
信用卡评分模型(二)python
前面已经有了一篇信用卡的文章,拓展不同方法
前面的处理方式都一样,主要不同的是从缺失值开始的:
#导入模块 import pandas as pd import numpy as np from scipy import stats import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline plt.rc("font",family="SimHei",size="12") #解决中文无法显示的问题 #导入数据 train=pd.read_csv('F:\\python\\Give-me-some-credit-master\\data\\cs-training.csv') #简单查看数据 train.info() #头三行和尾三行数据查看 b=train.head(3).append(train.tail(3)) #shape train.shape #(150000, 11) #将各英文字段转为中文字段名方便理解 states={'Unnamed: 0':'id', 'SeriousDlqin2yrs':'好坏客户', 'RevolvingUtilizationOfUnsecuredLines':'可用额度比值', 'age':'年龄', 'NumberOfTime30-59DaysPastDueNotWorse':'逾期30-59天笔数', 'DebtRatio':'负债率', 'MonthlyIncome':'月收入', 'NumberOfOpenCreditLinesAndLoans':'信贷数量', 'NumberOfTimes90DaysLate':'逾期90天笔数', 'NumberRealEstateLoansOrLines':'固定资产贷款量', 'NumberOfTime60-89DaysPastDueNotWorse':'逾期60-89天笔数', 'NumberOfDependents':'家属数量'} train.rename(columns=states,inplace=True) #设置索引 train=train.set_index('id',drop=True) #描述性统计 train.describe() #查看每列缺失情况 train.isnull().sum() #查看缺失占比情况 train.isnull().sum()/len(train) #缺失值可视化 missing=train.isnull().sum() missing[missing>0].sort_values().plot.bar() #将大于0的拿出来并排序
首先复制一份新的数据
###3#3#下面的是缺失值的处理 #保留原数据 train_2=train.copy()
3.1缺失值处理
这种情况在现实问题中非常普遍,这会导致一些不能处理缺失值的分析方法无法应用,因此,在信用风险评级模型开发的第一步我们就要进行缺失值处理。缺失值处理的方法,包括如下几种。
(1) 直接删除含有缺失值的样本。
(2) 根据样本之间的相似性填补缺失值。
(3) 根据变量之间的相关关系填补缺失值。
变量MonthlyIncome缺失率比较大,所以我们根据变量之间的相关关系填补缺失值,我们采用随机森林法:
(2) 根据样本之间的相似性填补缺失值。
(3) 根据变量之间的相关关系填补缺失值。
变量MonthlyIncome缺失率比较大,所以我们根据变量之间的相关关系填补缺失值,我们采用随机森林法:
NumberOfDependents变量缺失值比较少,直接删除,对总体模型不会造成太大影响。对缺失值处理完之后,删除重复项。
import pandas as pd import matplotlib.pyplot as plt #导入图像库 from sklearn.ensemble import RandomForestRegressor # 用随机森林对缺失值预测填充函数 def set_missing(df): # 把已有的数值型特征取出来,由于家庭数量有缺失,就不包括这个,顺便排列一下顺序,将月收入放在第一位 process_df = df.ix[:,[5,0,1,2,3,4,6,7,8,9]] # 分成已知该特征和未知该特征两部分,分为有缺失值的行和没有缺失的行 known = process_df[process_df['月收入'].notnull()].as_matrix() unknown = process_df[process_df['月收入'].isnull()].as_matrix() # X为特征属性值 X = known[:, 1:] # y为结果标签值 y = known[:, 0] # fit到RandomForestRegressor之中 rfr = RandomForestRegressor(random_state=0, n_estimators=200,max_depth=3,n_jobs=-1) rfr.fit(X,y) # 用得到的模型进行未知特征值预测 predicted = rfr.predict(unknown[:, 1:]).round(0) #.round(0)是不保留小数点 print(predicted) # 用得到的预测结果填补原缺失数据 df.loc[(process_df['月收入'].isnull()), '月收入'] = predicted #loc的布尔索引,有空值的行对应的月收入的值用与预测值填补 return df if __name__ == '__main__': #载入数据 #train_2 = pd.read_csv('cs-training.csv') #数据集确实和分布情况 train_2.describe().to_csv('train_2Describe.csv')#了解数据集的分布情况 train_2=set_missing(train_2)#用随机森林填补比较多的缺失值 train_2=train_2.dropna()#删除比较少的缺失值 train_2 = train_2.drop_duplicates()#删除重复项 train_2.to_csv('Missingtrain_2.csv',index=False) train_2.describe().to_csv('Missingtrain_2Describe.csv') ''' #异常值处理 #年龄等于0的异常值进行剔除 train_2=train_2[train_2['年龄']>0] # 箱形图 train_2379=train_2[['逾期30-59天笔数','逾期90天笔数','逾期60-89天笔数']] train_2379.boxplot() train_2 = train_2[train_2['逾期30-59天笔数'] < 90] #因为剔除了这个,其余的两个也会同事剔除 train_2379 = train_2[['逾期30-59天笔数', '逾期90天笔数', '逾期60-89天笔数']] train_2379.boxplot() plt.show() train_2.to_csv('Pretreatmenttrain_2.csv') '''
3.2异常值处理
缺失值处理完毕后,我们还需要进行异常值处理。异常值是指明显偏离大多数抽样数据的数值,找出样本总体中的异常值,通常采用离群值检测的方法。
数据集中好客户为0,违约客户为1,考虑到正常的理解,能正常履约并支付利息的客户为1,所以我们将其取反。
年龄<0的去掉,那几个逾期天数笔数的超离群点(>90)的也去掉
最后异常值的全部代码如下
#数据切分和异常值处理和在一起 import pandas as pd import matplotlib.pyplot as plt #导入图像库 from sklearn.model_selection import train_test_split #异常值处理,通过箱型图去将1.5倍1/4到3/4长度的值去掉 def outlier_processing(df,col): s=df[col] oneQuoter=s.quantile(0.25) threeQuote=s.quantile(0.75) irq=threeQuote-oneQuoter min=oneQuoter-1.5*irq max=threeQuote+1.5*irq df=df[df[col]<=max] df=df[df[col]>=min] return df if __name__ == '__main__': data = pd.read_csv('Missingtrain_2.csv') # 年龄等于0的异常值进行剔除 data = data[data['年龄'] > 0] data = data[data['逾期30-59天笔数'] < 90]#剔除异常值 data['好坏客户']=1-data['好坏客户'] Y = data['好坏客户'] X = data.ix[:, 1:] X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=0) # print(Y_train) train = pd.concat([Y_train, X_train], axis=1) test = pd.concat([Y_test, X_test], axis=1) clasTest = test.groupby('好坏客户')['好坏客户'].count() train.to_csv('TrainData.csv',index=False) test.to_csv('TestData.csv',index=False) print(train.shape) print(test.shape)
四、探索性分析
在建立模型之前,我们一般会对现有的数据进行 探索性数据分析(Exploratory Data Analysis) 。 EDA是指对已有的数据(特别是调查或观察得来的原始数据)在尽量少的先验假定下进行探索。常用的探索性数据分析方法有:直方图、散点图和箱线图等
这个数据我在第一篇文章写得很清楚
五、变量选择
特征变量选择(排序)对于数据分析、机器学习从业者来说非常重要。好的特征选择能够提升模型的性能,更能帮助我们理解数据的特点、底层结构,这对进一步改善模型、算法都有着重要作用。至于Python的变量选择代码实现可以参考结合Scikit-learn介绍几种常用的特征选择方法。
在本文中,我们采用信用评分模型的变量选择方法,通过WOE分析方法,即是通过比较指标分箱和对应分箱的违约概率来确定指标是否符合经济意义。首先我们对变量进行离散化(分箱)处理。
在本文中,我们采用信用评分模型的变量选择方法,通过WOE分析方法,即是通过比较指标分箱和对应分箱的违约概率来确定指标是否符合经济意义。首先我们对变量进行离散化(分箱)处理。
5.1分箱处理
变量分箱(binning)是对连续变量离散化(discretization)的一种称呼。信用评分卡开发中一般有常用的等距分段、等深分段、最优分段。其中等距分段(Equval length intervals)是指分段的区间是一致的,比如年龄以十年作为一个分段;等深分段(Equal frequency intervals)是先确定分段数量,然后令每个分段中数据数量大致相等;最优分段(Optimal Binning)又叫监督离散化(supervised discretizaion),使用递归划分(Recursive Partitioning)将连续变量分为分段,背后是一种基于条件推断查找较佳分组的算法。
我们首先选择对连续变量进行最优分段,在连续变量的分布不满足最优分段的要求时,再考虑对连续变量进行等距分段。最优分箱的代码如下:
我们首先选择对连续变量进行最优分段,在连续变量的分布不满足最优分段的要求时,再考虑对连续变量进行等距分段。最优分箱的代码如下:
5.2woe
WoE分析, 是对指标分箱、计算各个档位的WoE值并观察WoE值随指标变化的趋势。其中WoE的数学定义是:
woe=ln(goodattribute/badattribute)
在进行分析时,我们需要对各指标从小到大排列,并计算出相应分档的WoE值。其中正向指标越大,WoE值越小;反向指标越大,WoE值越大。正向指标的WoE值负斜率越大,反响指标的正斜率越大,则说明指标区分能力好。WoE值趋近于直线,则意味指标判断能力较弱。若正向指标和WoE正相关趋势、反向指标同WoE出现负相关趋势,则说明此指标不符合经济意义,则应当予以去除。
woe函数实现在上一节的mono_bin()函数里面已经包含,这里不再重复。
woe=ln(goodattribute/badattribute)
在进行分析时,我们需要对各指标从小到大排列,并计算出相应分档的WoE值。其中正向指标越大,WoE值越小;反向指标越大,WoE值越大。正向指标的WoE值负斜率越大,反响指标的正斜率越大,则说明指标区分能力好。WoE值趋近于直线,则意味指标判断能力较弱。若正向指标和WoE正相关趋势、反向指标同WoE出现负相关趋势,则说明此指标不符合经济意义,则应当予以去除。
woe函数实现在上一节的mono_bin()函数里面已经包含,这里不再重复。
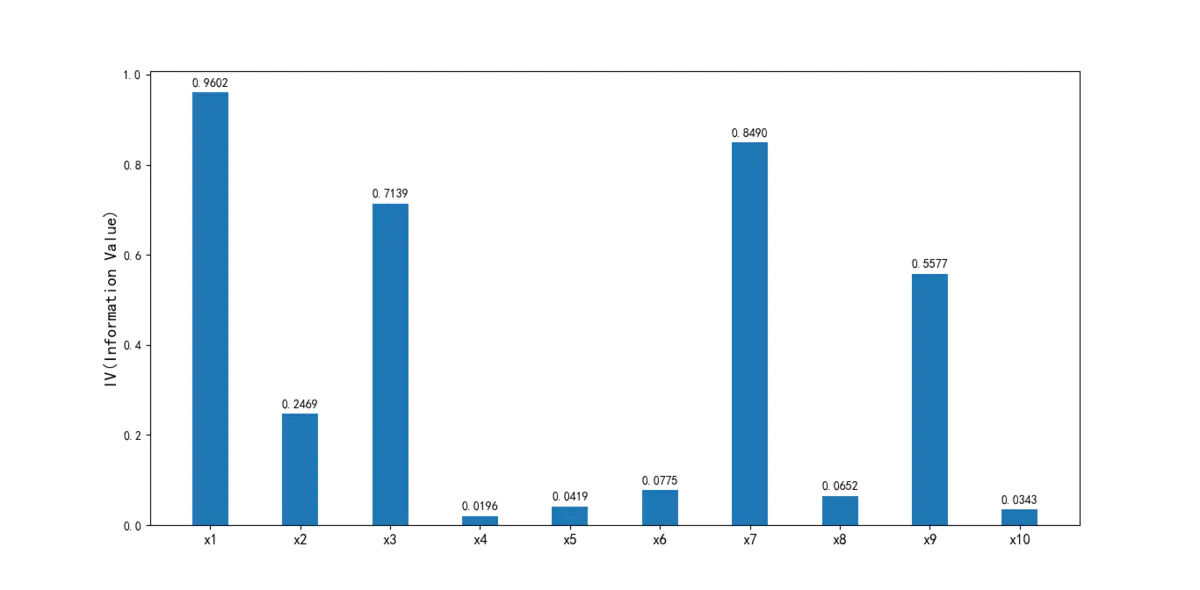
5.3相关性和iv值筛选
接下来,我们会用经过清洗后的数据看一下变量间的相关性。注意,这里的相关性分析只是初步的检查,进一步检查模型的VI(证据权重)作为变量筛选的依据。
相关性图我们通过Python里面的seaborn包,调用heatmap()绘图函数进行绘制,实现代码如下:
相关性图我们通过Python里面的seaborn包,调用heatmap()绘图函数进行绘制,实现代码如下:
IV指标是一般用来确定自变量的预测能力。 其公式为:
IV=sum((goodattribute-badattribute)*ln(goodattribute/badattribute))
通过IV值判断变量预测能力的标准是:
< 0.02: unpredictive
0.02 to 0.1: weak
0.1 to 0.3: medium
0.3 to 0.5: strong
> 0.5: suspicious
IV=sum((goodattribute-badattribute)*ln(goodattribute/badattribute))
通过IV值判断变量预测能力的标准是:
< 0.02: unpredictive
0.02 to 0.1: weak
0.1 to 0.3: medium
0.3 to 0.5: strong
> 0.5: suspicious
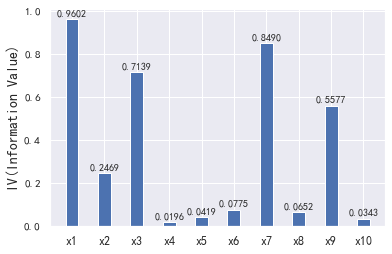
import pandas as pd import numpy as np from pandas import Series,DataFrame import scipy.stats.stats as stats import matplotlib.pyplot as plt import statsmodels.api as sm import math # 定义自动分箱函数,好用户是1 def mono_bin(Y, X, n = 20): r = 0 good=Y.sum() #Y是标签值,也就是好坏客户,计算好用户个数 bad=Y.count()-good #坏用户个数 while np.abs(r) < 1: #np.abs(r)是求觉得值,有点疑惑,相关系数<1就一直减少分箱个数,感觉相关系数一直都是小于1 d1 = pd.DataFrame({"X": X, "Y": Y, "Bucket": pd.qcut(X, n)}) #等深分段,并且将XY和X分段好的数据组合成一个df d2 = d1.groupby('Bucket', as_index = True) #根据分箱的去分组,且不要索引 r, p = stats.spearmanr(d2.mean().X, d2.mean().Y) #斯皮尔曼等级相关系数 n = n - 1 d3 = pd.DataFrame(d2.X.min(), columns = ['min']) #最小值 d3['min']=d2.min().X #X的最小值 d3['max'] = d2.max().X #X的最大值 d3['sum'] = d2.sum().Y #好用户个数 d3['total'] = d2.count().Y #全部用户个数 d3['rate'] = d2.mean().Y #好用户占比 d3['woe']=np.log((d3['rate']/(1-d3['rate']))/(good/bad)) #woe计算 d3['goodattribute']=d3['sum']/good #每个区间中好用户占比 d3['badattribute']=(d3['total']-d3['sum'])/bad #每个区间中坏用户占比 iv=((d3['goodattribute']-d3['badattribute'])*d3['woe']).sum() #iv值计算 d4 = (d3.sort_index(by = 'min')) print("=" * 60) print(d4) cut=[] cut.append(float('-inf')) #负无穷 for i in range(1,n+1): qua=X.quantile(i/(n+1)) cut.append(round(qua,4)) cut.append(float('inf')) woe=list(d4['woe'].round(3)) return d4,iv,cut,woe #自定义分箱函数 自定义分箱区间cat def self_bin(Y,X,cat): good=Y.sum() bad=Y.count()-good d1=pd.DataFrame({'X':X,'Y':Y,'Bucket':pd.cut(X,cat)}) d2=d1.groupby('Bucket', as_index = True) d3 = pd.DataFrame(d2.X.min(), columns=['min']) d3['min'] = d2.min().X d3['max'] = d2.max().X d3['sum'] = d2.sum().Y d3['total'] = d2.count().Y d3['rate'] = d2.mean().Y d3['woe'] = np.log((d3['rate'] / (1 - d3['rate'])) / (good / bad)) d3['goodattribute'] = d3['sum'] / good d3['badattribute'] = (d3['total'] - d3['sum']) / bad iv = ((d3['goodattribute'] - d3['badattribute']) * d3['woe']).sum() d4 = (d3.sort_index(by='min')) print("=" * 60) print(d4) woe = list(d4['woe'].round(3)) return d4, iv,woe #用woe代替 def replace_woe(series,cut,woe): list=[] i=0 while i<len(series): value=series[i] j=len(cut)-2 #减去收尾的正负无穷? 如果cut=6,j=4, m=len(cut)-2 while j>=0: if value>=cut[j]: #如果值大于正无穷前面的值到正无穷之间 j=-1 #j=3 else: j -=1 #否则j-1,m-1,相当于找到合适的区间 m -= 1 list.append(woe[m]) i += 1 return list #计算分数函数 def get_score(coe,woe,factor): scores=[] for w in woe: score=round(coe*w*factor,0) scores.append(score) return scores #根据变量计算分数 def compute_score(series,cut,score): list = [] i = 0 while i < len(series): value = series[i] j = len(cut) - 2 m = len(cut) - 2 while j >= 0: if value >= cut[j]: j = -1 else: j -= 1 m -= 1 list.append(score[m]) i += 1 return list if __name__ == '__main__': data = pd.read_csv('TrainData.csv') pinf = float('inf')#正无穷大 ninf = float('-inf')#负无穷大 dfx1, ivx1,cutx1,woex1=mono_bin(data['好坏客户'],data['可用额度比值'],n=10) dfx2, ivx2,cutx2,woex2=mono_bin(data['好坏客户'], data['年龄'], n=10) dfx4, ivx4,cutx4,woex4 =mono_bin(data['好坏客户'], data['负债率'], n=20) dfx5, ivx5,cutx5,woex5 =mono_bin(data['好坏客户'], data['月收入'], n=10) # 连续变量离散化 cutx3 = [ninf, 0, 1, 3, 5, pinf] cutx6 = [ninf, 1, 2, 3, 5, pinf] cutx7 = [ninf, 0, 1, 3, 5, pinf] cutx8 = [ninf, 0,1,2, 3, pinf] cutx9 = [ninf, 0, 1, 3, pinf] cutx10 = [ninf, 0, 1, 2, 3, 5, pinf] dfx3, ivx3,woex3 = self_bin(data['好坏客户'], data['逾期30-59天笔数'], cutx3) dfx6, ivx6 ,woex6= self_bin(data['好坏客户'], data['信贷数量'], cutx6) dfx7, ivx7,woex7 = self_bin(data['好坏客户'], data['逾期90天笔数'], cutx7) dfx8, ivx8,woex8 = self_bin(data['好坏客户'], data['固定资产贷款量'], cutx8) dfx9, ivx9,woex9 = self_bin(data['好坏客户'], data['逾期60-89天笔数'], cutx9) dfx10, ivx10,woex10 = self_bin(data['好坏客户'], data['家属数量'], cutx10) ivlist=[ivx1,ivx2,ivx3,ivx4,ivx5,ivx6,ivx7,ivx8,ivx9,ivx10] index=['x1','x2','x3','x4','x5','x6','x7','x8','x9','x10'] fig1 = plt.figure(1) ax1 = fig1.add_subplot(1, 1, 1) x = np.arange(len(index))+1 ax1.bar(x, ivlist, width=0.4) ax1.set_xticks(x) ax1.set_xticklabels(index, rotation=0, fontsize=12) ax1.set_ylabel('IV(Information Value)', fontsize=14) for a, b in zip(x, ivlist): plt.text(a, b + 0.01, '%.4f' % b, ha='center', va='bottom', fontsize=10) # 替换成woe data['可用额度比值'] = Series(replace_woe(data['可用额度比值'], cutx1, woex1)) data['年龄'] = Series(replace_woe(data['年龄'], cutx2, woex2)) data['逾期30-59天笔数'] = Series(replace_woe(data['逾期30-59天笔数'], cutx3, woex3)) data['负债率'] = Series(replace_woe(data['负债率'], cutx4, woex4)) data['月收入'] = Series(replace_woe(data['月收入'], cutx5, woex5)) data['信贷数量'] = Series(replace_woe(data['信贷数量'], cutx6, woex6)) data['逾期90天笔数'] = Series(replace_woe(data['逾期90天笔数'], cutx7, woex7)) data['固定资产贷款量'] = Series(replace_woe(data['固定资产贷款量'], cutx8, woex8)) data['逾期60-89天笔数'] = Series(replace_woe(data['逾期60-89天笔数'], cutx9, woex9)) data['家属数量'] = Series(replace_woe(data['家属数量'], cutx10, woex10)) data.to_csv('WoeData.csv', index=False) test= pd.read_csv('TestData.csv') # 替换成woe test['可用额度比值'] = Series(replace_woe(test['可用额度比值'], cutx1, woex1)) test['年龄'] = Series(replace_woe(test['年龄'], cutx2, woex2)) test['逾期30-59天笔数'] = Series(replace_woe(test['逾期30-59天笔数'], cutx3, woex3)) test['负债率'] = Series(replace_woe(test['负债率'], cutx4, woex4)) test['月收入'] = Series(replace_woe(test['月收入'], cutx5, woex5)) test['信贷数量'] = Series(replace_woe(test['信贷数量'], cutx6, woex6)) test['逾期90天笔数'] = Series(replace_woe(test['逾期90天笔数'], cutx7, woex7)) test['固定资产贷款量'] = Series(replace_woe(test['固定资产贷款量'], cutx8, woex8)) test['逾期60-89天笔数'] = Series(replace_woe(test['逾期60-89天笔数'], cutx9, woex9)) test['家属数量'] = Series(replace_woe(test['家属数量'], cutx10, woex10)) test.to_csv('TestWoeData.csv', index=False) ''' #计算分数 #coe为逻辑回归模型的系数 coe=[9.738849,0.638002,0.505995,1.032246,1.790041,1.131956] # 我们取600分为基础分值,PDO为20(每高20分好坏比翻一倍),好坏比取20。 p = 20 / math.log(2) q = 600 - 20 * math.log(20) / math.log(2) baseScore = round(q + p * coe[0], 0) # 各项部分分数 x1 = get_score(coe[1], woex1, p) x2 = get_score(coe[2], woex2, p) x3 = get_score(coe[3], woex3, p) x7 = get_score(coe[4], woex7, p) x9 = get_score(coe[5], woex9, p) print(x1,x2, x3, x7, x9) test1 = pd.read_csv('TestData.csv') test1['BaseScore']=Series(np.zeros(len(test1)))+baseScore test1['x1'] = Series(compute_score(test1['可用额度比值'], cutx1, x1)) test1['x2'] = Series(compute_score(test1['年龄'], cutx2, x2)) test1['x3'] = Series(compute_score(test1['逾期30-59天笔数'], cutx3, x3)) test1['x7'] = Series(compute_score(test1['逾期90天笔数'], cutx7, x7)) test1['x9'] = Series(compute_score(test1['逾期60-89天笔数'], cutx9, x9)) test1['Score'] = test1['x1'] + test1['x2'] + test1['x3'] + test1['x7'] +test1['x9'] + baseScore test1.to_csv('ScoreData.csv', index=False) plt.show() '''
六、模型分析
证据权重(Weight of Evidence,WOE)转换可以将Logistic回归模型转变为标准评分卡格式。引入WOE转换的目的并不是为了提高模型质量,只是一些变量不应该被纳入模型,这或者是因为它们不能增加模型值,或者是因为与其模型相关系数有关的误差较大,其实建立标准信用评分卡也可以不采用WOE转换。这种情况下,Logistic回归模型需要处理更大数量的自变量。尽管这样会增加建模程序的复杂性,但最终得到的评分卡都是一样的。
在建立模型之前,我们需要将筛选后的变量转换为WoE值,便于信用评分
在建立模型之前,我们需要将筛选后的变量转换为WoE值,便于信用评分
6.1woe转换
我们将每个变量都进行替换,并将其保存到WoeData.csv文件中
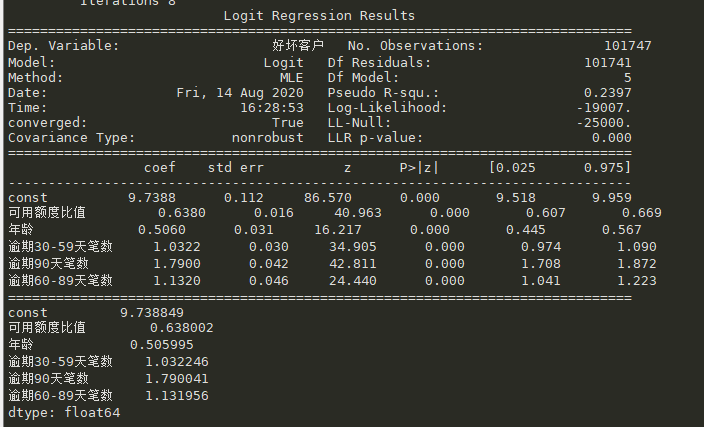
6.2Logisic模型建立
我们直接调用statsmodels包来实现逻辑回归
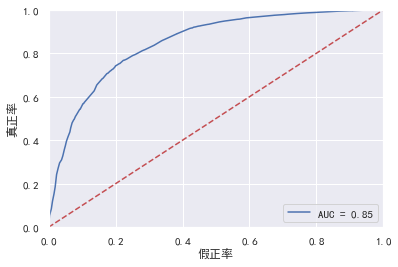
6.3模型检验
到这里,我们的建模部分基本结束了。我们需要验证一下模型的预测能力如何。我们使用在建模开始阶段预留的test数据进行检验。通过ROC曲线和AUC来评估模型的拟合能力。
在Python中,可以利用sklearn.metrics,它能方便比较两个分类器,自动计算ROC和AUC。
在Python中,可以利用sklearn.metrics,它能方便比较两个分类器,自动计算ROC和AUC。
import pandas as pd import matplotlib.pyplot as plt #导入图像库 import matplotlib import seaborn as sns import statsmodels.api as sm from sklearn.metrics import roc_curve, auc if __name__ == '__main__': matplotlib.rcParams['axes.unicode_minus'] = False data = pd.read_csv('WoeData.csv') Y=data['好坏客户'] X=data.drop(['好坏客户','负债率','月收入', '信贷数量','固定资产贷款量','家属数量'],axis=1) X1=sm.add_constant(X) #在X前加上一列常数1,方便做带截距项的回归 logit=sm.Logit(Y,X1) result=logit.fit() print(result.summary()) #我加入的 print(result.params) test = pd.read_csv('TestWoeData.csv') Y_test = test['好坏客户'] X_test = test.drop(['好坏客户', '负债率', '月收入', '信贷数量','固定资产贷款量', '家属数量'], axis=1) X3 = sm.add_constant(X_test) resu = result.predict(X3) fpr, tpr, threshold = roc_curve(Y_test, resu) rocauc = auc(fpr, tpr) plt.plot(fpr, tpr, 'b', label='AUC = %0.2f' % rocauc) plt.legend(loc='lower right') plt.plot([0, 1], [0, 1], 'r--') plt.xlim([0, 1]) plt.ylim([0, 1]) plt.ylabel('真正率') plt.xlabel('假正率') plt.show()
七、信用评分
7.1评分标准

由此可知每个变量不同分段对应的分数是B、β、ω这三个值的乘积,其中β(特征权值系数coe)和ω(WOE值)在前面已知,所以只要知道了AB的值就可以给用户打分了,这里要求AB的值要预先设定几个阈值,
偏移量A=offset
比例因子B=factor
b=offset+factor*log(o)
b+p=offset+factor *log(2o)
由上面score=A-Bβ0,所以log(odds)=β0

#计算分数 #coe为逻辑回归模型的系数 coe=[9.738849,0.638002,0.505995,1.032246,1.790041,1.131956] # 我们取600分为基础分值,PDO为20(每高20分好坏比翻一倍),好坏比取20。 p = 20 / math.log(2) #factor = 20 / np.log(2) q = 600 - 20 * math.log(20) / math.log(2) #offset = 600 - 20 * np.log(20) / np.log(2) baseScore = round(q + p * coe[0], 0) #b=offset+factor*log(o)
各分段的分数计算:
#前面已经有了 def get_score(coe,woe,factor): scores=[] for w in woe: score=round(coe*w*factor,0) scores.append(score) return scores # 各项部分分数 x1 = get_score(coe[1], woex1, p) x2 = get_score(coe[2], woex2, p) x3 = get_score(coe[3], woex3, p) x7 = get_score(coe[4], woex7, p) x9 = get_score(coe[5], woex9, p) print(x1,x2, x3, x7, x9)
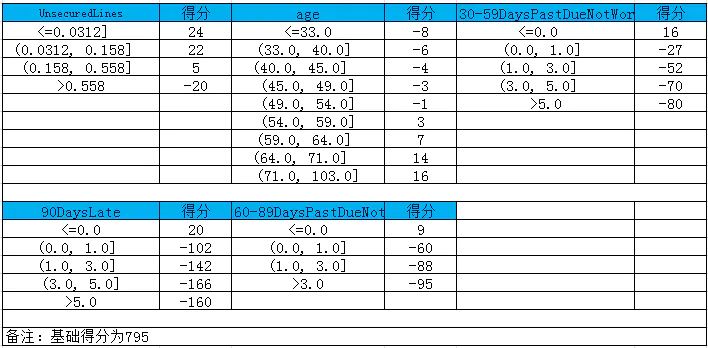
根据变量来计算分数:
首先分数剔除,和woe替换方法一致,然后哥哥分数相加,再加上基础分
#根据变量计算分数 def compute_score(series,cut,score): list = [] i = 0 while i < len(series): value = series[i] j = len(cut) - 2 m = len(cut) - 2 while j >= 0: if value >= cut[j]: j = -1 else: j -= 1 m -= 1 list.append(score[m]) i += 1 return list test1 = pd.read_csv('TestData.csv') test1['BaseScore']=Series(np.zeros(len(test1)))+baseScore #生成一个长度测试集程度一样的元素全部都是基础分的数组 test1['x1'] = Series(compute_score(test1['可用额度比值'], cutx1, x1)) test1['x2'] = Series(compute_score(test1['年龄'], cutx2, x2)) test1['x3'] = Series(compute_score(test1['逾期30-59天笔数'], cutx3, x3)) test1['x7'] = Series(compute_score(test1['逾期90天笔数'], cutx7, x7)) test1['x9'] = Series(compute_score(test1['逾期60-89天笔数'], cutx9, x9)) test1['Score'] = test1['x1'] + test1['x2'] + test1['x3'] + test1['x7'] +test1['x9'] + baseScore test1.to_csv('ScoreData.csv', index=False) plt.show()
文章参考https://www.jianshu.com/p/159f381c661d

 浙公网安备 33010602011771号
浙公网安备 33010602011771号