

数据分析EDA学习总结
探索性数据分析(Exploratory Data Analysis,EDA):是一种探索数据的结构和规律的一种数据分析方法。
其主要的工作包含:
1 对数据进行清洗, 2 对数据进行描述(描述统计量,图表), 3 查看数据的分布, 4 比较数据之间的关系, 5 培养对数据的直觉和对数据进行总结
EDA可以帮助我们找到适合的数据模型,本文针对文本数据,将进行具体的数据探索性分析讲解
数据:https://tianchi.aliyun.com/competition/entrance/531810/information
数据为新闻文本,并按照字符级别进行匿名处理。
整合划分出14个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐的文本数据
数据由以下几个部分构成:训练集20w条样本,测试集A包括5w条样本,测试集B包括5w条样本
数据集中标签的对应的关系如下:
{'科技': 0, '股票': 1, '体育': 2, '娱乐': 3, '时政': 4, '社会': 5, '教育': 6, '财经': 7, '家居': 8, '游戏': 9, '房产': 10, '时尚': 11, '彩票': 12, '星座': 13}
1.导入模块
#导入所需的模块 import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split import seaborn as sns import scipy from collections import Counter
2.导入数据
#导入数据 df_train = pd.read_csv('F:\\python\\EDA\\train_set\\train_set.csv', sep='\t') df_test = pd.read_csv('F:\\python\\EDA\\test_a\\test_a.csv', sep='\t')
3.1简单查看数据
#简单查看数据 df_train.head(),len(df_train)
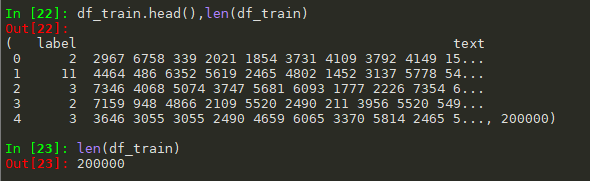
看看text里面的内容是什么
len(df_train['text'][0]) #5120 type(df_train['text'][0]) #str
3.2长度分布
3.2.1describ
#describe df_train.describe() #由于text是str,我们需要将数据先切分,在计算长度 df_text=df_train['text'].apply(lambda x: len(str(x).split())) df_text.describe()

测试集的describe
#测试集describe df_text_test=df_test['text'].apply(lambda x: len(str(x).split())) df_text_test.describe()
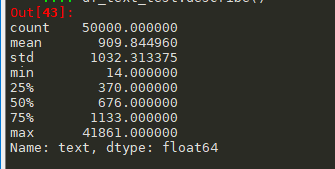
通过数据描述我们可以看出:
1 训练集有20万条新闻,每条新闻平均有907个字符,最短有2个字符,最长的有57921,其中75%的在1131以下 2 测试集有5万条新闻,每条新闻平均有909条字符,最短有14个字符,最长的有41861,其中75%在1133以下 3 总的来说,训练集和测试集就长度来说分布基本一致
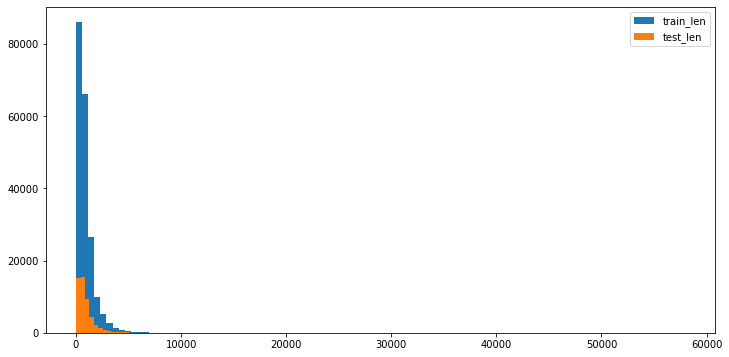
3.2.2直方图
#画直方图 fig,ax=plt.subplots(1,1,figsize=(12,6)) ax=plt.hist(x=df_text,bins=100) ax=plt.hist(x=df_text_test,bins=100) plt.legend(['train_len','test_len'])
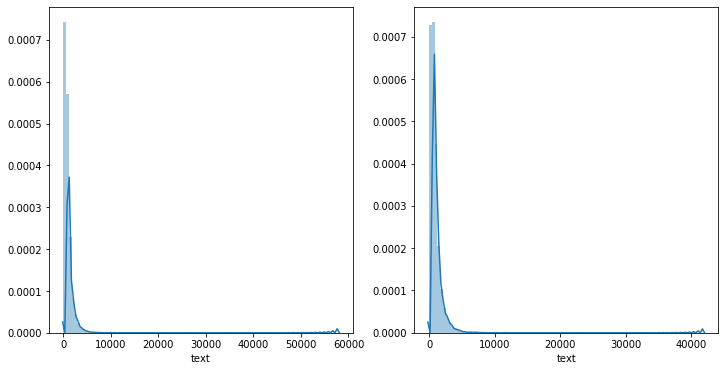
前面文章有说过,连续性数字特征可以用sns.distplot()查看数据符合什么分布https://www.cnblogs.com/cgmcoding/p/13384535.html
#使用sns.displot() fig, ((ax1, ax2)) = plt.subplots(nrows=1, ncols=2,figsize=(12,6)) sns.distplot(df_text,bins=100,ax=ax1) sns.distplot(df_text_test,bins=100,ax=ax2)
3.2.3同分布检验
如果p值大于0.05,则接受原假设,即是同分布
#同分布检验 import scipy scipy.stats.ks_2samp(df_text, df_text_test) #Out[56]: Ks_2sampResult(statistic=0.004049999999999998, pvalue=0.5279614323123156) scipy.stats.mannwhitneyu(df_text, df_text_test) #Out[57]: MannwhitneyuResult(statistic=4998619866.0, pvalue=0.46191187195256883)
3.2.4截断位置
上面的图画可以看出数据符合长尾分布,我们使用log(x),看看log之后数据是否符合正态分布
#log() #训练集 plt.figure(figsize=(12,6)) log_len_train=np.log(1+df_text) sns.distplot(log_len_train) plt.title('train_len') #测试集 plt.figure(figsize=(12,6)) log_len_test=np.log(1+df_text_test) sns.distplot(log_len_test) plt.title('test_len')
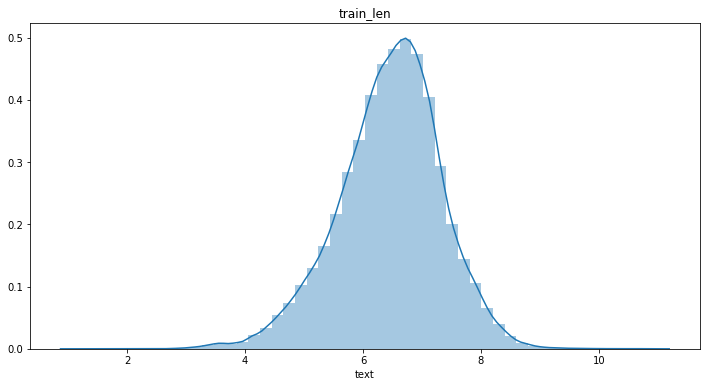

查看log之后的数据是否符合正态分布
#验证log之后的数据是否符合正态分布 #方法一、 scipy.stats.shapiro(log_len_train) #(0.9918177127838135, 0.0) #方法二、 scipy.stats.kstest(log_len_train, 'norm') #KstestResult(statistic=0.9986036638974649, pvalue=0.0)
由于p值小于0.05,所以log之后的数据并不符合正态分布
但总归是要猜一个截断值的。看log图上8.5的位置比较靠谱。np.exp(8.5)=4914约等于5000,因此我初步决定把截断长度定为5000
3.3类别特征
3.3.1构造新的特征
根据text构造
1 text-split,将text字段分词 2 len,每条新闻长度 3 first_char,新闻第一个字符 4 last_char,新闻最后一个字符 5 most_freq,新闻最常出现的字符
构造上面的特征(跑程序时卡死了,可能是内存不够吧)
#构造特征 df_train['text_split'] = df_train['text'].apply(lambda x:x.split()) df_train['len'] = df_train['text'].apply(lambda x:len(x.split())) df_train['first_char'] = df_train['text_split'].apply(lambda x:x[0]) df_train['last_char'] = df_train['text_split'].apply(lambda x:x[-1]) df_train['most_freq'] = df_train['text_split'].apply(lambda x:np.argmax(np.bincount(x))) df_train.head()
构建一个label信息表
1 count,该类别新闻个数 2 len_mean,该类别新闻平均长度 3 len_std,该类别新闻长度标准差 4 len_min,该类别新闻长度最小值 5 len_max,该类别新闻长度最大值 6 freq_fc,该类别新闻最常出现的第一个字符 7 freq_lc,该类别新闻最常出现的最后一个字符 8 freq_freq,该类别新闻最常出现的字符
#构造label的特征 df_train_info = pd.DataFrame(columns=['count','len_mean','len_std','len_min','len_max','freq_fc','freq_lc','freq_freq']) for name, group in df_train.groupby('label'): count = len(group) # 该类别新闻数 len_mean = np.mean(group['len']) # 该类别长度平均值 len_std = np.std(group['len']) # 长度标准差 len_min = np.min(group['len']) # 最短的新闻长度 len_max = np.max(group['len']) # 最长的新闻长度 freq_fc = np.argmax(np.bincount(group['first_char'])) # 最频繁出现的首词 freq_lc = np.argmax(np.bincount(group['last_char'])) # 最频繁出现的末词 freq_freq = np.argmax(np.bincount(group['most_freq'])) # 该类别最频繁出现的词 df_train_info.loc[name] = [count,len_mean,len_std,len_min,len_max,freq_fc,freq_lc,freq_freq] df_train_info
3.3.2类别分布
需要验证一下y值,即是label的分布是否均匀
#label的分布 label_2_index_dict = {'科技': 0, '股票': 1, '体育': 2, '娱乐': 3, '时政': 4, '社会': 5, '教育': 6, '财经': 7, '家居': 8, '游戏': 9, '房产': 10, '时尚': 11, '彩票': 12, '星座': 13} index_2_label_dict = {v:k for k,v in label_2_index_dict.items()} plt.figure() plt.bar(x=range(14), height=np.bincount(df_train['label'])) plt.xlabel("label") plt.ylabel("number of sample") plt.xticks(range(14), list(index_2_label_dict.values()), fontproperties=zhfont, rotation=60) plt.show() #df_train['label'].plot.bar() df_train['label'].value_counts()
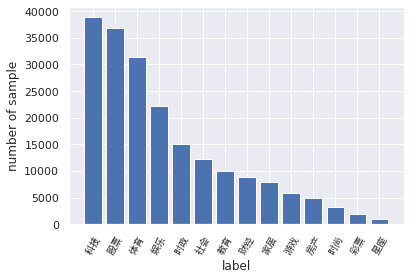
从统计结果可以看出:
1 赛题的数据集类别分布存在较为不均匀的情况。在训练集中科技类新闻最多,其次是股票类新闻,最少的新闻是星座新闻。 2 科技类新闻最多,星座类新闻最少。这个国家的人大部分是唯物主义者哈,神秘学受众比较少(啊这,我在分析什么?)。 3 由于类别不均衡,会严重影响模型的精度。但是我们也是有办法应对的
3.3.3label长度
df_train['len'] = df_train['text'].apply(lambda x: len(x.split())) plt.figure() ax = sns.catplot(x='label', y='len', data=df_train, kind='strip') plt.xticks(range(14), list(index_2_label_dict.values()), fontproperties=zhfont, rotation=60)
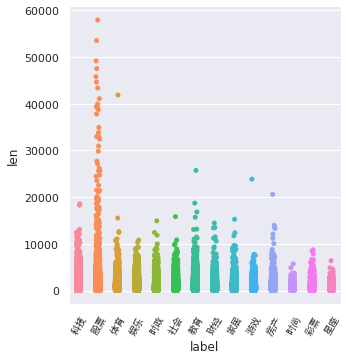
在散点图中,股票类新闻的长度都飘到天上去了,可以看出股票分析类文章真的很容易写得又臭又长啊(发现:不同类别的文章长度不同,可以把长度作为一个Feature,以供机器学习模型训练)
3.4字符分布
训练集中总共包括6869个字,最大数字为7549,最小数字为0,其中编号3750的字出现的次数最多,编号3133的字出现的次数最少,仅出现一次
# 内存警告!!!没有8G内存不要运行该代码 all_lines = ' '.join(list(df_train['text'])) word_count = Counter(all_lines.split(" ")) word_count = sorted(word_count.items(), key=lambda d:d[1], reverse=True) print(len(word_count)) # 6869 print(word_count[0]) # ('3750', 7482224) print(word_count[-1]) # ('3133', 1)
下面代码统计了不同字符在多少个句子中出现过,其中字符3750、字符900和字符648在20w新闻的覆盖率接近99%,很有可能是标点符号:
%%time df_train['text_unique'] = df_train['text'].apply(lambda x: ' '.join(list(set(x.split(' '))))) all_lines = ' '.join(list(df_train['text_unique'])) word_count = Counter(all_lines.split(" ")) word_count = sorted(word_count.items(), key=lambda d:int(d[1]), reverse=True) # 打印整个训练集中覆盖率前5的词 for i in range(5): print("{} occurs {} times, {}%".format(word_count[i][0], word_count[i][1], (word_count[i][1]/200000)*100))

4、总结分析
数据分析肯定要有结论,没有结论的数据分析是不完整的
1 训练集共200,000条新闻,每条新闻平均907个字符,最短的句子长度为2,最长的句子长度为57921,其中75%以下的数据长度在1131以下。测试集共50,000条新闻,每条新闻平均909个字符,最短句子长度为14,最长句子41861,75%以下的数据长度在1133以下。 2 训练集和测试集就长度来说似乎是同一分布,但是不属于正态分布。 3 赛题的数据集类别分布存在较为不均匀的情况。在训练集中科技类新闻最多,其次是股票类新闻,最少的新闻是星座新闻。需要用采样方法解决。文章最长的是股票类新闻。不同类别的文章长度不同,可以把长度和句子个数作为一个Feature,以供机器学习模型训练。 4 训练集中总共包括6869个字,最大数字为7549,最小数字为0,其中编号3750的字出现的次数最多,编号3133的字出现的次数最少,仅出现一次,其中字符3750、字符900和字符648在20w新闻的覆盖率接近99%,很有可能是标点符号。 5 900很有可能是句号,2662和885则很有可能为感叹号和问号,3750出现频率很高但是基本不在新闻最后出现,因此初步判断为逗号。按照这种划分,训练集中每条新闻平均句子个数约为19。 6 在训练集中,不同类别新闻出现词汇有特色。但是需要把共有的常用词停用。自然想到利用TF-IDF编码方式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号