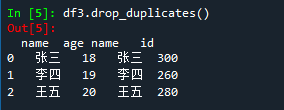
删除重复列
df3.T.drop_duplicates().T
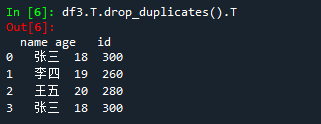
总结:其实还是使用df.drop_duplicates(),只不过是转置后再去重再转置

 浙公网安备 33010602011771号
浙公网安备 33010602011771号