

Kaggle经典数据分析项目:泰坦尼克号生存预测!
数据分析练手项目:
- 开源项目《动手学数据分析》:https://github.com/datawhalechina/hands-on-data-analysis
- DCIC 2020算法分析赛:DCIC 是国内少有的开放政府真实数据的经典赛事,对能力实践,学术研究等都提供了很好的机会。https://mp.weixin.qq.com/s/-fzQIlZRig0hqSm7GeI_Bw
数据集包含train.csv和test.csv两个文件,在 Datawhale 公众号回复 数据集,可获取打包链接,也可以直接在kaggle官网上下载
1. 数据概述与可视化
1.1 数据概述
# -*- coding: utf-8 -*- """ Created on Tue Aug 11 10:12:48 2020 @author: Admin """ import pandas as pd import seaborn as sns #展示一下两种路径的写法 train_data = pd.read_csv("D:\\Users\\Downloads\\《泰坦尼克号数据分析项目数据》\\train.csv", index_col=0) test_data = pd.read_csv("D:/Users/Downloads/《泰坦尼克号数据分析项目数据》/test.csv", index_col=0) train_data.head() train_data.describe() train_data.info()
通过describe()函数我们可以简单地看出哪些是数值型数据哪些是字符型数据,
对于字符型数据我们当然要转换成数值型数据来处理,比如可以转换成0-1编码的数值型,
但需要注意的是,对于一些数值型数据却未必就不需要进一步的处理了,比如Pclass特征,
从名字我们就可以看出这是标识仓位等级的特征,取值范围为[1, 2, 3],
这个特征我们不应该简单地当作一个数值型数据放进分类模型中直接跑,应该把它转变为one-hot编码,
标识乘客不同的仓位,这一步我们将在数据预处理步骤完成。
1.2 数据可视化
数据可视化时尽量不做数据修改,保留原数据,等到后面数据预处理再做,不能将二者混着做
值得注意的是sns.barplot画的是均值,而非个数,对于特征和y值都是类别的时候,特别好使
1.2.1 性别与生存率
首先我们应该还记得电影里感人的“女士优先”策略:
sns.barplot(x="Sex", y="Survived", data=train_data)
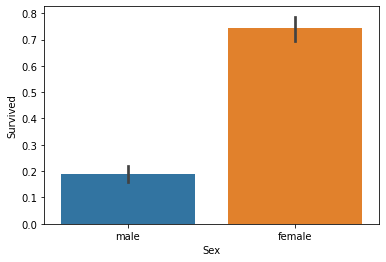
这里我们可以看出女性的生存率远大于男性,这也很符合电影的情节
注意
上面说了数据可视化的时候不要乱动原数据,但是我们可以先copy一个数据,这样就不会动到原数据了
train=train_data.copy()
1.2.2 仓位等级(社会等级)与生存率
我们还可以猜测不同仓位的乘客应有不同的获救率:
#draw a bar plot of survival by Pclass sns.barplot(x="Pclass", y="Survived", data=train) #print percentage of people by Pclass that survived print("Percentage of Pclass = 1 who survived:", train["Survived"][train["Pclass"] == 1].value_counts(normalize = True)[1]*100) print("Percentage of Pclass = 2 who survived:", train["Survived"][train["Pclass"] == 2].value_counts(normalize = True)[1]*100) print("Percentage of Pclass = 3 who survived:", train["Survived"][train["Pclass"] == 3].value_counts(normalize = True)[1]*100)

数据结果还是很现实的,贵的仓位自然有更高的生存率 ,不然我花这冤枉钱干嘛,生死面前不是人人平等。
1.2.3 家属数与生存率
#draw a bar plot for SibSp vs. survival sns.barplot(x="SibSp", y="Survived", data=train) #I won't be printing individual percent values for all of these. print("Percentage of SibSp = 0 who survived:", train["Survived"][train["SibSp"] == 0].value_counts(normalize = True)[1]*100) print("Percentage of SibSp = 1 who survived:", train["Survived"][train["SibSp"] == 1].value_counts(normalize = True)[1]*100) print("Percentage of SibSp = 2 who survived:", train["Survived"][train["SibSp"] == 2].value_counts(normalize = True)[1]*100)

#draw a bar plot for Parch vs. survival sns.barplot(x="Parch", y="Survived", data=train) plt.show()
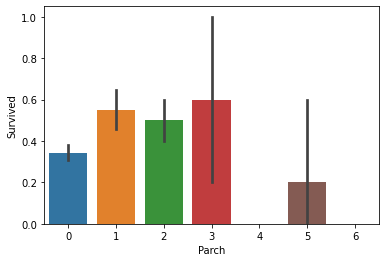
看起来独自旅游的人们生存率更低,想想眼眶竟湿润了
1.2.4 年龄与生存率
test=test_data.copy() #sort the ages into logical categories train["Age"] = train["Age"].fillna(-0.5) test["Age"] = test["Age"].fillna(-0.5) bins = [-1, 0, 5, 12, 18, 24, 35, 60, np.inf] labels = ['Unknown', 'Baby', 'Child', 'Teenager', 'Student', 'Young Adult', 'Adult', 'Senior'] train['AgeGroup'] = pd.cut(train["Age"], bins, labels = labels) test['AgeGroup'] = pd.cut(test["Age"], bins, labels = labels) #draw a bar plot of Age vs. survival sns.barplot(x="AgeGroup", y="Survived", data=train) plt.show()
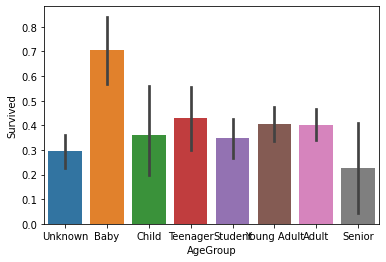
cut(),可以用这个方法对数据进行切分
1.2.5 仓位特征是否存在与生存率
train["Cabin"].notnull().astype('int')这样可以将缺失值和非缺失值转化为0-1,高
train["CabinBool"] = (train["Cabin"].notnull().astype('int')) test["CabinBool"] = (test["Cabin"].notnull().astype('int')) #calculate percentages of CabinBool vs. survived print("Percentage of CabinBool = 1 who survived:", train["Survived"][train["CabinBool"] == 1].value_counts(normalize = True)[1]*100) print("Percentage of CabinBool = 0 who survived:", train["Survived"][train["CabinBool"] == 0].value_counts(normalize = True)[1]*100) #draw a bar plot of CabinBool vs. survival sns.barplot(x="CabinBool", y="Survived", data=train) plt.show()

脑洞确实大,结果确实不赖~
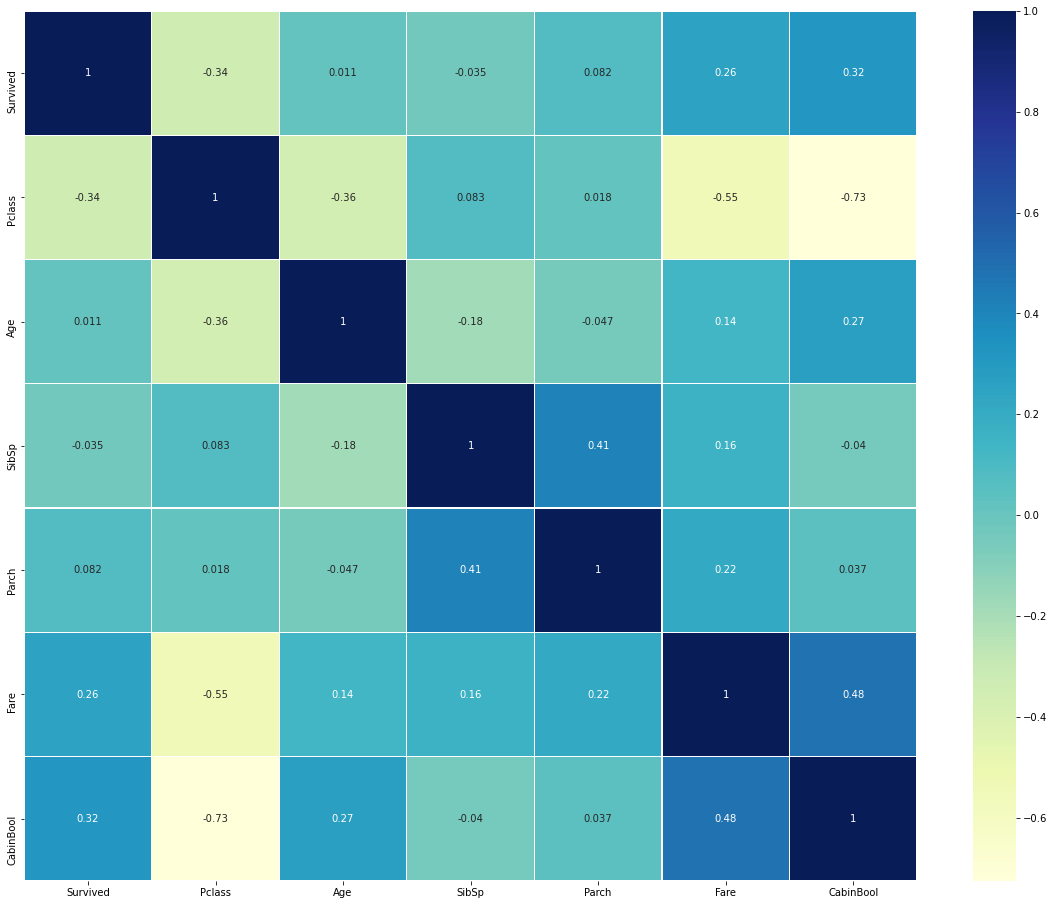
1.2.6 热力图
plt.figure(figsize=(20,16)) sns.heatmap(train.corr(),xticklabels=train.corr().columns, yticklabels=train.corr().columns, linewidths=0.2, cmap="YlGnBu",annot=True)
2. 数据预处理
2.1 拼接数据集
首先我们讲训练集中的Survived特征提取出来,这是我们需要预测的目标函数,这部分也是train_data和test_data的不同点,接着我们可以讲训练集和测试集的数据拼接起来一起进行数据预处理,当然在实际中我们是无从得知测试数据的,但在比赛中为了方便我们可以统一进行处理:
y_train = train_data.pop("Survived") data_all = pd.concat((train_data, test_data), axis=0)
2.2 处理Name特征,提取出Title
从左往右看我们首先可以看到Name这个特征是比较碍眼的,很多人可能直接把它去掉了,但仔细观察我们可以发现这一列特征里都含有名字的前缀,比如"Mr.",”Mrs.“,"Miss"等,只要学过小学一年级英语的都知道这个特征在一定程度上会代表阶级地位,婚配情况等,我们可以将这个特征做一个映射,实现方式如下:
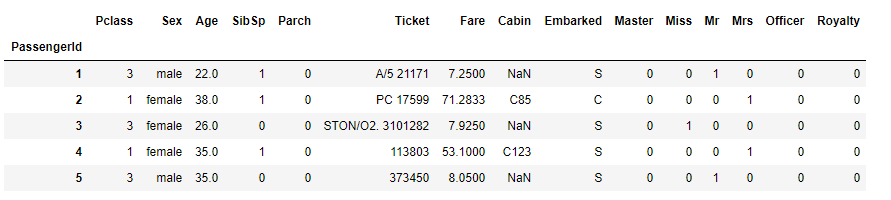
title = pd.DataFrame() title["Title"] = data_all["Name"].map(lambda name:name.split(",")[1].split(".")[0].strip()) # title.head() Title_Dictionary = { "Capt": "Officer", "Col": "Officer", "Major": "Officer", "Jonkheer": "Royalty", "Don": "Royalty", "Sir" : "Royalty", "Dr": "Officer", "Rev": "Officer", "the Countess":"Royalty", "Dona": "Royalty", "Mme": "Mrs", "Mlle": "Miss", "Ms": "Mrs", "Mr" : "Mr", "Mrs" : "Mrs", "Miss" : "Miss", "Master" : "Master", "Lady" : "Royalty" } title[ 'Title' ] = title.Title.map(Title_Dictionary) title = pd.get_dummies(title.Title) # title.head() data_all = pd.concat((data_all, title), axis=1) data_all.pop("Name") data_all.head()
上面这段是什么意思呢?我们可以将种类众多的头衔特征先进行归类,比如"Don","Sir",”Jonkheer"这几个头衔出现的次数极低,大约每个出现次数只有不到十个,因此我们可以将意思相近的归为一类便于模型运行。然后我们用get_dummies将这些特征转为one-hot向量,得到的结果如下:
2.3 提取其他特征
这个 Ticket特征比较麻烦懒得搞了,先把它删掉吧,然后Cabin特征应该是很有用的,你想想嘛我们在船的不同位置到安全通道的距离当然是会随着Cabin位置的不同而不同的,我们简单提取A、B、C、D这几个仓位来作为特征,而不考虑C85、C123中的数字(表示某个仓中的位置),当然由于有些船在A、B、C、D等仓位可能都有安全通道,我们可能提取后面的数字会更适合,为了方便我们先不做此讨论:
data_all["Cabin"].fillna("NA", inplace=True) data_all["Cabin"] = data_all["Cabin"].map(lambda s:s[0]) data_all.pop("Ticket")
前面也说了Pclass更适合作为One-hot型特征出现,我们先将之转换为字符型特征再进行归类,这里我们顺手把几个靠谱的类别标签做One-hot特征:
data_all["Pclass"] = data_all["Pclass"].astype(str) feature_dummies = pd.get_dummies(data_all[["Pclass", "Sex", "Embarked", "Cabin"]]) # feature_dummies.head() data_all.drop(["Pclass", "Sex", "Embarked", "Cabin"], inplace=True, axis=1) data_all = pd.concat((data_all, feature_dummies), axis=1) data_all.head()
于是我们将特征集合由原来的11列扩充到了27列,噢糟糕我们前面忘了做缺失值填充,不要紧我们现在做也不晚:
mean_cols = data_all.mean()
data_all = data_all.fillna(mean_cols)
这里是使用了平均值对Age和Embarked两个特征进行填充,由于Age刚好是数值型特征,这种填充方式是合理的,且Embarked只有两个缺失值,因此随便填充啦~不碍事的。
2.4 将训练集测试集重新分开
在模型搭建之前不要忘了之前我们拼在一起的训练集和测试集噢,还记得最开始读取数据的时候加入的index_col嘛,这里刚好派上用场啦:
train_df = data_all.loc[train_data.index] test_df = data_all.loc[test_data.index] print(train_df.shape, test_df.shape)
打印结果是(891, 27) (418, 27),符合原训练集测试集的大小,我们的粗略数据预处理就到此为止了,下面进行模型搭建~
注意,上面的并没有怎么构造特征,比如说年龄和票价没有分箱,还有家属数量等特征也没有处理,也导致后面的建模效果特别差
3. 模型训练
3.1 Random Forest
首先导入sklearn的包
from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import cross_val_score import sklearn
然后设置不同的树最大深度进行参数调优:
%matplotlib inline depth_ = [1, 2, 3, 4, 5, 6, 7, 8] scores = [] for depth in depth_: clf = RandomForestClassifier(n_estimators=100, max_depth=depth, random_state=0) test_score = cross_val_score(clf, train_df, y_train, cv=10, scoring="precision") scores.append(np.mean(test_score)) plt.plot(depth_, scores)
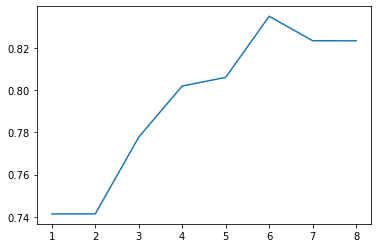
得到了这样一张图,这张图大致反映了模型中树的最大深度以6为最佳,此时可以达到0.84左右的验证准确率,我们当然可以继续调整其他参数获得更优的结果,但接下来我们先继续讨论其他模型
3.2 Gradient Boosting Classifier
from sklearn.ensemble import GradientBoostingClassifier depth_ = [1, 2, 3, 4, 5, 6, 7, 8] scores = [] for depth in depth_: clf = GradientBoostingClassifier(n_estimators=100, max_depth=depth, random_state=0) test_score = cross_val_score(clf, train_df, y_train, cv=10, scoring="precision") scores.append(np.mean(test_score)) plt.plot(depth_, scores)
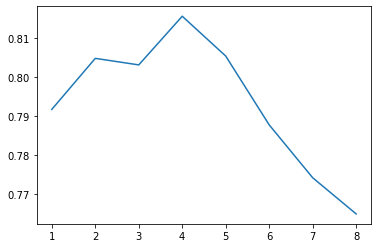
成功率最高似乎接近0.82
3.3 Bagging
Bagging把很多小分类器放在一起,每个train随机的一部分数据,然后把它们的最终结果综合起来(多数投票制)
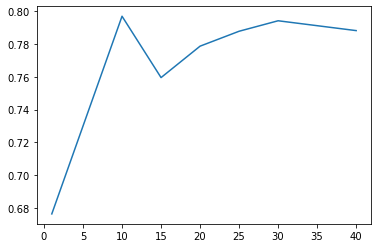
from sklearn.ensemble import BaggingClassifier params = [1, 10, 15, 20, 25, 30, 40] test_scores = [] for param in params: clf = BaggingClassifier(n_estimators=param) test_score = cross_val_score(clf, train_df, y_train, cv=10, scoring="precision") test_scores.append(np.mean(test_score)) plt.plot(params, test_scores)
结果又不稳定又不好:
3.4 RidgeClassifier
from sklearn.linear_model import RidgeClassifier alphas = np.logspace(-3, 2, 50) test_scores = [] for alpha in alphas: clf = RidgeClassifier(alpha) test_score = cross_val_score(clf, train_df, y_train, cv=10, scoring="precision") test_scores.append(np.mean(test_score)) plt.plot(alphas, test_scores)
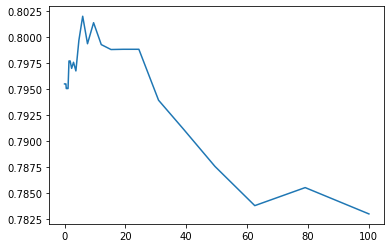
3.5 RidgeClassifier + Bagging
ridge = RidgeClassifier(alpha=5) params = [1, 10, 15, 20, 25, 30, 40] test_scores = [] for param in params: clf = BaggingClassifier(n_estimators=param, base_estimator=ridge) test_score = cross_val_score(clf, train_df, y_train, cv=10, scoring="precision") test_scores.append(np.mean(test_score)) plt.plot(params, test_scores)
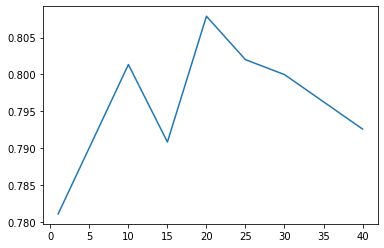
结果比使用默认模型的Bagging策略稍好一些
3.6 XGBClassifier
from xgboost import XGBClassifier params = [1, 2, 3, 4, 5, 6] test_scores = [] for param in params: clf = XGBClassifier(max_depth=param) test_score = cross_val_score(clf, train_df, y_train, cv=10, scoring="precision") test_scores.append(np.mean(test_score)) plt.plot(params, test_scores)
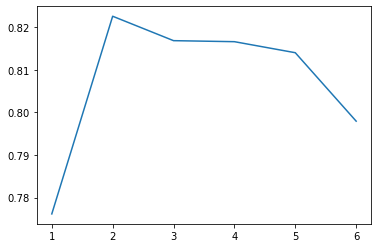
4. 模型优化(调参)
后续我们可以通过对这些表现比较好的模型再进行第二层的学习获得更好的分数。
首先我们将之前获得的几个比较好的结果一一定好参数放上来(这里只随便调了一个参数):
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier, BaggingClassifier, AdaBoostClassifier from xgboost import XGBClassifier from sklearn.model_selection import cross_val_score from sklearn.linear_model import RidgeClassifier import sklearn classifier_num = 5 clf = [0 for i in range(classifier_num)] clf[0] = RandomForestClassifier(n_estimators=100, max_depth=6, random_state=0) clf[1] = GradientBoostingClassifier(n_estimators=100, max_depth=4, random_state=0) clf[2] = RidgeClassifier(5) clf[3] = BaggingClassifier(n_estimators=15, base_estimator=clf[2]) clf[4] = XGBClassifier(max_depth=2) from sklearn.model_selection import train_test_split X_train, X_test, Y_train, Y_test = train_test_split(train_df, y_train, random_state=0) predictFrame = pd.DataFrame() for model in clf: model.fit(X_train, Y_train) predictFrame[str(model)[:13]] = model.predict(X_test) predictFrame.head()
| RandomForestC | GradientBoost | RidgeClassifi | BaggingClassi | XGBClassifier | |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 |
| 3 | 1 | 1 | 1 | 1 | 1 |
| 4 | 1 | 1 | 1 | 1 | 1 |
看到上面的结果了吗,其实现在也可以做投票表决,感觉这样准确度会更高一些
名字随意啦反正只要不重复就好了~然后将这个结果放入下一个分类器中学习,我没有试其他的就直接放进了随机森林分类器:
%matplotlib inline depth_ = [1, 2, 3, 4, 5, 6, 7, 8] scores = [] for depth in depth_: clf_ = RandomForestClassifier(n_estimators=100, max_depth=depth, random_state=0) test_score = cross_val_score(clf_, predictFrame, Y_test, cv=10, scoring="precision") scores.append(np.mean(test_score)) plt.plot(depth_, scores)
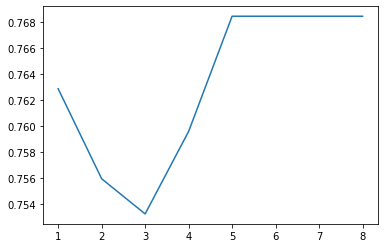
好吧就定个参数为2,然后就将整体跑个结果试试:
finalFrame = pd.DataFrame() XFrame = pd.DataFrame() for model in clf: model.fit(train_df, y_train) XFrame[str(model)[:13]] = model.predict(train_df) finalFrame[str(model)[:13]] = model.predict(test_df) final_clf = RandomForestClassifier(n_estimators=100, max_depth=2, random_state=0) final_clf.fit(XFrame, y_train) result = final_clf.predict(finalFrame)
将result和passengerId一起拼接成一个Dataframe就直接输出看结果吧,比之前没有融合直接用随机森林结果稍好一些,但我们只是用了几个简单的机器学习算法搞来搞去也没有认真调参,实际上还是有很多优化空间的,读者可以自行优化
全部代码(已折叠)


# -*- coding: utf-8 -*- """ Created on Tue Aug 11 10:12:48 2020 @author: Admin """ import pandas as pd import seaborn as sns #展示一下两种路径的写法 train_data = pd.read_csv("D:\\Users\\Downloads\\《泰坦尼克号数据分析项目数据》\\train.csv", index_col=0) test_data = pd.read_csv("D:/Users/Downloads/《泰坦尼克号数据分析项目数据》/test.csv", index_col=0) train_data.head() train_data.describe() train_data.info() ''' 通过describe()函数我们可以简单地看出哪些是数值型数据哪些是字符型数据, 对于字符型数据我们当然要转换成数值型数据来处理,比如可以转换成0-1编码的数值型, 但需要注意的是,对于一些数值型数据却未必就不需要进一步的处理了,比如Pclass特征, 从名字我们就可以看出这是标识仓位等级的特征,取值范围为[1, 2, 3], 这个特征我们不应该简单地当作一个数值型数据放进分类模型中直接跑,应该把它转变为one-hot编码, 标识乘客不同的仓位,这一步我们将在数据预处理步骤完成。 ''' train_data.isnull().sum().sort_values(ascending=False).head(4) ''' Cabin 687 Age 177 Embarked 2 Fare 0 dtype: int64 ''' #性别与生存率 sns.barplot(x='Sex',y='Survived',data=train_data) #这里我们可以看出女性的生存率远大于男性,这也很符合电影的情节 #仓位等级(社会等级)与生存率 sns.barplot(x='Pclass',y='Survived',data=train_data) #其中normalize=True是以占比表述,如果没有这个,则以数量表示 train_data['Survived'][train_data['Pclass']==1].value_counts(normalize=True)[1]*100 pd.crosstab(train_data['Survived'],train_data['Pclass']) a=pd.crosstab(train_data['Pclass'],train_data['Survived']) a['生存率']=a[1]/(a[0]+a[1]) a['生存率'].plot() groupby_way=train_data['Survived'].groupby(train_data['Pclass']) groupby_df=pd.merge(groupby_way.count(),groupby_way.sum(),left_index=True,right_index=True) groupby_df['rate']=groupby_df.iloc[:,1]/groupby_df.iloc[:,0] groupby_df['rate'].plot() #数据结果还是很现实的,贵的仓位自然有更高的生存率, 生死面前不是人人平等。 #家属数与生存率 sns.barplot(x='SibSp',y='Survived',data=train_data) sns.barplot(x="Parch", y="Survived", data=train_data) #年龄与生存率 train_data['Age']=train_data['Age'].fillna(-0.5) test_data['Age']=test_data['Age'].fillna(-0.5) bins = [-1, 0, 5, 12, 18, 24, 35, 60, np.inf] labels = ['Unknown', 'Baby', 'Child', 'Teenager', 'Student', 'Young Adult', 'Adult', 'Senior'] train_data['AgeGroup'] = pd.cut(train_data["Age"], bins, labels = labels) test_data['AgeGroup'] = pd.cut(test_data["Age"], bins, labels = labels) sns.barplot(x="AgeGroup", y="Survived", data=train_data) #仓位特征是否存在与生存率,座位号也太没有意思了 #我认为这里的想法是,有记录的船舱号的人属于较高的社会经济阶层,因此更有可能存活下来。 train_data["Cabin"].value_counts() #test["CabinBool"] = (test["Cabin"].notnull().astype('int')) pd.crosstab(train_data["Cabin"].isnull(),train_data['Survived']).plot.bar() train_data["Cabin_isnull"]=train_data["Cabin"].isnull() sns.barplot(x="Cabin_isnull", y="Survived", data=train_data) #可见上面的猜测是正确的 #数据预处理 train_data = pd.read_csv("D:\\Users\\Downloads\\《泰坦尼克号数据分析项目数据》\\train.csv", index_col=0) test_data = pd.read_csv("D:/Users/Downloads/《泰坦尼克号数据分析项目数据》/test.csv", index_col=0) train=train_data.copy() y_train = train["Survived"] train.pop("Survived") #训练集和测试集放在一起 data_all=pd.concat([train,test_data],axis=0) #处理name特征 ''' 从左往右看我们首先可以看到Name这个特征是比较碍眼的,很多人可能直接把它去掉了, 但仔细观察我们可以发现这一列特征里都含有名字的前缀,比如"Mr.",”Mrs.“,"Miss"等, 这个特征在一定程度上会代表阶级地位,婚配情况等, 我们可以将这个特征做一个映射,实现方式如下: ''' #strip()去掉首尾空格 title=pd.DataFrame() title['Title']=data_all['Name'].map(lambda Name:Name.split(',')[1].split('.')[0].strip()) title['Title'].value_counts() #"Don","Sir",”Jonkheer"这几个头衔出现的次数极低,大约每个出现次数只有不到十个,因此我们可以将意思相近的归为一类便于模型运行 Title_Dictionary = { "Capt": "Officer", "Col": "Officer", "Major": "Officer", "Jonkheer": "Royalty", "Don": "Royalty", "Sir" : "Royalty", "Dr": "Officer", "Rev": "Officer", "the Countess":"Royalty", "Dona": "Royalty", "Mme": "Mrs", "Mlle": "Miss", "Ms": "Mrs", "Mr" : "Mr", "Mrs" : "Mrs", "Miss" : "Miss", "Master" : "Master", "Lady" : "Royalty" } title['Title']=title.Title.map(Title_Dictionary) #字典映射 title=pd.get_dummies(title.Title) #独热编码 data_all=pd.concat([data_all,title],axis=1) #axis,0是在下面拼接,1是在右边拼接 data_all.pop('Name') data_all.head(3) #提取其他特征 ''' 这个 Ticket特征比较麻烦懒得搞了,先把它删掉吧,然后Cabin特征应该是很有用的 ,你想想嘛我们在船的不同位置到安全通道的距离当然是会随着Cabin位置的不同而不同的, 我们简单提取A、B、C、D这几个仓位来作为特征,而不考虑C85、C123中的数字(表示某个仓中的位置), 当然由于有些船在A、B、C、D等仓位可能都有安全通道,我们可能提取后面的数字会更适合,为了方便我们先不做此讨论: ''' data_all.pop('Ticket') #首先构建一个有无作为号码的数据,上面也说了这个特征效果还是不错的 data_all['Cabin_isnull']=data_all["Cabin"].isnull().astype('int') dummy_Cabin_isnull = pd.get_dummies(data_all['Cabin_isnull'], prefix='Cabin_isnull') data_all["Cabin"].fillna("NA", inplace=True) data_all["Cabin"] = data_all["Cabin"].map(lambda s:s[0]) ''' 前面也说了Pclass更适合作为One-hot型特征出现, 我们先将之转换为字符型特征再进行归类,这里我们顺手把几个靠谱的类别标签做One-hot特征: ''' data_all.info() data_all["Pclass"] = data_all["Pclass"].astype(str) feature_dummies = pd.get_dummies(data_all[["Pclass", "Sex", "Embarked", "Cabin"]]) # feature_dummies.head() data_all.drop(["Pclass", "Sex", "Embarked", "Cabin",'Cabin_isnull'], inplace=True, axis=1) data_all = pd.concat((data_all, feature_dummies,dummy_Cabin_isnull), axis=1) data_all.head() ''' 于是我们将特征集合由原来的11列扩充到了29列,噢糟糕我们前面忘了做缺失值填充,不要紧我们现在做也不晚: ''' data_all.isnull().sum().sort_values() #年龄可以用均值填充,不过我想用随机深林填充 #随机深林 data_copy=data_all.copy() #有缺失值的不能放进去,因此删除Fare data_copy.columns data_copy.pop('Fare') #要把年龄放在最后一列 data_age=pd.DataFrame() data_age['age']=data_copy['Age'] data_copy.pop('Age') data_copy['Age']=data_age['age'] #区分有空值和没有空值的行 known = data_copy[data_copy['Age'].notnull()].as_matrix() unknown = data_copy[data_copy['Age'].isnull()].as_matrix() from sklearn.ensemble import RandomForestRegressor X = known[:,:-1] y = known[:,-1] rfr = RandomForestRegressor(random_state=0,n_estimators=200,max_depth=3,n_jobs=-1) rfr.fit(X,y) predicted = rfr.predict(unknown[:,:-1]).round(0) data_copy.loc[(data_copy['Age'].isnull()), 'Age'] = predicted data_copy['Age'].describe() #用均值填充 mean_cols = data_all.mean() data_all = data_all.fillna(mean_cols) data_all['Age'].describe() #将训练集和测试集重新分开 train_df = data_all.loc[train_data.index] test_df = data_all.loc[test_data.index] print(train_df.shape, test_df.shape) #模型训练 ''' Random Forest 随机深林 ''' from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import cross_val_score import sklearn #然后设置不同的树最大深度进行参数调优: %matplotlib inline depth_=[i for i in range(1,9)] scores=[] for depth in depth_: clf=RandomForestClassifier(n_estimators=100, max_depth=depth, random_state=0) test_score = cross_val_score(clf, train_df, y_train, cv=10, scoring="precision") scores.append(np.mean(test_score)) plt.plot(depth_,scores) ''' 这张图大致反映了模型中树的最大深度以7为最佳,此时可以达到0.84左右的验证准确率, 我们当然可以继续调整其他参数获得更优的结果,但接下来我们先继续讨论其他模型 https://www.cnblogs.com/baby-lily/p/10657185.html ''' ''' Gradient Boosting Classifier 梯度提升决策树分类 ''' from sklearn.ensemble import GradientBoostingClassifier depth_ = [1, 2, 3, 4, 5, 6, 7, 8] scores = [] for depth in depth_: clf = GradientBoostingClassifier(n_estimators=100, max_depth=depth, random_state=0) test_score = cross_val_score(clf, train_df, y_train, cv=10, scoring="precision") scores.append(np.mean(test_score)) plt.plot(depth_, scores) ''' Bagging Bagging把很多小分类器放在一起,每个train随机的一部分数据,然后把它们的最终结果综合起来(多数投票制) ''' from sklearn.ensemble import BaggingClassifier params = [1, 10, 15, 20, 25, 30, 40] test_scores = [] for param in params: clf = BaggingClassifier(n_estimators=param) test_score = cross_val_score(clf, train_df, y_train, cv=10, scoring="precision") test_scores.append(np.mean(test_score)) plt.plot(params, test_scores) #结果又不稳定又不好: ''' RidgeClassifier 岭回归 ''' from sklearn.linear_model import RidgeClassifier alphas = np.logspace(-3, 2, 50) test_scores = [] for alpha in alphas: clf = RidgeClassifier(alpha) test_score = cross_val_score(clf, train_df, y_train, cv=10, scoring="precision") test_scores.append(np.mean(test_score)) plt.plot(alphas, test_scores) ''' RidgeClassifier + Bagging 结果比使用默认模型的Bagging策略稍好一些。 ''' ridge = RidgeClassifier(alpha=5) params = [1, 10, 15, 20, 25, 30, 40] test_scores = [] for param in params: clf = BaggingClassifier(n_estimators=param, base_estimator=ridge) test_score = cross_val_score(clf, train_df, y_train, cv=10, scoring="precision") test_scores.append(np.mean(test_score)) plt.plot(params, test_scores) ''' XGBClassifier ''' from xgboost import XGBClassifier params = [1, 2, 3, 4, 5, 6] test_scores = [] for param in params: clf = XGBClassifier(max_depth=param) test_score = cross_val_score(clf, train_df, y_train, cv=10, scoring="precision") test_scores.append(np.mean(test_score)) plt.plot(params, test_scores) ''' 神经网络 首先我们基于Keras搭建了一个简单的神经网络架构: 没有安装这个就算了 可以看到效果和随机森林的最佳效果差不多。 import tensorflow as tf import keras from keras.models import Sequential from keras.layers import * tf.keras.optimizers.Adam( learning_rate=0.003, beta_1=0.9, beta_2=0.999, epsilon=1e-07, amsgrad=False, name='Adam', ) model = Sequential() model.add(Dense(32, input_dim=train_df.shape[1],kernel_initializer = 'uniform', activation='relu')) model.add(Dense(32, kernel_initializer = 'uniform', activation = 'relu')) model.add(Dropout(0.4)) model.add(Dense(32,kernel_initializer = 'uniform', activation = 'relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) history = model.fit(np.array(train_df), np.array(y_train), epochs=20, batch_size=50, validation_split = 0.2) model.summary() scores = model.evaluate(train_df, y_train, batch_size=32) print(scores) ''' ''' 模型优化(调参) 后续我们可以通过对这些表现比较好的模型再进行第二层的学习获得更好的分数。 首先我们将之前获得的几个比较好的结果一一定好参数放上来(这里只随便调了一个参数): ''' from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier, BaggingClassifier, AdaBoostClassifier from xgboost import XGBClassifier from sklearn.model_selection import cross_val_score from sklearn.linear_model import RidgeClassifier import sklearn classifier_num = 5 clf = [0 for i in range(classifier_num)] clf[0] = RandomForestClassifier(n_estimators=100, max_depth=7, random_state=0) clf[1] = GradientBoostingClassifier(n_estimators=100, max_depth=3, random_state=0) clf[2] = RidgeClassifier(4.71487) clf[3] = BaggingClassifier(n_estimators=40, base_estimator=clf[2]) clf[4] = XGBClassifier(max_depth=3) from sklearn.model_selection import train_test_split X_train, X_test, Y_train, Y_test = train_test_split(train_df, y_train, random_state=0) ''' 名字随意啦反正只要不重复就好了: ''' predictFrame = pd.DataFrame() scores = {} for model in clf: model.fit(X_train, Y_train) predictFrame[str(model)[:13]] = model.predict(X_test) test_score = cross_val_score(model, predictFrame, Y_test, cv=10, scoring="precision") scores[str(model)[:13]]=np.mean(test_score) predictFrame.head() scores ''' 然后将这个结果放入下一个分类器中学习 ''' %matplotlib inline depth_ = [1, 2, 3, 4, 5, 6, 7, 8] scores = [] for depth in depth_: clf_ = RandomForestClassifier(n_estimators=100, max_depth=depth, random_state=0) test_score = cross_val_score(clf_, predictFrame, Y_test, cv=10, scoring="precision") scores.append(np.mean(test_score)) plt.plot(depth_, scores) ''' 定个参数为2, ''' finalFrame = pd.DataFrame() XFrame = pd.DataFrame() for model in clf: model.fit(train_df, y_train) XFrame[str(model)[:13]] = model.predict(train_df) finalFrame[str(model)[:13]] = model.predict(test_df) final_clf = RandomForestClassifier(n_estimators=100, max_depth=2, random_state=0) final_clf.fit(XFrame, y_train) result = final_clf.predict(finalFrame) ''' 将result和passengerId一起拼接成一个Dataframe就直接输出看结果吧, 比之前没有融合直接用随机森林结果稍好一些,但我们只是用了几个简单的机器学习算法搞来搞去也没有认真调参, 实际上还是有很多优化空间的,读者可以自行优化 '''

 浙公网安备 33010602011771号
浙公网安备 33010602011771号