
天池_短租数据分析
数据源:https://tianchi.aliyun.com/competition/entrance/231715/information
导入模块
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline plt.rc("font",family="SimHei",size="12") #解决中文无法显示的问题
导入数据
#导入数据 listings=pd.read_csv('F:\\python\\天池_短租数据分析\\listings.csv')
简单的数据查看
listings.info() listings.head(5) listings.shape listings.describe()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 28452 entries, 0 to 28451 Data columns (total 16 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 id 28452 non-null int64 1 name 28451 non-null object 2 host_id 28452 non-null int64 3 host_name 28452 non-null object 4 neighbourhood_group 0 non-null float64 5 neighbourhood 28452 non-null object 6 latitude 28452 non-null float64 7 longitude 28452 non-null float64 8 room_type 28452 non-null object 9 price 28452 non-null int64 10 minimum_nights 28452 non-null int64 11 number_of_reviews 28452 non-null int64 12 last_review 17294 non-null object 13 reviews_per_month 17294 non-null float64 14 calculated_host_listings_count 28452 non-null int64 15 availability_365 28452 non-null int64 dtypes: float64(4), int64(7), object(5) memory usage: 3.5+ MB
数据情况如上面截图,主要是有关可租房屋的信息,字段含义和英文含义基本一致,主要包括:房东ID、房东姓名、所属行政区、经纬度、房间类型、价格、最小可租天数、评论数量、最后一次评论时间、每月评论占比、可出租房屋、每年可出租时长等
查看数据缺失情况
#数据缺失计算 missing=listings.isnull().sum() missing[missing>0].plot.bar()
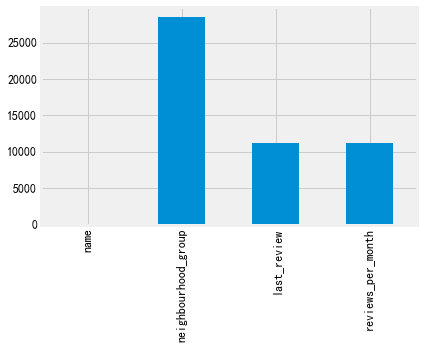
缺失比例
#数据缺失比例计算 missing=listings.isnull().sum()/len(listings) missing[missing>0].plot.bar()
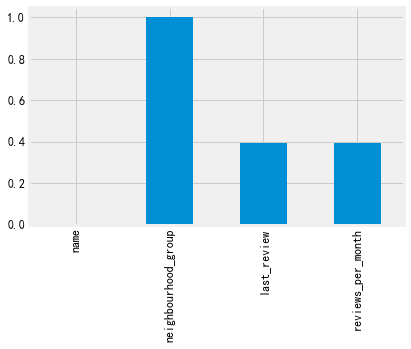
可以看出来,一共有四个字段有缺失,其中有一个字段缺失特别严重,缺失比例达到了100%,可以删除,还有2个缺失40%左右,也可以考虑将此删除
区分数据特征个类别特征
#数据特征 numeric_features = listings.select_dtypes(include=[np.number]) numeric_features.columns #类别特征 categorical_features = listings.select_dtypes(include=[np.object]) categorical_features.columns
类别特征
查看类别特征的值的个数
for cat_fea in categorical_features: print(cat_fea + "的特征分布如下:") print("{}特征有个{}不同的值".format(cat_fea, listings[cat_fea].nunique())) print(listings[cat_fea].value_counts())
类别特征['name', 'host_name', 'neighbourhood', 'room_type', 'last_review']
只保留neighbourhood,'/'前面的值
#使用str.split,记住不要忘记.str,不然会出错 listings['neighbourhood']=listings['neighbourhood'].str.split('/').str[0]
原来是这样:
0 朝阳区 / Chaoyang 1 密云县 / Miyun 2 东城区 3 东城区 4 朝阳区 / Chaoyang Name: neighbourhood, dtype: object
现在是这样:
0 朝阳区 1 密云县 2 东城区 3 东城区 4 朝阳区 Name: neighbourhood, dtype: object
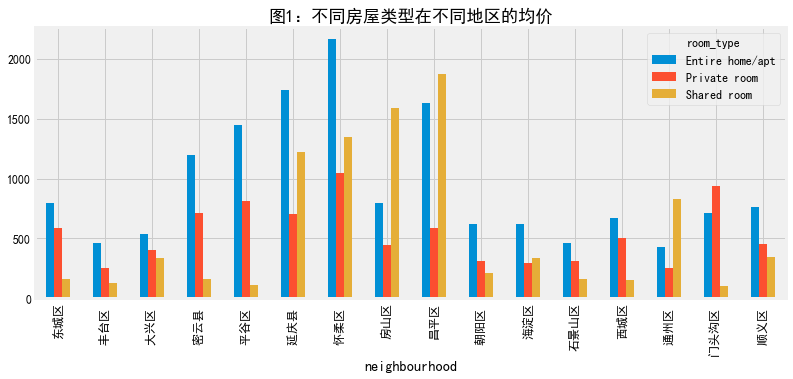
分析neighbourhood和room_type对和price的关系
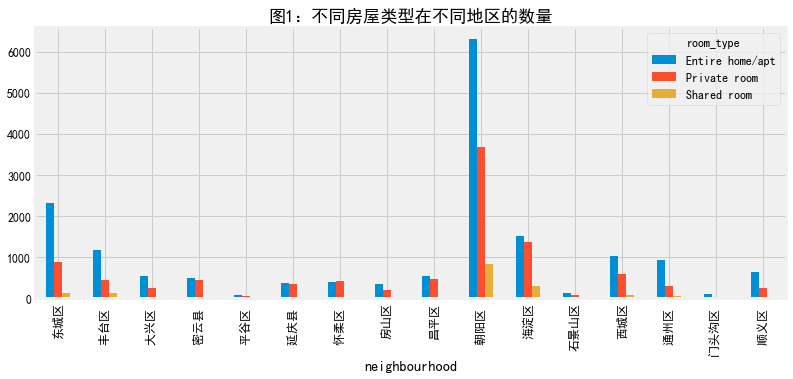
#按照neighbourhood和room_type分组,计算每个值的个数和price的均值 neigh_roomtype=listings.groupby(['neighbourhood','room_type']).agg({'id':'size','price':'mean'}) #将ID改为number neigh_roomtype=neigh_roomtype.rename(columns={'id':'number'}) #先对number计算统计可视化等 number_n_r=neigh_roomtype.unstack()['number'] number_n_r.plot(figsize=(12,5),title='图1:不同房屋类型在不同地区的数量')

画条形图
#条形图 number_n_r.plot.bar(figsize=(12,5),title='图1:不同房屋类型在不同地区的数量')
画饼图
#画饼图(sum(1)是按行求和) number_n_r.sum(1).sort_values().plot.pie(figsize=(6,6),autopct='%.2f%%',title='图2:房屋地区占比')

#画饼图(按列求和) number_n_r.sum(0).sort_values().plot.pie(figsize=(6,6),autopct='%.2f%%',title='图3:房屋类型占比')
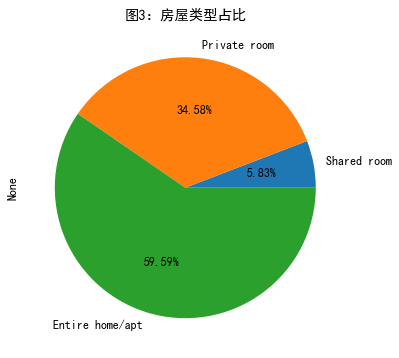
不同区域不同房子类型的均价
#先对price计算统计可视化等 price_r=neigh_roomtype.unstack()['price'] price_r.plot.bar(figsize=(12,5),title='图1:不同房屋类型在不同地区的均价') #先对price计算统计可视化等 price_r=neigh_roomtype.unstack()['price'] price_r.plot(figsize=(12,5),title='图1:不同房屋类型在不同地区的均价')
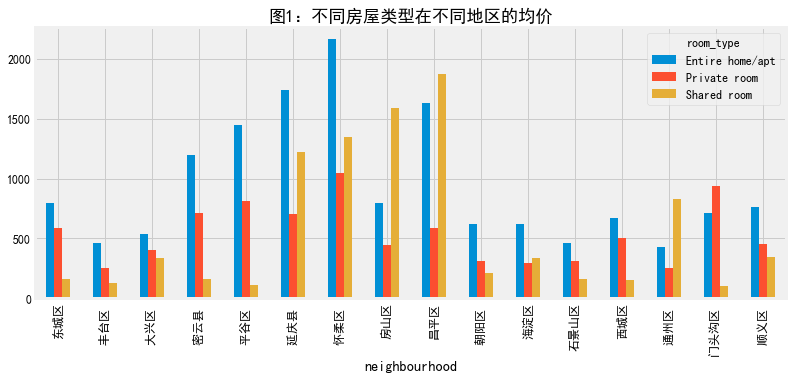
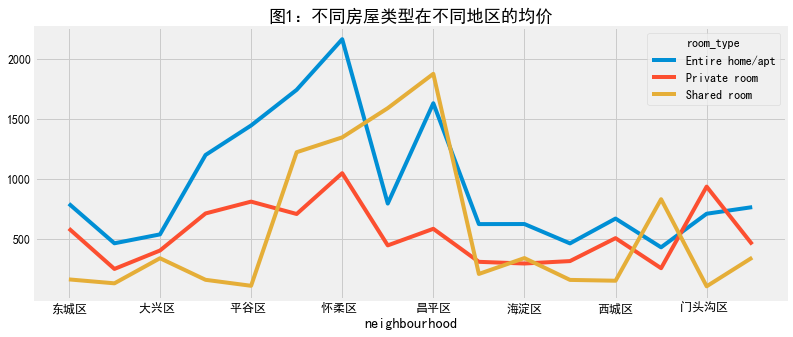
计算不同房源均价
#计不同地区均价 listings.groupby('neighbourhood')['price'].mean().sort_values().plot.bar(figsize=(8,8),title='图4:不同地区房源均价')
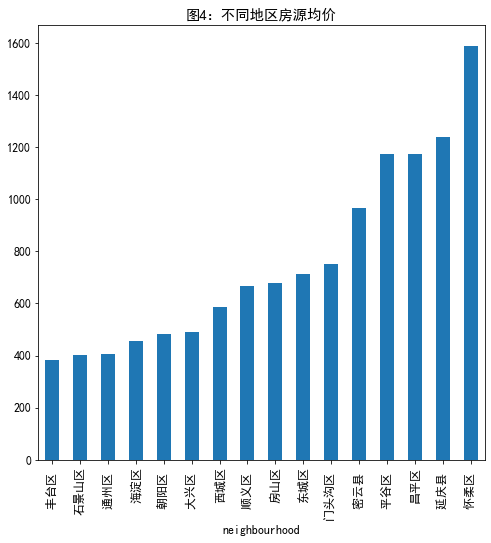
不能是这样,因为这样没有考虑个数,直接使用三个值平均,这种做法是错误了
price_r.mean(1).sort_values().plot.bar(figsize=(6,6),title='图2:房屋地区占比')
计算不同房屋类型均价
#不同房屋类型均价 listings.groupby('room_type')['price'].mean().sort_values().plot.bar(figsize=(8,8),title='图5:不同房屋类型均价')
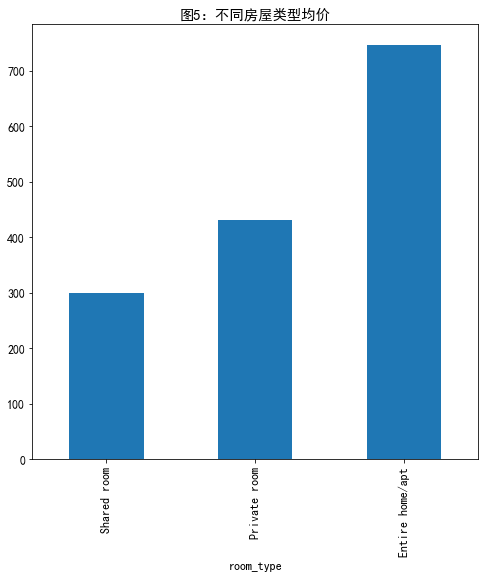
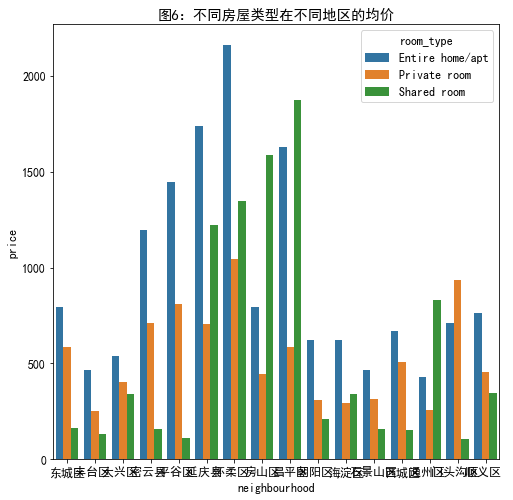
不同房源地区不同房屋类型均价
#不同房源地区和房子类型均价 n_r_data=listings.groupby(['neighbourhood','room_type'])['price'].mean() plt.figure(figsize=(8,8)) plt.title('图6:不同房屋类型在不同地区的均价') sns.barplot(x='neighbourhood',y='price',hue='room_type',data=n_r_data.reset_index()) #或者是这样子 #先对price计算统计可视化等 price_r=neigh_roomtype.unstack()['price'] price_r.plot.bar(figsize=(12,5),title='图1:不同房屋类型在不同地区的均价')
查看name 和host_name
listings[['name', 'host_name']].head()

房东名字应该是没有什么信息的,可以考虑去掉,name可以从中提取一些特征
查看最后last_review
listings['last_review'].head()
0 2019-03-04 1 2017-10-08 2 2019-02-05 3 2016-12-03 4 2018-08-01 Name: last_review, dtype: object
可以构造一些有用的特征
数值特征
查看数值特征的值的分布,连续还是离散的
''' Index(['id', 'host_id', 'neighbourhood_group', 'latitude', 'longitude', 'price', 'minimum_nights', 'number_of_reviews', 'reviews_per_month', 'calculated_host_listings_count', 'availability_365'], dtype='object') ''' for i in numeric_features.columns: print(i,listings[i].value_counts())
1.id和host_id是没有什么信息的可以删除
#可以先保留一下id ,然后再删除 id=listings['id'] listings=listings.drop(['id', 'host_id'],axis=1)
2.由于neighbourhood_group的值全部一样,都是空值,因此将此删除
listings=listings.drop('neighbourhood_group',axis=1)
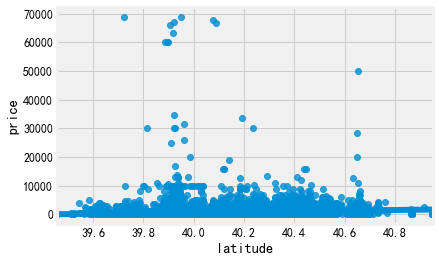
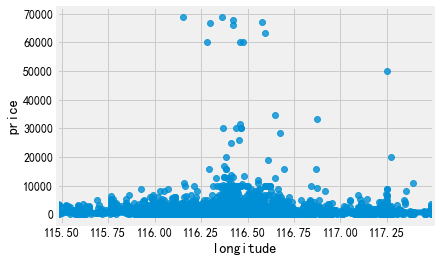
3.经纬度,可能和房源区域强相关
sns.regplot('latitude','price',data=listings) sns.regplot('longitude','price',data=listings)
4.最小可租天数
sns.regplot('minimum_nights','price',data=listings)
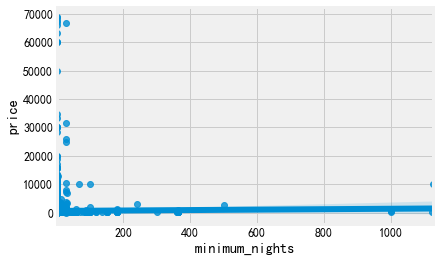
sns.boxplot('minimum_nights',data=listings)

这肯定有异常值了,而且一般不都是最小入住天数是1天吗
#看的出来最小入住天数是1晚,还有30天这个值还挺多的有609个,应该是月租 listings['minimum_nights'].value_counts().sort_index()
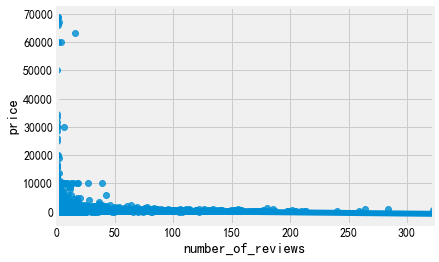
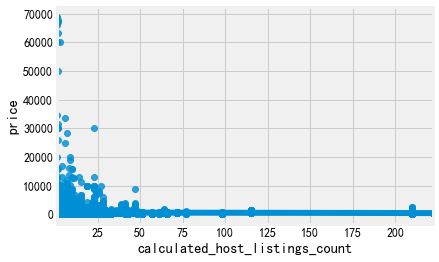
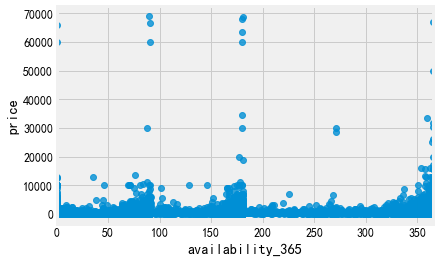
5.评论数量、最后一次评论时间(单独拿出来)、每月评论占比、可出租房屋、每年可出租时长
for i in ['number_of_reviews', 'calculated_host_listings_count', 'availability_365']: sns.regplot(i,'price',data=listings) plt.show()
目标变量price
sns.boxplot(listings['price']) sns.distplot(listings['price'])

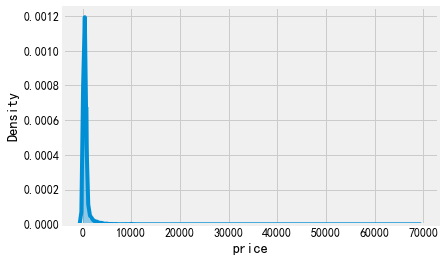
大于10000的值影响太大了,可以只画10000以下的
sns.distplot(listings[listings['price']<=10000]['price'])
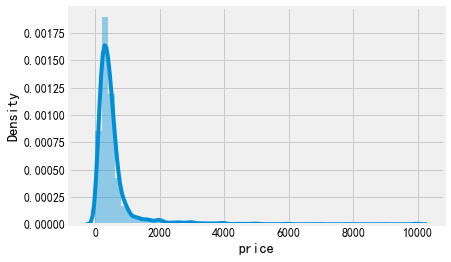
查看一下描述性
listings['price'].describe()
count 28452.000000 mean 611.203325 std 1623.535077 min 0.000000 25% 235.000000 50% 389.000000 75% 577.000000 max 68983.000000 Name: price, dtype: float64
再看一下1000以下的
sns.distplot(listings[listings['price']<=1000]['price'])
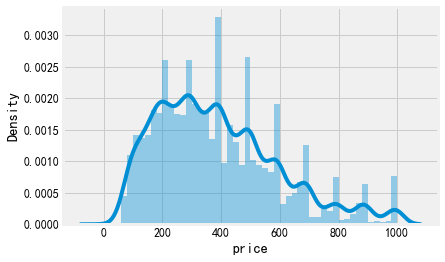
为什么会有0,好诡异,青年旅馆吗
listings['price'].value_counts().sort_index() #0 3
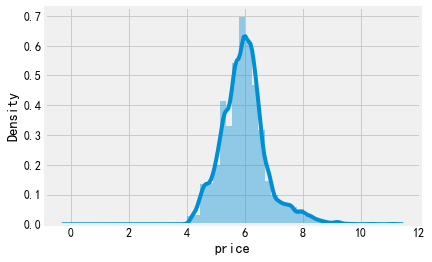
log一下
sns.distplot(np.log(listings['price']+1)) sns.distplot(np.log(listings[listings['price']<=1000]['price']+1))
特征工程
先复制一份数据,省得对原数据造成影响
train=listings.copy()
先对类别特征进行构造特征

 浙公网安备 33010602011771号
浙公网安备 33010602011771号