

GBDT参数理解
GBDT 适用范围
GBDT 可以适用于回归问题(线性和非线性)其实多用于回归;
GBDT 也可用于二分类问题(设定阈值,大于为正,否则为负)和多分类问题
RF与GBDT之间的区别与联系
1)相同点:
- 都是由多棵树组成
- 最终的结果都由多棵树共同决定。
2)不同点:
- 组成随机森林的树可以分类树也可以是回归树,而GBDT只由回归树组成
- 组成随机森林的树可以并行生成(Bagging);GBDT 只能串行生成(Boosting);这两种模型都用到了Bootstrap的思想。
- 随机森林的结果是多数表决表决的,而GBDT则是多棵树加权累加之和
- 随机森林对异常值不敏感,而GBDT对异常值比较敏感
- 随机森林是减少模型的方差,而GBDT是减少模型的偏差
- 随机森林不需要进行特征归一化。而GBDT则需要进行特征归一化
- 随机森林对训练集一视同仁权值一样,GBDT是基于权值的弱分类器的集成
gbdt参数详解
class sklearn.ensemble.GradientBoostingClassifier(*, loss='deviance', learning_rate=0.1, n_estimators=100, subsample=1.0,
criterion='friedman_mse', min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_depth=3,
min_impurity_decrease=0.0, min_impurity_split=None, init=None, random_state=None, max_features=None,
verbose=0, max_leaf_nodes=None, warm_start=False, presort='deprecated', validation_fraction=0.1,
n_iter_no_change=None, tol=0.0001, ccp_alpha=0.0)
参数:
(1)n_estimators: 也就是弱学习器的最大迭代次数,或者说最大的弱学习器的个数。一般来说n_estimators太小,容易欠拟合,n_estimators太大,又容易过拟合,一般选择一个适中的数值。默认是100。在实际调参的过程中,我们常常将n_estimators和下面介绍的参数learning_rate一起考虑
(2)learning_rate, float,默认= 0.1,学习率缩小了每棵树的贡献learning_rate。在learning_rate和n_estimators之间需要权衡
(3)subsample: 即我们在原理篇的正则化章节讲到的子采样,取值为(0,1]。注意这里的子采样和随机森林不一样,随机森林使用的是放回抽样,而这里是不放回抽样。如果取值为1,则全部样本都使用,等于没有使用子采样。如果取值小于1,则只有一部分样本会去做GBDT的决策树拟合。选择小于1的比例可以减少方差,即防止过拟合,但是会增加样本拟合的偏差,因此取值不能太低。推荐在[0.5, 0.8]之间,默认是1.0,即不使用子采样
(4)loss: 即我们GBDT算法中的损失函数。分类模型和回归模型的损失函数是不一样的。
对于分类模型,有对数似然损失函数"deviance"和指数损失函数"exponential"两者输入选择。默认是对数似然损失函数"deviance"。在原理篇中对这些分类损失函数有详细的介绍。一般来说,推荐使用默认的"deviance"。它对二元分离和多元分类各自都有比较好的优化。而指数损失函数等于把我们带到了Adaboost算法。
对于回归模型,有均方差"ls", 绝对损失"lad", Huber损失"huber"和分位数损失“quantile”。默认是均方差"ls"。一般来说,如果数据的噪音点不多,用默认的均方差"ls"比较好。如果是噪音点较多,则推荐用抗噪音的损失函数"huber"。而如果我们需要对训练集进行分段预测的时候,则采用“quantile”
(5)alpha:这个参数只有GradientBoostingRegressor有,当我们使用Huber损失"huber"和分位数损失“quantile”时,需要指定分位数的值。默认是0.9,如果噪音点较多,可以适当降低这个分位数的值
(6)min_samples_split, int或float,默认为2,拆分内部节点所需的最少样本数:如果为int,则认为min_samples_split是最小值。如果为float,min_samples_split则为分数, 是每个拆分的最小样本数。ceil(min_samples_split * n_samples)
(7)min_samples_leaf, int或float,默认值= 1,在叶节点处所需的最小样本数。仅在任何深度的分裂点在min_samples_leaf左分支和右分支中的每个分支上至少留下训练样本时,才考虑。这可能具有平滑模型的效果,尤其是在回归中。如果为int,则认为min_samples_leaf是最小值。如果为float,min_samples_leaf则为分数, 是每个节点的最小样本数。ceil(min_samples_leaf * n_samples)
(8)min_weight_fraction_leaf, float,默认值= 0.0,在所有叶节点处(所有输入样本)的权重总和中的最小加权分数。如果未提供sample_weight,则样本的权重相等。
(9)max_depth, int,默认= 3,各个回归估计量的最大深度。最大深度限制了树中节点的数量。调整此参数以获得最佳性能;最佳值取决于输入变量的相互作用。也就是那个树有多少层(一般越多越容易过拟合)
(10)min_impurity_decrease, 浮动,默认值= 0.0,如果节点分裂会导致杂质的减少大于或等于该值,则该节点将被分裂
(11)min_impurity_split ,float,默认=无提前停止树木生长的阈值。如果节点的杂质高于阈值,则该节点将分裂,否则为叶
(12)init:计量或“零”,默认=无,一个估计器对象,用于计算初始预测。 init必须提供fit和predict_proba。如果为“零”,则初始原始预测设置为零。默认情况下,使用 DummyEstimator预测类优先级
(13)max_features:节点分裂时参与判断的最大特征数
- int:个数
- float:占所有特征的百分比
- auto:所有特征数的开方
- sqrt:所有特征数的开方
- log2:所有特征数的log2值
- None:等于所有特征数
其他没啥好说的,有兴趣可以自己查看官网https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingClassifier.html
属性:
n_estimators_
feature_importances_
oob_improvement_
train_score_
loss_
init_
estimators_
classes_
n_features_
n_classes_
max_features_
# -*- coding: utf-8 -*- """ Created on Tue Aug 11 10:12:48 2020 """ from sklearn.ensemble import AdaBoostClassifier ,AdaBoostRegressor from sklearn.datasets import load_iris x_data=load_iris().data y_data=load_iris().target from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test = train_test_split(x_data,y_data,test_size=0.3,random_state=1,stratify=y_data) #单个决策树模型 from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score tree = DecisionTreeClassifier(criterion='gini',max_depth=4,random_state=1) tree.fit(X_train,y_train) y_train_pred = tree.predict(X_train) y_test_pred = tree.predict(X_test) tree_train = accuracy_score(y_train,y_train_pred) tree_test = accuracy_score(y_test,y_test_pred) print('Decision tree train/test accuracies %.3f/%.3f' % (tree_train,tree_test)) #Decision tree train/test accuracies 0.971/0.978 #gbdt实现 import matplotlib.pyplot as plt from sklearn.ensemble import GradientBoostingClassifier depth_ = [1, 2, 3, 4, 5, 6, 7, 8] scores1 = [] scores2 = [] for depth in depth_: gbdt = GradientBoostingClassifier(n_estimators=100, max_depth=depth, random_state=1) gbdt.fit(X_train,y_train) a1=accuracy_score(y_train,gbdt.predict(X_train)) a2=accuracy_score(y_test,gbdt.predict(X_test)) scores1.append(a1) scores2.append(a2) plt.plot(depth_,scores1) plt.plot(depth_,scores2)
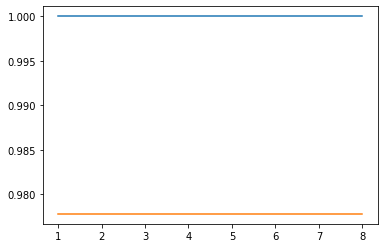
梯度提升以进行回归
class sklearn.ensemble.GradientBoostingRegressor(loss='ls', learning_rate=0.1, n_estimators=100, subsample=1.0,
min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_depth=3, init=None, random_state=None,
max_features=None, alpha=0.9, verbose=0, max_leaf_nodes=None, warm_start=False)
参数
loss:{'ls','lad','huber','quantile'},可选(默认='ls')
损失函数有待优化。“ ls”是指最小二乘回归。“ lad”(最小绝对偏差)是仅基于输入变量的顺序信息的高度鲁棒的损失函数。“ huber”是两者的结合。“分位数”允许分位数回归(使用α来指定分位数)。
learning_rate:float,可选(默认= 0.1)
学习率通过learning_rate缩小每棵树的贡献。在learning_rate和n_estimators之间需要权衡。
n_estimators:int(默认= 100)
要执行的提升阶段数。梯度提升对于过度拟合具有相当强的鲁棒性,因此大量提升通常会带来更好的性能。
max_depth:整数,可选(默认= 3)
各个回归估计量的最大深度。最大深度限制了树中节点的数量。调整此参数以获得最佳性能;最佳值取决于输入变量的相互作用。如果max_leaf_nodes不为None则忽略。
min_samples_split:整数,可选(默认= 2)
拆分内部节点所需的最小样本数。
min_samples_leaf:整数,可选(默认= 1)
在叶节点处所需的最小样本数。
min_weight_fraction_leaf:浮点型,可选(默认= 0.)
输入样本的最小加权分数必须位于叶节点。
subsample:浮点型,可选(默认= 1.0)
用于拟合各个基础学习者的样本比例。如果小于1.0,则将导致随机梯度增强。subsample与参数n_estimators交互。选择小于1.0的子样本会导致方差减少和偏差增加。
max_features:int,float,string或None,可选(默认=无)
- 寻找最佳分割时要考虑的功能数量:
- 如果为int,则在每个拆分中考虑max_features功能。
- 如果为float,则max_features是一个百分比,并 在每次拆分时考虑int(max_features * n_features)个特征。
- 如果为“ auto”,则max_features = n_features。。
- 如果为“ sqrt”,则max_features = sqrt(n_features)。
- 如果为“ log2”,则max_features = log2(n_features)。
- 如果为None,则max_features = n_features。
选择max_features <n_features会导致方差减少和偏差增加。
注意:直到找到至少一个有效的节点样本分区,分割的搜索才会停止,即使它需要有效检查多个max_features功能也是如此。
max_leaf_nodes:int或None,可选(默认=无)
以最佳优先方式种植具有max_leaf_nodes的树。最佳节点定义为杂质的相对减少。如果为None,则叶节点数不受限制。
alpha:浮点(默认= 0.9)
Huber损失函数和分位数损失函数的alpha分位数。仅当loss ='huber'或loss ='quantile'时。
init:BaseEstimator,无,可选(默认=无)
一个估计器对象,用于计算初始预测。初始化必须提供适应和预测。如果为None,则使用loss.init_estimator。
verbose:int,默认:0
启用详细输出。如果为1,则偶尔打印一次进度和性能(树越多,频率越低)。如果大于1,则为每棵树打印进度和性能。
warm_start:布尔值,默认值:False
设置为True时,请重用上一个调用的解决方案以适合并在集合中添加更多的估计量,否则,只需擦除以前的解决方案即可。
属性:
feature_importances_:数组,形状= [n_features]
功能的重要性(越高,功能越重要)。特征重要性
oob_improvement_:数组,形状= [n_estimators]
相对于先前的迭代,袋装样本的损失(=偏差)的改善。 oob_improvement_ [0]是初始估算器在第一阶段损失方面的改进。
train_score_:数组,形状= [n_estimators]
第i个得分train_score_ [i]是袋内样本在第i次迭代时模型的偏差(=损失)。如果子样本 == 1,则这是训练数据的偏差。
loss_:LossFunction
具体的LossFunction对象。
`init`:BaseEstimator
提供初始预测的估算器。通过init参数或loss.init_estimator进行设置。
estimators_:DecisionTreeRegressor的ndarray,形状= [n_estimators,1]
拟合子估计量的集合。
方法:
| Decision_function(X) | 计算X的决策函数。 |
| fit(X, y[, sample_weight, monitor]) | 拟合梯度提升模型。 |
| fit_transform(X [,y]) | 适合数据,然后对其进行转换。 |
| get_params([deep]) | 获取此估计量的参数。 |
| predict(X) | 预测X的回归目标。 |
| score(X, y[, sample_weight]) | 返回预测的确定系数R ^ 2。 |
| set_params(**params) | 设置此估算器的参数。 |
| staged_decision_function(X) | 为每次迭代计算X的决策函数。 |
| staged_predict(X) | 预测X的每个阶段的回归目标。 |
| transform(X[, threshold]) | 将X还原为其最重要的功能。 |
具体操作可以参考官网https://scikit-learn.org/0.16/modules/generated/sklearn.ensemble.GradientBoostingRegressor.html
使用波斯顿房价的数据
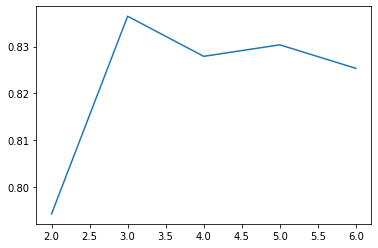
# 从 sklearn.datasets 导入波士顿房价数据读取器。 from sklearn.datasets import load_boston # 从读取房价数据存储在变量 boston 中。 boston = load_boston() # 从sklearn.cross_validation 导入数据分割器。 from sklearn.model_selection import train_test_split X = boston.data y = boston.target # 随机采样 25% 的数据构建测试样本,其余作为训练样本。 X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=33, test_size=0.25) # 从 sklearn.preprocessing 导入数据标准化模块。 from sklearn.preprocessing import StandardScaler # 分别初始化对特征和目标值的标准化器。 ss_X = StandardScaler() ss_y = StandardScaler() # 分别对训练和测试数据的特征以及目标值进行标准化处理。 X_train = ss_X.fit_transform(X_train) X_test = ss_X.transform(X_test) y_train = ss_y.fit_transform(y_train.reshape(-1,1)) y_test = ss_y.transform(y_test.reshape(-1,1)) from sklearn.ensemble import GradientBoostingRegressor max_depth=list(range(2,7)) l=[] for i in max_depth: clf= GradientBoostingRegressor(learning_rate=0.1, n_estimators=100,max_depth=i,random_state=0) clf=clf.fit(X_train,y_train) score=clf.score(X_test, y_test) l.append(score) import matplotlib.pyplot as plt plt.plot(max_depth,l) #可以看出max_depth=3是最好的, clf= GradientBoostingRegressor(learning_rate=0.1, n_estimators=100,max_depth=3,random_state=0) clf=clf.fit(X_train,y_train) #查看属性 clf.feature_importances_ plt.plot(clf.feature_importances_) clf.estimators_ clf.score(X_test, y_test)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号