
pandas merge,append,join,concat数据之间连接
一般左右连接使用merge,join,上下连接使用concat,append
1.merge
如果是多条件
model_data = pd.merge( data_due_outliers_stand,data_due_merge_cate_stand,on=['apply_no','ref_id'],how='left')
类似数据库的,on可以有2个或者多个条件,一定要有on条件,不然就没有结果,默认的是内连接
data1 = pd.DataFrame(np.arange(0,16).reshape(4,4), columns=list('abcd')) ''' a b c d 0 0 1 2 3 1 4 5 6 7 2 8 9 10 11 3 12 13 14 15 ''' data2 = [[4,1,5,7],[6,5,7,1],[9,9,123,129],[16,16,32,1]] data2 = pd.DataFrame(data2,columns = ['a','b','c','d']) ''' a b c d 0 4 1 5 7 1 6 5 7 1 2 9 9 123 129 3 16 16 32 1 '''
(1)内连接,pd.merge(a1, a2, on='key')
pd.merge(data1,data2,on='b') #内连接 ,也就是交集
| a_x | b | c_x | d_x | a_y | c_y | d_y | |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 | 4 | 5 | 7 |
| 1 | 4 | 5 | 6 | 7 | 6 | 7 | 1 |
| 2 | 8 | 9 | 10 | 11 | 9 | 123 | 129 |
(2)左连接,pd.merge(a1, a2, on='key', how='left')
pd.merge(data1,data2,on='b',how='left') #左连接 ,没有值的标记为空
| a_x | b | c_x | d_x | a_y | c_y | d_y | |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 | 4.0 | 5.0 | 7.0 |
| 1 | 4 | 5 | 6 | 7 | 6.0 | 7.0 | 1.0 |
| 2 | 8 | 9 | 10 | 11 | 9.0 | 123.0 | 129.0 |
| 3 | 12 | 13 | 14 | 15 | NaN | NaN | NaN |
(3)右连接,pd.merge(a1, a2, on='key', how='right')
pd.merge(data1,data2,on='b',how='right') #右连接 ,没有值的标记为空
| a_x | b | c_x | d_x | a_y | c_y | d_y | |
|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 1 | 2.0 | 3.0 | 4 | 5 | 7 |
| 1 | 4.0 | 5 | 6.0 | 7.0 | 6 | 7 | 1 |
| 2 | 8.0 | 9 | 10.0 | 11.0 | 9 | 123 | 129 |
| 3 | NaN | 16 | NaN | NaN | 16 | 32 | 1 |
(4)外连接, pd.merge(a1, a2, on='key', how='outer')
pd.merge(data1,data2,on='b',how='outer') #外连接 ,求同存异
| a_x | b | c_x | d_x | a_y | c_y | d_y | |
|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 1 | 2.0 | 3.0 | 4.0 | 5.0 | 7.0 |
| 1 | 4.0 | 5 | 6.0 | 7.0 | 6.0 | 7.0 | 1.0 |
| 2 | 8.0 | 9 | 10.0 | 11.0 | 9.0 | 123.0 | 129.0 |
| 3 | 12.0 | 13 | 14.0 | 15.0 | NaN | NaN | NaN |
| 4 | NaN | 16 | NaN | NaN | 16.0 | 32.0 | 1.0 |
2.append 类似于union all
也是上下连接
#ignore_index = True:这个时候 表示index重新记性排列
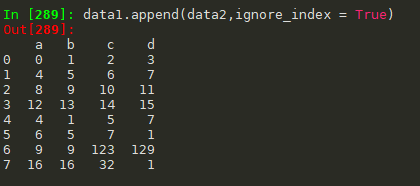
data1.append(data2,ignore_index = True)
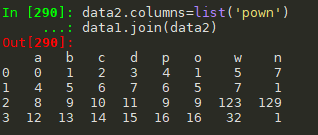
3.join列名不能重复,类似于在将第二个数据拼接在右边
data2.columns=list('pown')
data1.join(data2)
4.concat
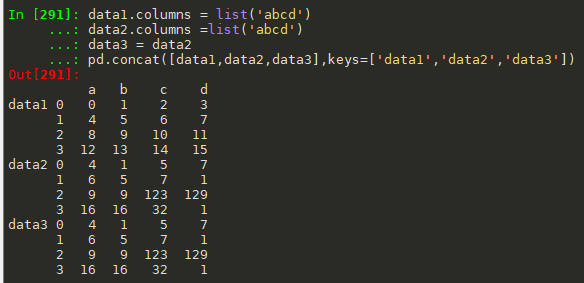
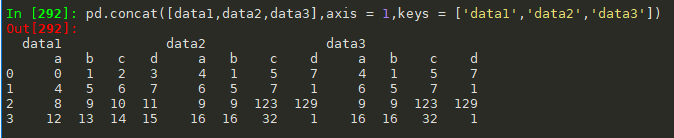
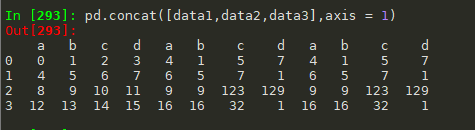
#pd.concat(objs, axis=0, join='outer', join_axes=None,ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False) #参数说明:objs:series,dataframe,或者panel构成的序列list,axis:0 行,1列,join:inner,outer data1.columns = list('abcd') data2.columns =list('abcd') data3 = data2 pd.concat([data1,data2,data3],keys=['data1','data2','data3']) pd.concat([data1,data2,data3],axis = 1,keys = ['data1','data2','data3']) pd.concat([data1,data2,data3],axis = 1)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号