
天池二手车_特征工程
前面已经做了类别和连续特征的分析,本文将针对特征工程进行
导入数据
import pandas as pd import numpy as np import matplotlib import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline #导入训练集和测试集 train_data =pd.read_csv('F:\\python\\天池_二手车交易价格预测\\used_car_train_20200313.csv',sep=' ') test_data=pd.read_csv('F:\\python\\天池_二手车交易价格预测\\used_car_testB_20200421.csv',sep=' ')
删除异常值
#异常值处理 def out_proc(data,col_name,scale=3): def box_plot_out(data_ser,box_scale): ''' data_ser接受pd.Series数据格式 ''' iqr=box_scale*(data_ser.quantile(0.75)-data_ser.quantile(0.25)) #0.75分位数的值-0.25分位数的值 val_low=data_ser.quantile(0.25)-iqr val_up=data_ser.quantile(0.75) + iqr rule_low = (data_ser < val_low) rule_up = (data_ser > val_up) return (rule_low, rule_up), (val_low, val_up) #前面返回异常的pandas.Series 数据,后面返回临界值 data_n=data.copy() #先复制一个df data_series=data_n[col_name] #某一列的值 rule, value = box_plot_out(data_series, box_scale=scale) index = np.arange(data_series.shape[0])[rule[0] | rule[1]] #shape[0]是行数,丨是or的意思,真个就是输出有异常值的索引数 print("Delete number is: {}".format(len(index))) #输出异常值个数 data_n = data_n.drop(index) #删除异常值 data_n.reset_index(drop=True, inplace=True) #重新设置索引 print("Now column number is: {}".format(data_n.shape[0])) #删除异常值之后数值的个数 index_low = np.arange(data_series.shape[0])[rule[0]] #低于临界值的索引数 outliers = data_series.iloc[index_low] #低于临界值的值 print("Description of data less than the lower bound is:") print(pd.Series(outliers).describe()) index_up = np.arange(data_series.shape[0])[rule[1]] outliers = data_series.iloc[index_up] print("Description of data larger than the upper bound is:") print(pd.Series(outliers).describe()) fig, ax = plt.subplots(1, 2, figsize=(10, 7)) sns.boxplot(y=data[col_name], data=data, palette="Set1", ax=ax[0]) #某列原来的箱型图 sns.boxplot(y=data_n[col_name], data=data_n, palette="Set1", ax=ax[1]) #删除异常值后的箱型图 return data_n #返回删除后的值
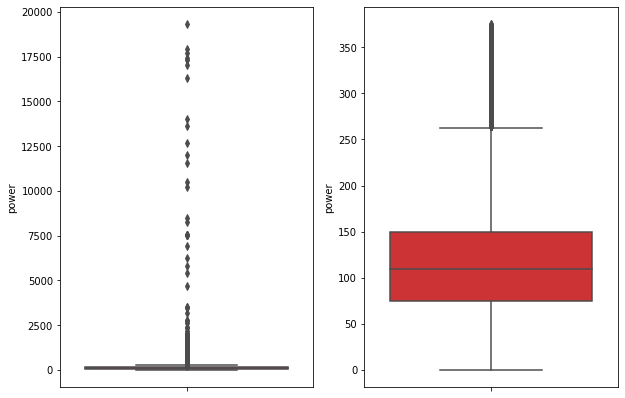
train_data根据power删除一些异常值
# 这里删不删同学可以自行判断 # 但是要注意 test 的数据不能删 = = 不能掩耳盗铃是不是 train_data= out_proc(train_data,'power',scale=3) train_data.shape #(149037, 31)
特征构造
训练集和测试集放在一起,方便构造特征
#用一列做标签区分一下训练集和测试集 train_data['train']=1 test_data['train']=0 data = pd.concat([train_data, test_data], ignore_index=True)
创建汽车使用时间(data['creatDate'] - data['regDate'])
# 不过要注意,数据里有时间出错的格式,所以我们需要 errors='coerce' data['used_time'] = (pd.to_datetime(data['creatDate'], format='%Y%m%d', errors='coerce') - pd.to_datetime(data['regDate'], format='%Y%m%d', errors='coerce')).dt.days
由于有些样本有问题,导致使用时间为空,我们计算一下空值的个数
data['used_time'].isnull().sum() #15054
从邮编中提取城市信息,相当于加入了先验知识
data['city'] = data['regionCode'].apply(lambda x : str(x)[:-3]) data = data
计算某个特征的数据统计量
# 这里要以 train 的数据计算统计量
count_data=train_data.groupby('brand') all_info={} for kind,kind_data in count_data: info={} kind_data=kind_data[kind_data['price']>0] #选出价格大于0的数值 info['brand_amount']=len(kind_data) #每个分组中价格大于0有多少行数据 info['brand_price_max']=kind_data.price.max() info['brand_price_median'] = kind_data.price.median() info['brand_price_min'] = kind_data.price.min() info['brand_price_sum'] = kind_data.price.sum() info['brand_price_std'] = kind_data.price.std() info['brand_price_average'] = round(kind_data.price.sum() / (len(kind_data) + 1), 2) all_info[kind] = info #每个kind的详细数据硬录入里面,这就要分清楚for循环中,变量在里面和在外面的区别
得到的all_info如下:
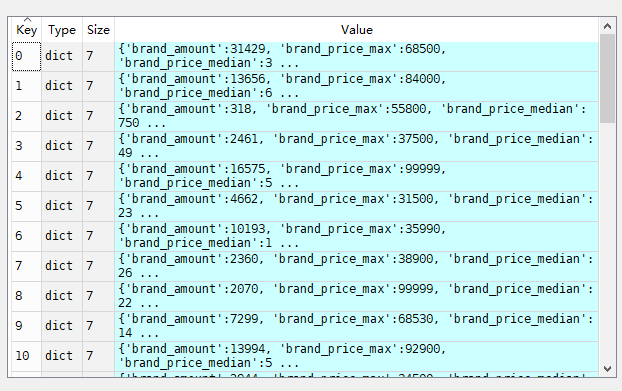
#对于这种value种还有ke的字典,可以使用pd.DataFrame转换成df brand_fe = pd.DataFrame(all_info).T.reset_index().rename(columns={"index": "brand"}) #转置,重新设索引,只是为了后面和表连接起来 data=data.merge(brand_fe,how='left',on='brand')
数据分箱的好处:
1. 离散后稀疏向量内积乘法运算速度更快,计算结果也方便存储,容易扩展;
2. 离散后的特征对异常值更具鲁棒性,如 age>30 为 1 否则为 0,对于年龄为 200 的也不会对模型造成很大的干扰;
3. LR 属于广义线性模型,表达能力有限,经过离散化后,每个变量有单独的权重,这相当于引入了非线性,能够提升模型的表达能力,加大拟合;
4. 离散后特征可以进行特征交叉,提升表达能力,由 M+N 个变量编程 M*N 个变量,进一步引入非线形,提升了表达能力;
5. 特征离散后模型更稳定,如用户年龄区间,不会因为用户年龄长了一岁就变化
#power分箱,因为上面箱型图最大值也就是300左右 bin=[i*10 for i in range(31)] data['power_bin']=pd.cut(data['power'],bins=bin,labels=False) #nan值超出范围了
删除不需要的特征
data = data.drop(['creatDate', 'regDate', 'regionCode'], axis=1)
保存数据,给树模型使用,树模型不需要归一化
# 目前的数据其实已经可以给树模型使用了,所以我们导出一下 data.to_csv('data_for_tree.csv', index=0)
构造一份特征给 LR NN 之类的模型用,之所以分开构造是因为,不同模型对数据集的要求不同
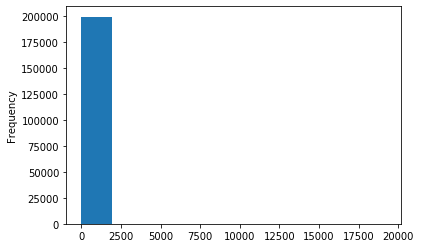
# 我们可以再构造一份特征给 LR NN 之类的模型用 # 之所以分开构造是因为,不同模型对数据集的要求不同 # 我们看下数据分布: data['power'].plot.hist() # 我们刚刚已经对 train 进行异常值处理了,但是现在还有这么奇怪的分布是因为 test 中的 power 异常值, # 所以我们其实刚刚 train 中的 power 异常值不删为好,可以用长尾分布截断来代替 train_data['power'].plot.hist()
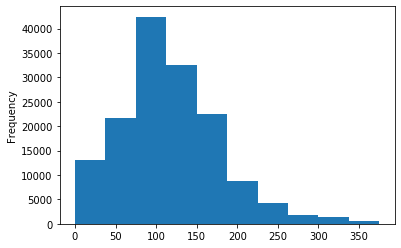
#先取log,在做归一化 data['power']=np.log(data['power']+1) data['power']=(data['power']-data['power'].min())/(data['power'].max()-data['power'].min()) data['power'].plot.hist()
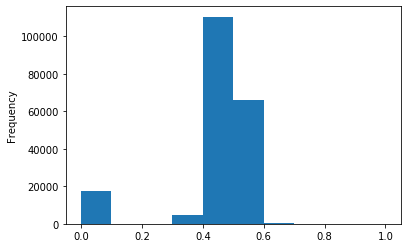
#这个原数据就已经分过箱了,就不需要分箱了 data['kilometer'].plot.hist()
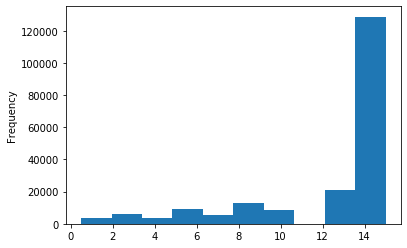
#可以直接归一化 data['kilometer']=(data['kilometer']-data['kilometer'].min())/(data['kilometer'].max()-data['kilometer'].min())
刚才构造的数据统计量也要归一化
# 除此之外 还有我们刚刚构造的统计量特征: # 'brand_amount', 'brand_price_average', 'brand_price_max', # 'brand_price_median', 'brand_price_min', 'brand_price_std', # 'brand_price_sum' # 这里不再一一举例分析了,直接做变换, def max_min(x): return (x - np.min(x)) / (np.max(x) - np.min(x)) data['brand_amount'] = ((data['brand_amount'] - np.min(data['brand_amount'])) / (np.max(data['brand_amount']) - np.min(data['brand_amount']))) data['brand_price_average'] = ((data['brand_price_average'] - np.min(data['brand_price_average'])) / (np.max(data['brand_price_average']) - np.min(data['brand_price_average']))) data['brand_price_max'] = ((data['brand_price_max'] - np.min(data['brand_price_max'])) / (np.max(data['brand_price_max']) - np.min(data['brand_price_max']))) data['brand_price_median'] = ((data['brand_price_median'] - np.min(data['brand_price_median'])) / (np.max(data['brand_price_median']) - np.min(data['brand_price_median']))) data['brand_price_min'] = ((data['brand_price_min'] - np.min(data['brand_price_min'])) / (np.max(data['brand_price_min']) - np.min(data['brand_price_min']))) data['brand_price_std'] = ((data['brand_price_std'] - np.min(data['brand_price_std'])) / (np.max(data['brand_price_std']) - np.min(data['brand_price_std']))) data['brand_price_sum'] = ((data['brand_price_sum'] - np.min(data['brand_price_sum'])) / (np.max(data['brand_price_sum']) - np.min(data['brand_price_sum'])))
对类别特征要进行独热编码
# 对类别特征进行 OneEncoder data = pd.get_dummies(data, columns=['model', 'brand', 'bodyType', 'fuelType', 'gearbox', 'notRepairedDamage', 'power_bin'])
保存数据,留给LR使用
# 这份数据可以给 LR 用 data.to_csv('data_for_lr.csv', index=0)
特征构造完毕,特征刷选
特征筛选
过滤式
主要思想: 对每一维特征“打分”,即给每一维的特征赋予权重,这样的权重就代表着该特征的重要性,然后依据权重排序。先进行特征选择,然后去训练学习器,所以特征选择的过程与学习器无关。相当于先对特征进行过滤操作,然后用特征子集来训练分类器。
主要方法:
- 移除低方差的特征(太平稳,比如全都是1,对y值没有多大的影响);
- 相关系数排序,分别计算每个特征与输出值之间的相关系数,设定一个阈值,选择相关系数大于阈值的部分特征;
- 利用假设检验得到特征与输出值之间的相关性,方法有比如卡方检验、t检验、F检验等。
- 互信息,利用互信息从信息熵的角度分析相关性。
这里,本文为大家提供一些有价值的小tricks:
- 对于数值型特征,方差很小的特征可以不要,因为太小没有什么区分度,提供不了太多的信息,对于分类特征,也是同理,取值个数高度偏斜的那种可以先去掉。
- 根据与目标的相关性等选出比较相关的特征(当然有时候根据字段含义也可以选)
- 卡方检验一般是检查离散变量与离散变量的相关性,当然离散变量的相关性信息增益和信息增益比也是不错的选择(可以通过决策树模型来评估来看),person系数一般是查看连续变量与连续变量的线性相关关系。
去掉取值变化小的特征
这应该是最简单的特征选择方法了:假设某特征的特征值只有0和1,并且在所有输入样本中,95%的实例的该特征取值都是1,那就可以认为这个特征作用不大。如果100%都是1,那这个特征就没意义了。
当特征值都是离散型变量的时候这种方法才能用,如果是连续型变量,就需要将连续变量离散化之后才能用,而且实际当中,一般不太会有95%以上都取某个值的特征存在,所以这种方法虽然简单但是不太好用。
可以把它作为特征选择的预处理,先去掉那些取值变化小的特征,然后再从接下来提到的的特征选择方法中选择合适的进行进一步的特征选择。例如,我们前面的seller和offerType特征。
#用法 df.std().sort_values()
相关性分析
# 相关性分析 print(data['power'].corr(data['price'], method='spearman')) print(data['kilometer'].corr(data['price'], method='spearman')) print(data['brand_amount'].corr(data['price'], method='spearman')) print(data['brand_price_average'].corr(data['price'], method='spearman')) print(data['brand_price_max'].corr(data['price'], method='spearman')) print(data['brand_price_median'].corr(data['price'], method='spearman'))
0.5728285196051496
-0.4082569701616764
0.058156610025581514
0.3834909576057687
0.259066833880992
0.38691042393409447
# 当然也可以直接看图 data_numeric = data[['power', 'kilometer', 'brand_amount', 'brand_price_average', 'brand_price_max', 'brand_price_median']] correlation = data_numeric.corr() f , ax = plt.subplots(figsize = (7, 7)) plt.title('Correlation of Numeric Features with Price',y=1,size=16) sns.heatmap(correlation,square = True, vmax=0.8)
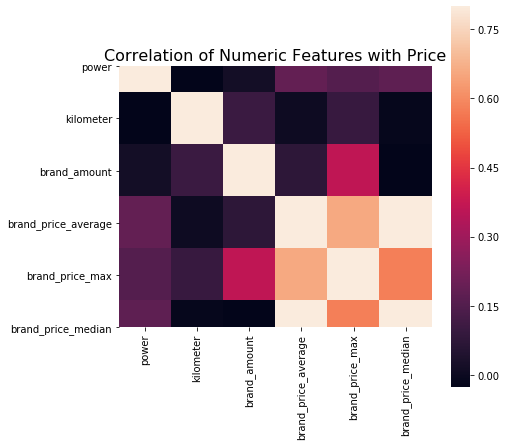
包裹式
单变量特征选择方法独立的衡量每个特征与响应变量之间的关系,另一种主流的特征选择方法是基于机器学习模型的方法。有些机器学习方法本身就具有对特征进行打分的机制,或者很容易将其运用到特征选择任务中,例如回归模型,SVM,决策树,随机森林等等。
主要思想:包裹式从初始特征集合中不断的选择特征子集,训练学习器,根据学习器的性能来对子集进行评价,直到选择出最佳的子集。包裹式特征选择直接针对给定学习器进行优化。
主要方法:递归特征消除算法, 基于机器学习模型的特征排序
优缺点:
优点:从最终学习器的性能来看,包裹式比过滤式更好;
缺点:由于特征选择过程中需要多次训练学习器,因此包裹式特征选择的计算开销通常比过滤式特征选择要大得多。
下面,这里整理基于学习模型的特征排序方法,这种方法的思路是直接使用你要用的机器学习算法,针对每个单独的特征和响应变量建立预测模型。其实Pearson相关系数等价于线性回归里的标准化回归系数。
假如某个特征和响应变量之间的关系是非线性的,可以用基于树的方法(决策树、随机森林)、或者扩展的线性模型等。基于树的方法比较易于使用,因为他们对非线性关系的建模比较好,并且不需要太多的调试。但要注意过拟合问题,因此树的深度最好不要太大,再就是运用交叉验证。
下面的是例子,非本次数据:
from sklearn.model_selection import cross_val_score, ShuffleSplit from sklearn.ensemble import RandomForestRegressor from sklearn.model_selection import KFold from sklearn import datasets # iris=datasets.load_iris() Y = iris.target X = pd.DataFrame(iris.data,columns=iris.feature_names) names = train_data.columns rf = RandomForestRegressor(n_estimators=20, max_depth=4) kfold = KFold(n_splits=5, shuffle=True, random_state=7) scores = [] for column in X.columns: print(column) tempx = X[column].values.reshape(-1, 1) #后面会解释 score = cross_val_score(rf, tempx, Y, scoring="r2", cv=kfold) scores.append((round(np.mean(score), 3), column)) print(sorted(scores, reverse=True)) ''' sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) [(0.937, 'petal length (cm)'), (0.934, 'petal width (cm)'), (0.634, 'sepal length (cm)'), (0.175, 'sepal width (cm)')] '''
这里就可以看出随机森林有用的特征排序,如果我们后面选择随机森林作为模型,就可以根据这个特征重要度选择特征。当然,如果你是xgboost,xgboost里面有个画特征重要性的函数,可以这样做:
# 下面再用xgboost跑一下 from xgboost import XGBRegressor from xgboost import plot_importance xgb = XGBRegressor() xgb.fit(X, Y) plt.figure(figsize=(20, 10)) plot_importance(xgb) plt.show()
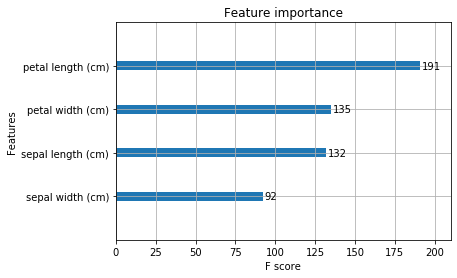
最后,我们把上面的这两种方式封装起来, 还可以画出边际效应:
from mlxtend.feature_selection import SequentialFeatureSelector as SFS from sklearn.linear_model import LinearRegression from sklearn.ensemble import RandomForestRegressor # sfs = SFS(LinearRegression(), k_features=20, forward=True, floating=False, scoring='r2', cv=0) sfs = SFS(RandomForestRegressor(n_estimators=10, max_depth=4), k_features=3, forward=True, floating=False, scoring='r2', cv=0) g = pd.DataFrame(iris.data,columns=iris.feature_names) x=X x['sample']=iris.target Y=x['sample'] sfs.fit(g.values, Y.values) #Xy不能是df #sfs.k_feature_names_ # 随机森林放这里跑太慢了,所以中断了 sfs.subsets_
再回到本文例子
# k_feature 太大会很难跑,没服务器,所以提前 interrupt 了 from mlxtend.feature_selection import SequentialFeatureSelector as SFS from sklearn.linear_model import LinearRegression sfs = SFS(LinearRegression(), k_features=10, forward=True, floating=False, scoring = 'r2', cv = 0) x = data.drop(['price'], axis=1) x = x.fillna(0) y = data['price'] sfs.fit(x, y) #xy不能是df sfs.k_feature_names_ #没有这个函数 ##其实上面的例子跑不成功,我修改了一下 sfs.fit(x.values, y.values) #xy不能是df sfs.subsets_ #没有这个函数 #还是没能成功
# 画出来,可以看到边际效益 from mlxtend.plotting import plot_sequential_feature_selection as plot_sfs import matplotlib.pyplot as plt fig1 = plot_sfs(sfs.get_metric_dict(), kind='std_dev') plt.grid() plt.show()
全部代码


# -*- coding: utf-8 -*- """ Created on Tue Aug 11 10:12:48 2020 @author: Admin """ import pandas as pd import numpy as np import matplotlib import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline #导入训练集和测试集 train_data =pd.read_csv('F:\\python\\天池_二手车交易价格预测\\used_car_train_20200313.csv',sep=' ') test_data=pd.read_csv('F:\\python\\天池_二手车交易价格预测\\used_car_testB_20200421.csv',sep=' ') #异常值处理 def out_proc(data,col_name,scale=3): def box_plot_out(data_ser,box_scale): ''' data_ser接受pd.Series数据格式 ''' iqr=box_scale*(data_ser.quantile(0.75)-data_ser.quantile(0.25)) #0.75分位数的值-0.25分位数的值 val_low=data_ser.quantile(0.25)-iqr val_up=data_ser.quantile(0.75) + iqr rule_low = (data_ser < val_low) rule_up = (data_ser > val_up) return (rule_low, rule_up), (val_low, val_up) #前面返回异常的pandas.Series 数据,后面返回临界值 data_n=data.copy() #先复制一个df data_series=data_n[col_name] #某一列的值 rule, value = box_plot_out(data_series, box_scale=scale) index = np.arange(data_series.shape[0])[rule[0] | rule[1]] #shape[0]是行数,丨是or的意思,真个就是输出有异常值的索引数 print("Delete number is: {}".format(len(index))) #输出异常值个数 data_n = data_n.drop(index) #删除异常值 data_n.reset_index(drop=True, inplace=True) #重新设置索引 print("Now column number is: {}".format(data_n.shape[0])) #删除异常值之后数值的个数 index_low = np.arange(data_series.shape[0])[rule[0]] #低于临界值的索引数 outliers = data_series.iloc[index_low] #低于临界值的值 print("Description of data less than the lower bound is:") print(pd.Series(outliers).describe()) index_up = np.arange(data_series.shape[0])[rule[1]] outliers = data_series.iloc[index_up] print("Description of data larger than the upper bound is:") print(pd.Series(outliers).describe()) fig, ax = plt.subplots(1, 2, figsize=(10, 7)) sns.boxplot(y=data[col_name], data=data, palette="Set1", ax=ax[0]) #某列原来的箱型图 sns.boxplot(y=data_n[col_name], data=data_n, palette="Set1", ax=ax[1]) #删除异常值后的箱型图 return data_n #返回删除后的值 train_data= out_proc(train_data,'power',scale=3) train_data.shape #用一列做标签区分一下训练集和测试集 train_data['train']=1 test_data['train']=0 data = pd.concat([train_data, test_data], ignore_index=True) # 不过要注意,数据里有时间出错的格式,所以我们需要 errors='coerce' data['used_time'] = (pd.to_datetime(data['creatDate'], format='%Y%m%d', errors='coerce') - pd.to_datetime(data['regDate'], format='%Y%m%d', errors='coerce')).dt.days data['used_time'].isnull().sum() #15054 data['city'] = data['regionCode'].apply(lambda x : str(x)[:-3]) data = data # 这里要以 train 的数据计算统计量 count_data=train_data.groupby('brand') all_info={} for kind,kind_data in count_data: info={} kind_data=kind_data[kind_data['price']>0] #选出价格大于0的数值 info['brand_amount']=len(kind_data) #每个分组中价格大于0有多少行数据 info['brand_price_max']=kind_data.price.max() info['brand_price_median'] = kind_data.price.median() info['brand_price_min'] = kind_data.price.min() info['brand_price_sum'] = kind_data.price.sum() info['brand_price_std'] = kind_data.price.std() info['brand_price_average'] = round(kind_data.price.sum() / (len(kind_data) + 1), 2) all_info[kind] = info #每个kind的详细数据硬录入里面,这就要分清楚for循环中,变量在里面和在外面的区别 #对于这种value种还有ke的字典,可以使用pd.DataFrame转换成df brand_fe = pd.DataFrame(all_info).T.reset_index().rename(columns={"index": "brand"}) #转置,重新设索引,只是为了后面和表连接起来 data=data.merge(brand_fe,how='left',on='brand') bin=[i*10 for i in range(31)] data['power_bin']=pd.cut(data['power'],bins=bin,labels=False) #nan值超出范围了 data = data.drop(['creatDate', 'regDate', 'regionCode'], axis=1) # 目前的数据其实已经可以给树模型使用了,所以我们导出一下 data.to_csv('data_for_tree.csv', index=0) # 我们可以再构造一份特征给 LR NN 之类的模型用 # 之所以分开构造是因为,不同模型对数据集的要求不同 # 我们看下数据分布: data['power'].plot.hist() # 我们刚刚已经对 train 进行异常值处理了,但是现在还有这么奇怪的分布是因为 test 中的 power 异常值, # 所以我们其实刚刚 train 中的 power 异常值不删为好,可以用长尾分布截断来代替 train_data['power'].plot.hist() # 我们对其取 log,在做归一化 from sklearn import preprocessing min_max_scaler = preprocessing.MinMaxScaler() data['power'] = np.log(data['power'] + 1) data['power'] = ((data['power'] - np.min(data['power'])) / (np.max(data['power']) - np.min(data['power']))) data['power'].plot.hist() #这个原数据就已经分过箱了,就不需要分箱了 data['kilometer'].plot.hist() #可以直接归一化 data['kilometer']=(data['kilometer']-data['kilometer'].min())/(data['kilometer'].max()-data['kilometer'].min()) # 除此之外 还有我们刚刚构造的统计量特征: # 'brand_amount', 'brand_price_average', 'brand_price_max', # 'brand_price_median', 'brand_price_min', 'brand_price_std', # 'brand_price_sum' # 这里不再一一举例分析了,直接做变换, def max_min(x): return (x - np.min(x)) / (np.max(x) - np.min(x)) data['brand_amount'] = ((data['brand_amount'] - np.min(data['brand_amount'])) / (np.max(data['brand_amount']) - np.min(data['brand_amount']))) data['brand_price_average'] = ((data['brand_price_average'] - np.min(data['brand_price_average'])) / (np.max(data['brand_price_average']) - np.min(data['brand_price_average']))) data['brand_price_max'] = ((data['brand_price_max'] - np.min(data['brand_price_max'])) / (np.max(data['brand_price_max']) - np.min(data['brand_price_max']))) data['brand_price_median'] = ((data['brand_price_median'] - np.min(data['brand_price_median'])) / (np.max(data['brand_price_median']) - np.min(data['brand_price_median']))) data['brand_price_min'] = ((data['brand_price_min'] - np.min(data['brand_price_min'])) / (np.max(data['brand_price_min']) - np.min(data['brand_price_min']))) data['brand_price_std'] = ((data['brand_price_std'] - np.min(data['brand_price_std'])) / (np.max(data['brand_price_std']) - np.min(data['brand_price_std']))) data['brand_price_sum'] = ((data['brand_price_sum'] - np.min(data['brand_price_sum'])) / (np.max(data['brand_price_sum']) - np.min(data['brand_price_sum']))) # 对类别特征进行 OneEncoder data = pd.get_dummies(data, columns=['model', 'brand', 'bodyType', 'fuelType', 'gearbox', 'notRepairedDamage', 'power_bin']) # 这份数据可以给 LR 用 data.to_csv('data_for_lr.csv', index=0) # 相关性分析 print(data['power'].corr(data['price'], method='spearman')) print(data['kilometer'].corr(data['price'], method='spearman')) print(data['brand_amount'].corr(data['price'], method='spearman')) print(data['brand_price_average'].corr(data['price'], method='spearman')) print(data['brand_price_max'].corr(data['price'], method='spearman')) print(data['brand_price_median'].corr(data['price'], method='spearman')) # 当然也可以直接看图 data_numeric = data[['power', 'kilometer', 'brand_amount', 'brand_price_average', 'brand_price_max', 'brand_price_median']] correlation = data_numeric.corr() f , ax = plt.subplots(figsize = (7, 7)) plt.title('Correlation of Numeric Features with Price',y=1,size=16) sns.heatmap(correlation,square = True, vmax=0.8)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号