分库分表之ShardingSphere
分库分表诞生的前景#
随着系统用户运行时间还有用户数量越来越多,整个数据库某些表的体积急剧上升,导致CRUD的时候性能严重下降,还容易造成系统假死
这时候系统都会做一些基本的优化,比如加索引、缓存、读写分离/主从复制,增删改都走主库,查询走从库。但是这样没法提升主库写的能力,因为主库只有一个。这时候就要考虑分库分表了,一般数据库在设计的时候就会提前考虑到是否有分库分表场景需要,避免后期带来迁移的问题,而且最好对表的查询足够简单,尽量避免跨表跨库查询。
阿里的开发规范中建议预估三年内单表数据量上500W,或者大小上2G,就要考虑分库分表
分库分表的方式(垂直拆分,水平复制)#
一般系统模块都是访问同一个数据库资源,所有的表都存放在一个库里面
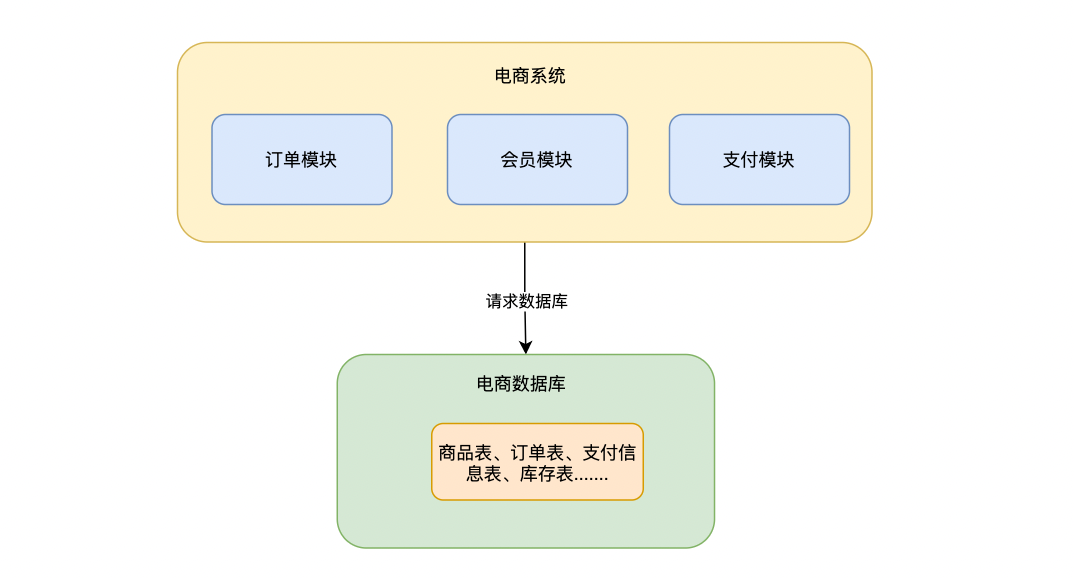
1.垂直拆分#
1.1 垂直分库
把单一的数据库进行业务划分,专库专表
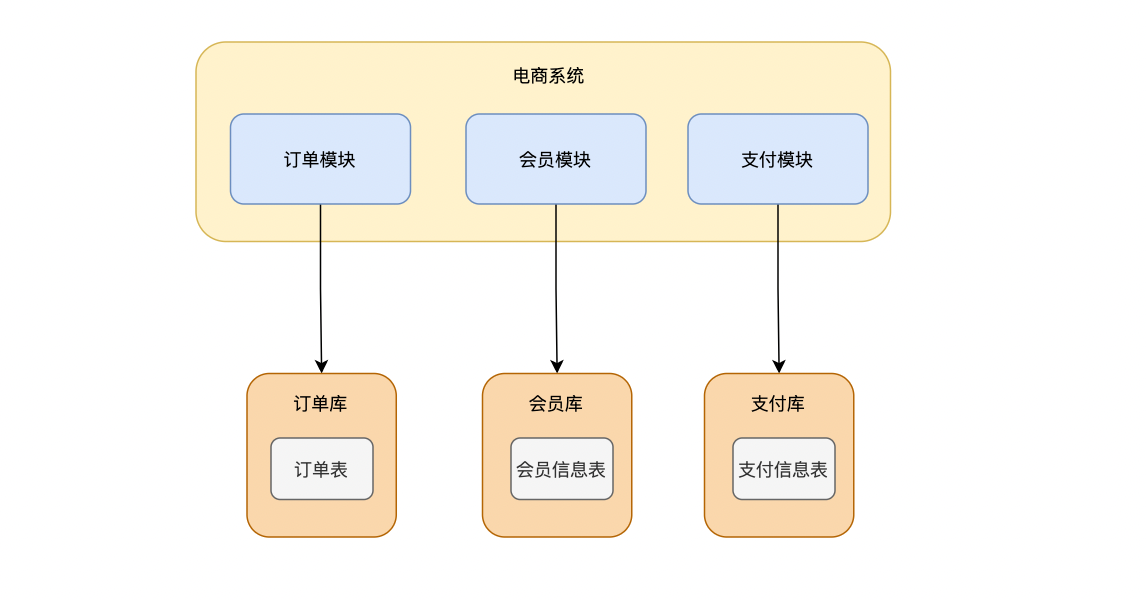
经过垂直拆分之后,每个模块都使用各自独立的数据库,减轻了数据库的压力,业务也更加清晰,拓展也更容易了,但是会增加连表查询以及事务处理的复杂度,无法解决单表数据量太大的问题
1.2 垂直分表
垂直拆分表主要解决一张表太多字段某个字段存储值为大文本会对io查询有损耗所以把本来属于同一个对象描述的属性拆分多个表,分布式微服务分库分表尽量不要严苛遵守数据库的3大范式,可参考不可严格遵循
相当于把一个大表根据字段拆分成多个小表 ,一个10w数据的表,变成两个10w数据的表
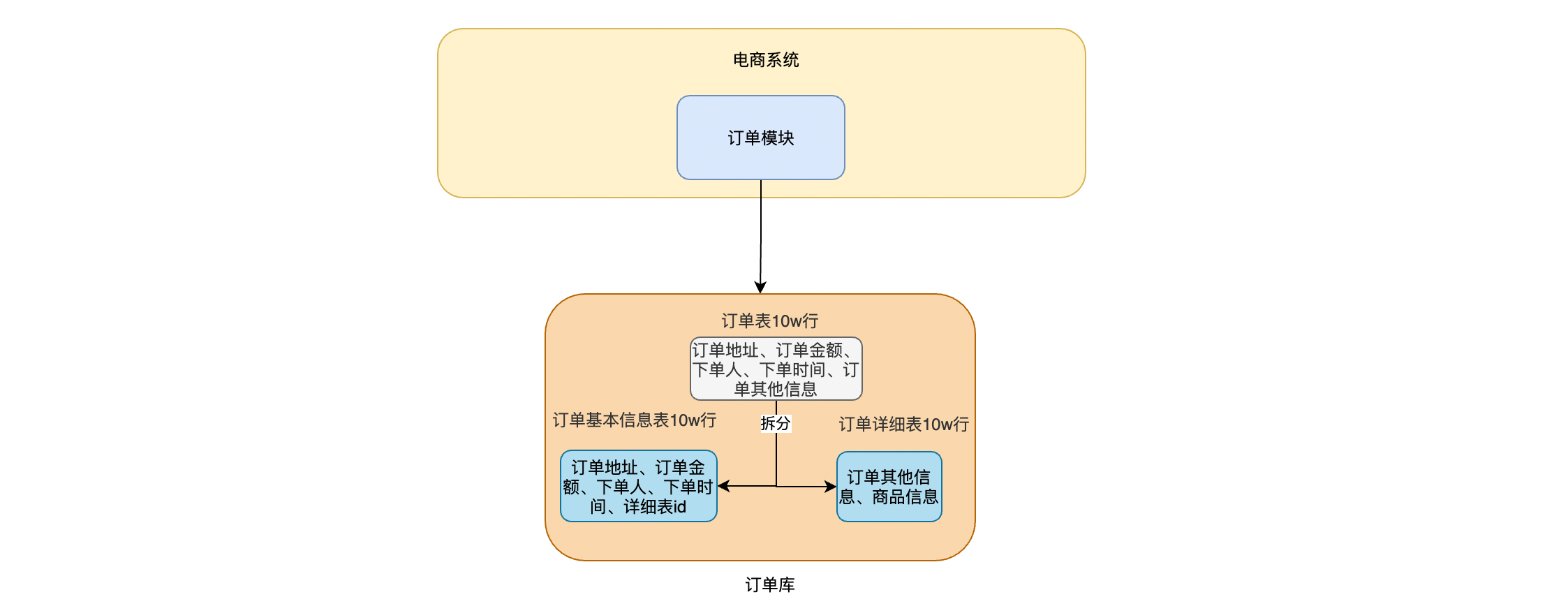
这样拆分的好处就是,假如只显示列表,不需要显示详细信息就很方便,例如一个订单是包含很多信息的,但是在后台通常不需要去获取订单的详情信息用作展示,一般只需要展示概要信息:下单用户、下单时间、金额等等重要信息。于是可以把一个订单表垂直拆分为两个表来处理
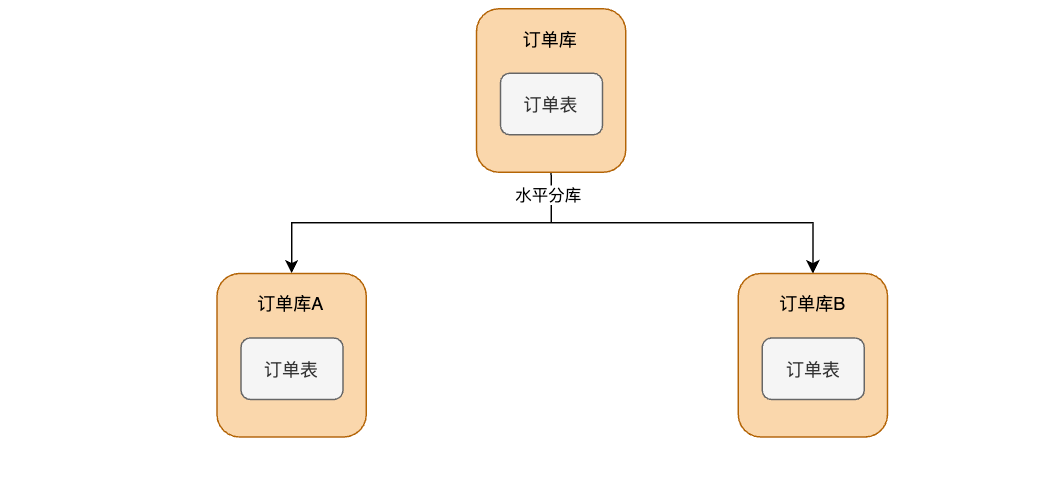
2.水平拆分#
2.1 水平分库
把一个数据库分散成多个结构相同的数据库,本质就是复制操作
2.2 水平分表
一个表数据量太大,将一个表按不同的条件分散多个表中,把1000w的表拆分为两个500w的表
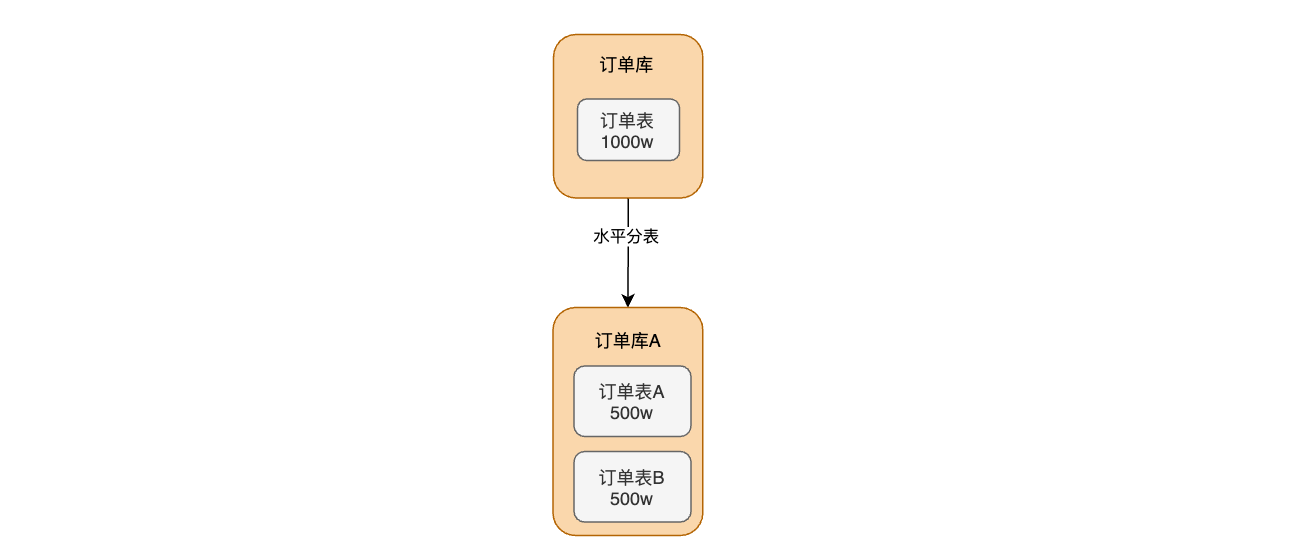
分表的规则有很多种:
-
取范围
根据时间范围或者id范围分布到不同的库中,例如把2020年前的数据放到一个表中,之后的数据放到一个表中。把用户ID 0~100000放到一个表中,100000~200000的数据放到一个表中。
优点:使用分片字段范围查询比较方便
缺点:某段范围内热点数据可能被频繁读写,其他数据很少被查询
-
数值hash取模运算
根据某个字段进行运算均匀的分配到不同的表中
优点:分散比较均匀,不容易存在热点数据
缺点:数据太分散,导致范围查询比较麻烦,需要查询分库之后再合并
水平拆分的时候会导致多库多表的联合查询难度变大,以及多数据源管理的问题
分库分库中间件#
ShardingSphere#
官网:https://shardingsphere.apache.org/
ShardingSphere是一个关系型数据库中间件,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成,主要提供数据库分片以及分布式事务
Sharding-JDBC
Sharding-JDBC简化分库分表之后数据相关操作,它一个轻量级的Java框架,是增强版的JDBC驱动,以jar包的形式提供引入非常简单,适用于很多ORM框架以及数据库连接池,Sharding-JDBC不做分库分表,主要做两个功能:数据分片和读写分离,简化分库分表后对数据的操作
实现水平分表
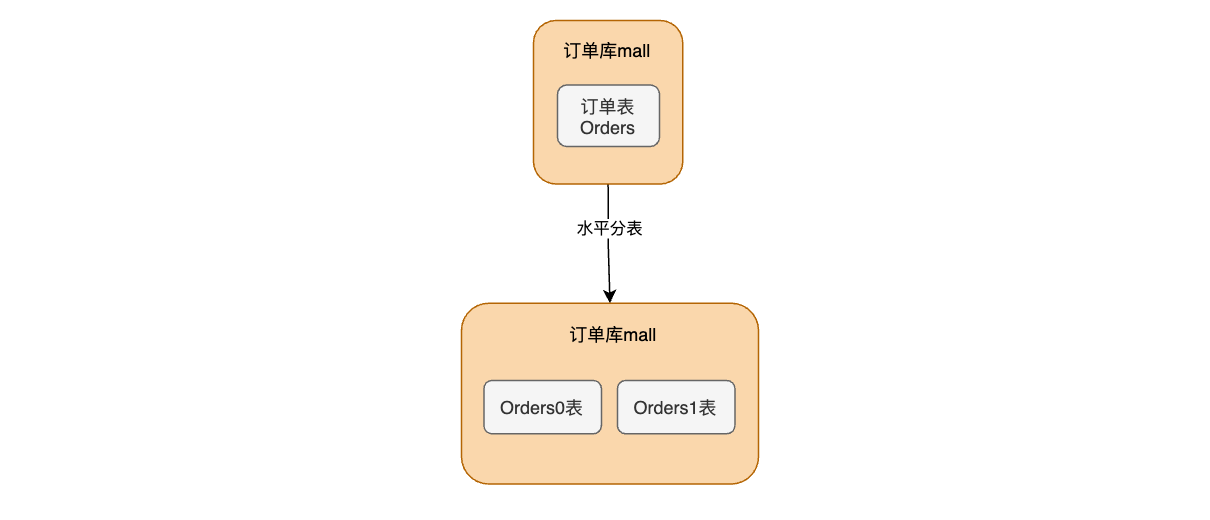
环境搭建:SpringBoot+mybatisPlus
1、首先创建一个springboot项目,引入相关依赖jar包
<!-- Sharding-JDBC -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<!-- Mysql驱动依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.29</version>
</dependency>
<!-- Druid连接池 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.8</version>
</dependency>
<!--mybatisPlus-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.1</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
2、创建数据库表结构
创建一个mall数据库,然后里面创建两张表分别为:order0、order1
CREATE DATABASE `mall`
CREATE TABLE `orders0` (
`id` bigint NOT NULL AUTO_INCREMENT,
`order_number` varchar(50) NOT NULL,
`create_time` date NOT NULL,
`creater` varchar(20) NOT NULL,
`money` decimal(10,0) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
CREATE TABLE `orders1` (
`id` bigint NOT NULL AUTO_INCREMENT,
`order_number` varchar(50) NOT NULL,
`create_time` date NOT NULL,
`creater` varchar(20) NOT NULL,
`money` decimal(10,0) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
3、约定分片规则
如果订单号order_number为奇数添加到orders0,否则添加到orders1
4、建立相关实体类、DAO
/**
* @author yanglingcong
*/
@Data
public class Orders implements Serializable {
private Long id;
private String orderNumber;
private Timestamp createTime;
private String creater;
private double money;
}
OrderDao
/**
* @author yanglingcong
*/
@Mapper
public interface OrderDao extends BaseMapper<Orders> {
}
5、配置分片策略以及数据源
application.properties
server.port=8099
spring.application.name=sharding-jdbc-demo
spring.profiles.active=dev
#指定数据库连接信息
spring.shardingsphere.datasource.names=db0
spring.shardingsphere.datasource.db0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.db0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.db0.url=jdbc:mysql://xxx:3306/mall?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.db0.username=root
spring.shardingsphere.datasource.db0.password=xxx
# 一个实体类对应两张表,覆盖
spring.main.allow-bean-definition-overriding=true
#指定主键id列的生成策略 SNOWFLAKE表示雪花
spring.shardingsphere.sharding.tables.orders.key-generator.column=id
spring.shardingsphere.sharding.tables.orders.key-generator.type=SNOWFLAKE
#指定表的分布 order数据库的order1和order2表
spring.shardingsphere.sharding.tables.orders.actual-data-nodes=db0.orders$->{0..1}
#指定分片策略 约定根据订单号order_number分片 奇数添加到`order1`,否则添加到`order2` 表索引从1开始的,所以加上1
spring.shardingsphere.sharding.tables.orders.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.orders.table-strategy.inline.algorithm-expression=orders$->{id % 2}
#sql输出日志
spring.shardingsphere.props.sql.show=true
6、测试生成
@RunWith(SpringRunner.class)
@SpringBootTest
public class ShardingJdbcDemoApplicationTests {
@Autowired
OrderDao orderDao;
@Test
void insertTest() {
for (int i = 0; i < 1; i++) {
Orders order=new Orders();
order.setCreater("ylc");
order.setOrderNumber("6");
order.setCreateTime(new Timestamp(System.currentTimeMillis()));
order.setMoney(30.01);
orderDao.insert(order);
}
}
@Test
void selectTest(){
QueryWrapper<Orders> queryWrapper=new QueryWrapper<>();
queryWrapper.eq("id",1553218859002007553L);
Orders orders = orderDao.selectOne(queryWrapper);
System.out.println(orders);
}
}
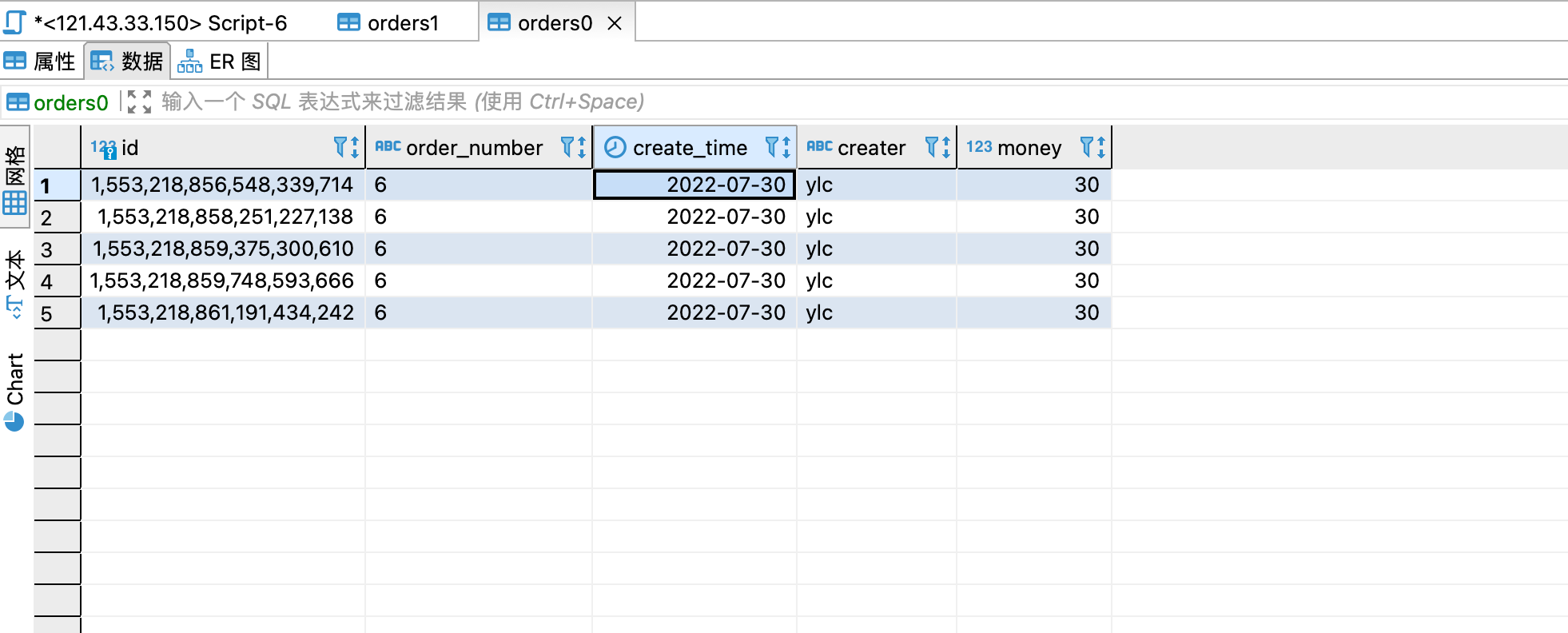
最后根据生成的雪花id插入到了数据库中
查询也会根据雪花id找到对应的表
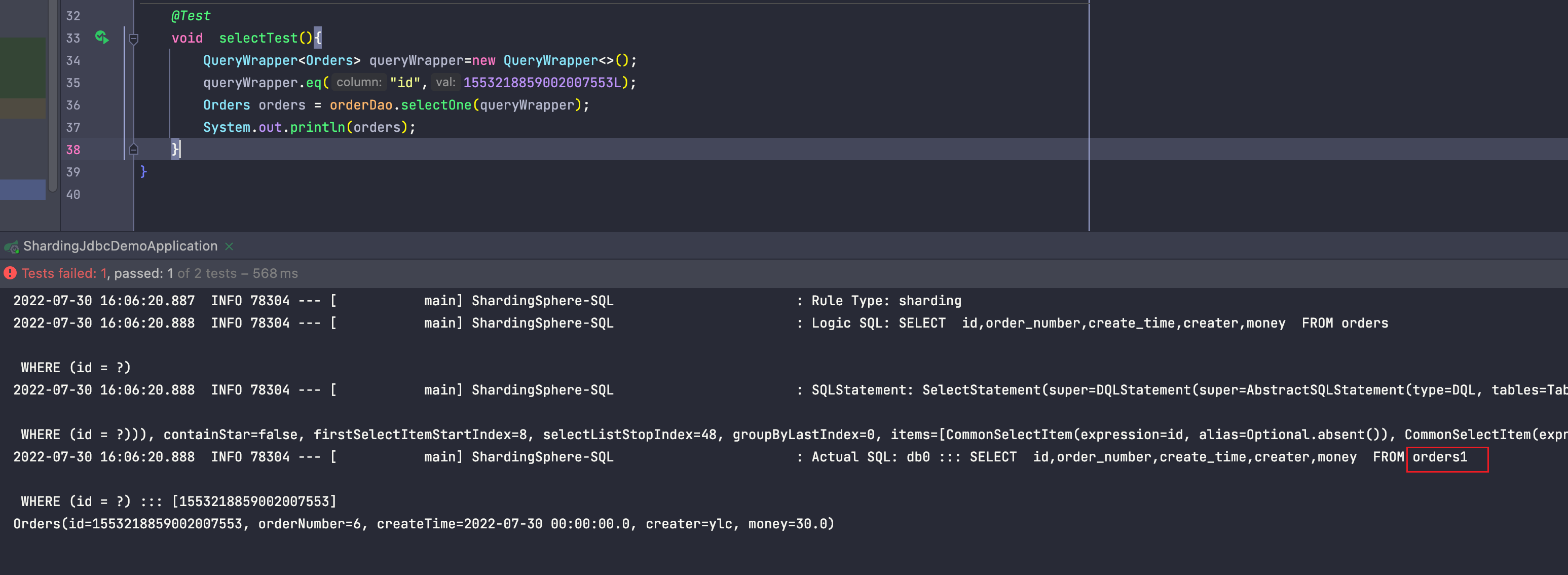
sharding-jdbc水平分表就是提前做好分表,然后配置分表规则,就可以让数据插入在不同的表中了,这里只是指定了一个数据源,还可以指定多个数据源
实现水平分库
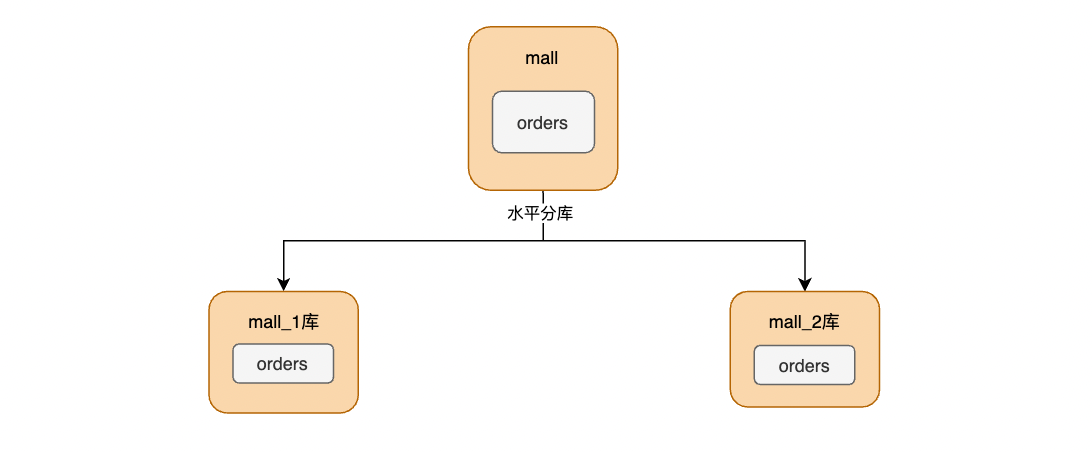
水平分库规则为:根据表里面的订单号字段orderNumber,奇数就路由到mall_1库,偶数路由到mall_2库
1、更改配置文件
server.port=8099
spring.application.name=sharding-jdbc-demo
spring.profiles.active=dev
spring.shardingsphere.sharding.default-data-source-name=db1
#指定数据库连接信息
spring.shardingsphere.datasource.names=db1,db2
spring.shardingsphere.datasource.db1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.db1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.db1.url=jdbc:mysql://xxx:3306/mall_1?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.db1.username=root
spring.shardingsphere.datasource.db1.password=xxx
spring.shardingsphere.datasource.db2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.db2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.db2.url=jdbc:mysql://xxx:3306/mall_2?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.db2.username=root
spring.shardingsphere.datasource.db2.password=xxx
# 一个实体类对应两张表,覆盖
spring.main.allow-bean-definition-overriding=true
#指定主键id列的生成策略 SNOWFLAKE表示雪花
spring.shardingsphere.sharding.tables.orders.key-generator.column=id
spring.shardingsphere.sharding.tables.orders.key-generator.type=SNOWFLAKE
#指定库的分布
spring.shardingsphere.sharding.tables.orders.actual-data-nodes=db$->{1..2}.orders0
#指定数据库分表策略 根据order_number奇数就路由到mall_1库,偶数路由到mall_2库
spring.shardingsphere.sharding.tables.orders.database-strategy.inline.sharding-column=order_number
spring.shardingsphere.sharding.tables.orders.database-strategy.inline.algorithm-expression=db$->{order_number % 2+1}
#sql输出日志
spring.shardingsphere.props.sql.show=true
2、更改实体
/**
* @author yanglingcong
*/
@Data
public class Orders implements Serializable {
private Long id;
private long orderNumber;
private Timestamp createTime;
private String creater;
private double money;
}
3、sql脚本
CREATE DATABASE `mall_0`
CREATE TABLE `orders0` (
`id` bigint NOT NULL AUTO_INCREMENT,
`order_number` bigint NOT NULL,
`create_time` date NOT NULL,
`creater` varchar(20) NOT NULL,
`money` decimal(10,0) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
CREATE DATABASE `mall_1`
CREATE TABLE `orders0` (
`id` bigint NOT NULL AUTO_INCREMENT,
`order_number` bigint NOT NULL,
`create_time` date NOT NULL,
`creater` varchar(20) NOT NULL,
`money` decimal(10,0) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
4、插入数据
@Test
void insertTest() {
for (int i = 0; i < 3; i++) {
Orders order=new Orders();
order.setCreater("ylc");
order.setOrderNumber(i);
order.setCreateTime(new Timestamp(System.currentTimeMillis()));
order.setMoney(30.01);
orderDao.insert(order);
}
}
@Test
void selectTest(){
QueryWrapper<Orders> queryWrapper=new QueryWrapper<>();
queryWrapper.eq("order_number",1553314824824299522L);
Orders orders = orderDao.selectOne(queryWrapper);
System.out.println(orders);
}
很简单就实现了分库功能,分库分表就是把这两种方式结合到了一起
分库分表查询,分库分表字段为必传字段,否则不知道去哪个数据库哪张表去查询数据,所以根据非主键查询的不支持。
实现垂直分库
垂直分库相当于专库专表,可以使用多数据源来处理,也可以通过sharding-Jdbc
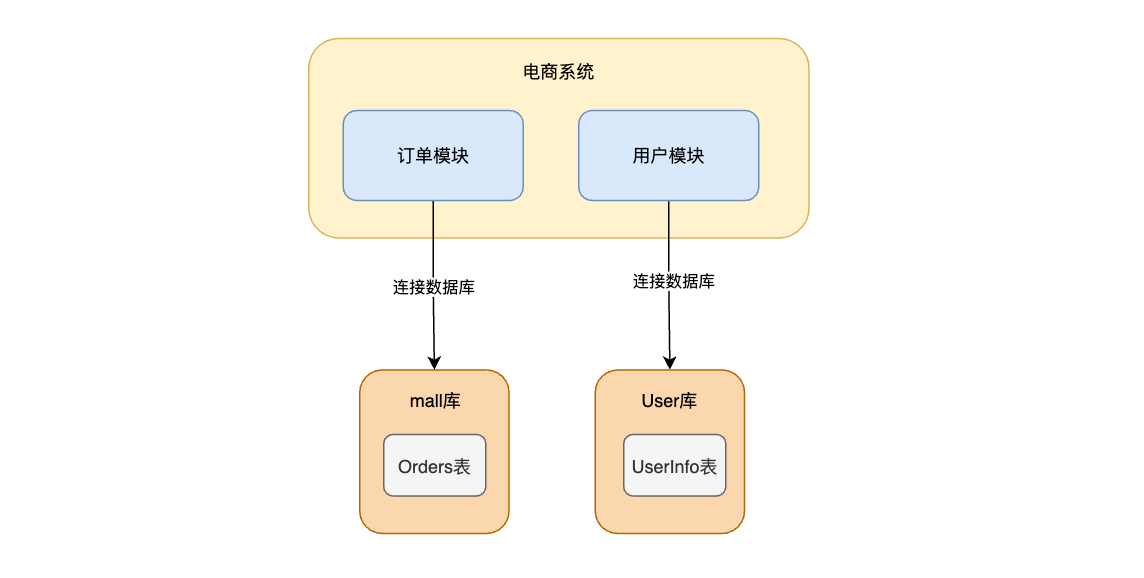
垂直分库的规则为:往订单表orders插入数据,会自动找到订单表所在的库mall进行操作。往用户表插入数据,会自动找到所在库User进行操作
1、数据库脚本
CREATE DATABASE `user`
CREATE TABLE `user`.userInfo (
id BIGINT auto_increment NOT NULL,
user_name varchar(20) NOT NULL,
password varchar(50) NOT NULL,
CONSTRAINT userinfo_PK PRIMARY KEY (id)
)
ENGINE=InnoDB
DEFAULT CHARSET=utf8mb4
COLLATE=utf8mb4_0900_ai_ci
AUTO_INCREMENT=1;
CREATE DATABASE `user`
CREATE DATABASE `mall`
CREATE TABLE `orders` (
`id` bigint NOT NULL AUTO_INCREMENT,
`order_number` bigint NOT NULL,
`create_time` date NOT NULL,
`creater` varchar(20) NOT NULL,
`money` decimal(10,0) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
2、创建相关实体类
UserInfo
@Data
public class UserInfo {
private Long id;
private String userName;
private String password;
}
Orders
@Data
public class Orders implements Serializable {
private Long id;
private long orderNumber;
private Timestamp createTime;
private String creater;
private double money;
}
3、Dao类
@Mapper
public interface UserInfoDao extends BaseMapper<UserInfo> {
}
4、配置垂直分库策略
server.port=8099
spring.application.name=sharding-jdbc-demo
spring.profiles.active=dev
spring.shardingsphere.sharding.default-data-source-name=db1
#指定数据库连接信息
spring.shardingsphere.datasource.names=db1,db2
spring.shardingsphere.datasource.db1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.db1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.db1.url=jdbc:mysql://xxx:3306/mall?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.db1.username=root
spring.shardingsphere.datasource.db1.password=xxx
spring.shardingsphere.datasource.db2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.db2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.db2.url=jdbc:mysql://xxx:3306/user?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.db2.username=root
spring.shardingsphere.datasource.db2.password=xxx
# 一个实体类对应两张表,覆盖
spring.main.allow-bean-definition-overriding=true
#指定主键id列的生成策略 SNOWFLAKE表示雪花
spring.shardingsphere.sharding.tables.orders.key-generator.column=id
spring.shardingsphere.sharding.tables.orders.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.userInfo.key-generator.column=id
spring.shardingsphere.sharding.tables.userInfo.key-generator.type=SNOWFLAKE
#指定orders表所在的库 userInfo表所在的库
spring.shardingsphere.sharding.tables.orders.actual-data-nodes=db1.orders
spring.shardingsphere.sharding.tables.userInfo.actual-data-nodes=db2.userInfo
#指定orders表分片策略
spring.shardingsphere.sharding.tables.orders.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.orders.table-strategy.inline.algorithm-expression=orders
#指定数userInfo分片策略
spring.shardingsphere.sharding.tables.userInfo.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.userInfo.table-strategy.inline.algorithm-expression=userInfo
#sql输出日志
spring.shardingsphere.props.sql.show=true
5、插入数据
Orders表在mall库
@Test
void insertOrdersTest() {
Orders order=new Orders();
order.setCreater("ylc");
order.setOrderNumber(1);
order.setCreateTime(new Timestamp(System.currentTimeMillis()));
order.setMoney(30.01);
orderDao.insert(order);
}

UserInfo表在user库
@Test
void insertUserTest() {
UserInfo userInfo=new UserInfo();
userInfo.setUserName("ylc");
userInfo.setPassword("123456");
userInfoDao.insert(userInfo);
}

这样就实现了不同的表插入了不同的数据库,不过使用多数据源方式会更方便
实现读写分离
环境配置:使用mall库为主库,mall_01、mall_02为从库,前提是MySQL数据库需要提前做好读写分离相关配置
1、读写分离配置
server.port=8099
spring.application.name=sharding-jdbc-demo
spring.profiles.active=dev
#指定数据库连接信息 一主两从
spring.shardingsphere.datasource.names=master,slave0,slave1
spring.shardingsphere.datasource.master.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.master.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.master.url=jdbc:mysql://xxx:3306/mall?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.master.username=root
spring.shardingsphere.datasource.master.password=xxx
spring.shardingsphere.datasource.slave0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.slave0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.slave0.url=jdbc:mysql://xxx:3306/mall_1?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.slave0.username=root
spring.shardingsphere.datasource.slave0.password=xxx
spring.shardingsphere.datasource.slave1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.slave1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.slave1.url=jdbc:mysql://xxx:3306/mall_2?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.slave1.username=root
spring.shardingsphere.datasource.slave1.password=xxx
# 配置从节点负载均衡策略,采用轮询机制
spring.shardingsphere.masterslave.load-balance-algorithm-type=round_robin
# 配置主从名称
spring.shardingsphere.masterslave.name=ms
# 配置数据源的读写分离
spring.shardingsphere.sharding.master-slave-rules.ds0.master-data-source-name=master
spring.shardingsphere.sharding.master-slave-rules.ds0.slave-data-source-names=slave0,slave1
#sql输出日志
spring.shardingsphere.props.sql.show=true
# 一个实体类对应两张表,覆盖
spring.main.allow-bean-definition-overriding=true
2、测试读
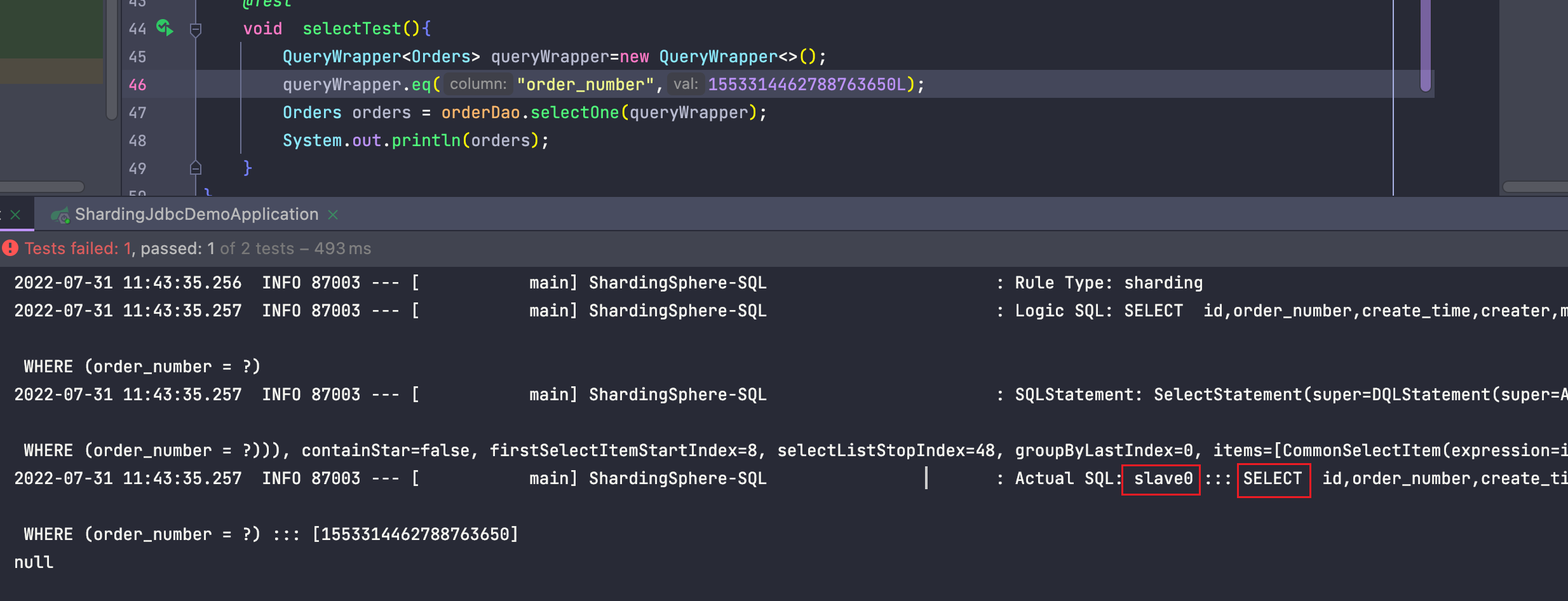
查找成功
3、测试写

写入主库成功,会自动同步到两个从库,然后查询的时候通过负载均衡轮询到一个子库进行查询
Sharding-Proxy
它是一个数据库的代理端,代理数据库我们只用访问它就行了,通过访问代理数据库来简化分库分表的操作
环境配置
1、安装包下载解压
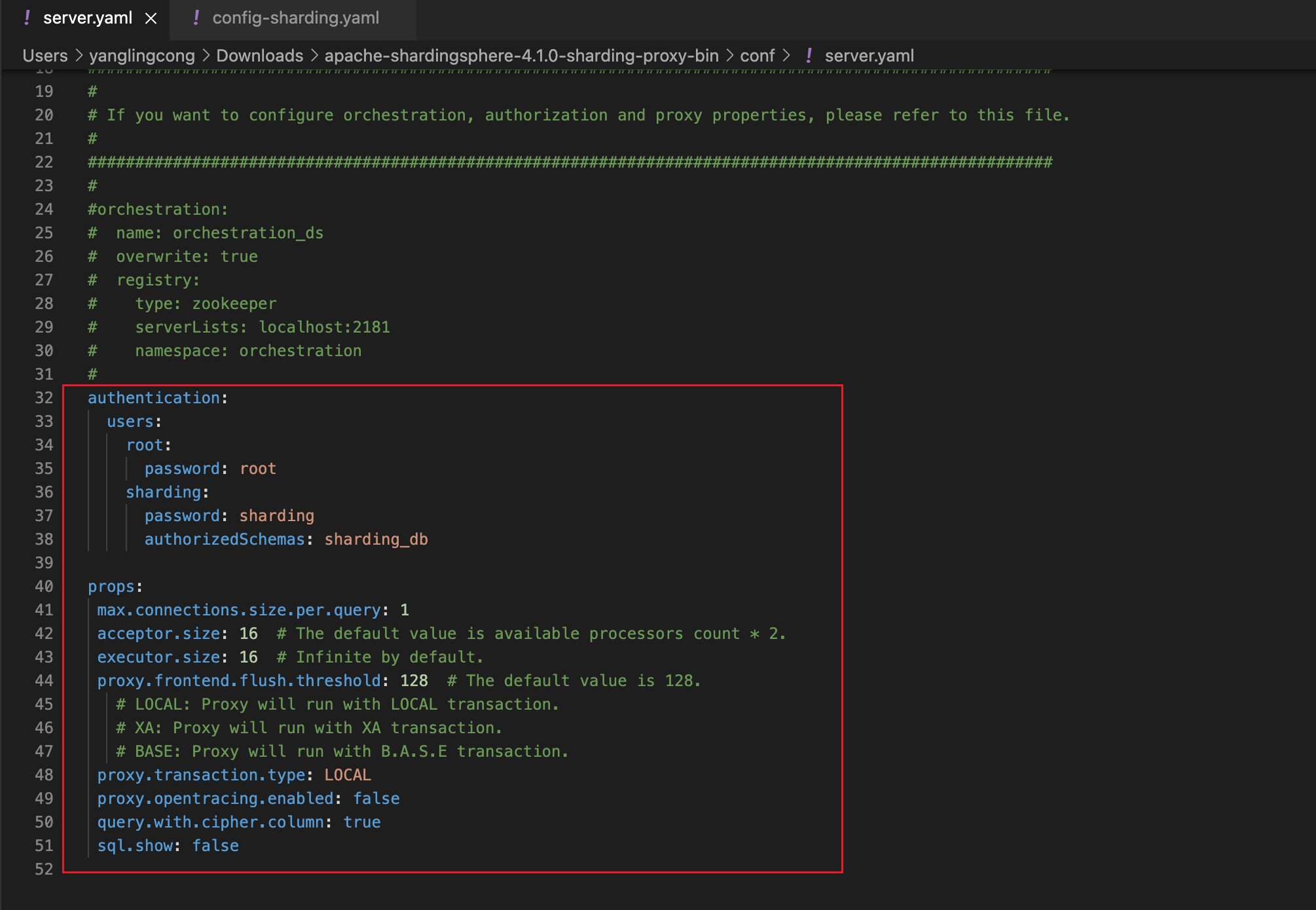
2、在conf目录下,修改server.yaml文件,去掉这一部分的注释
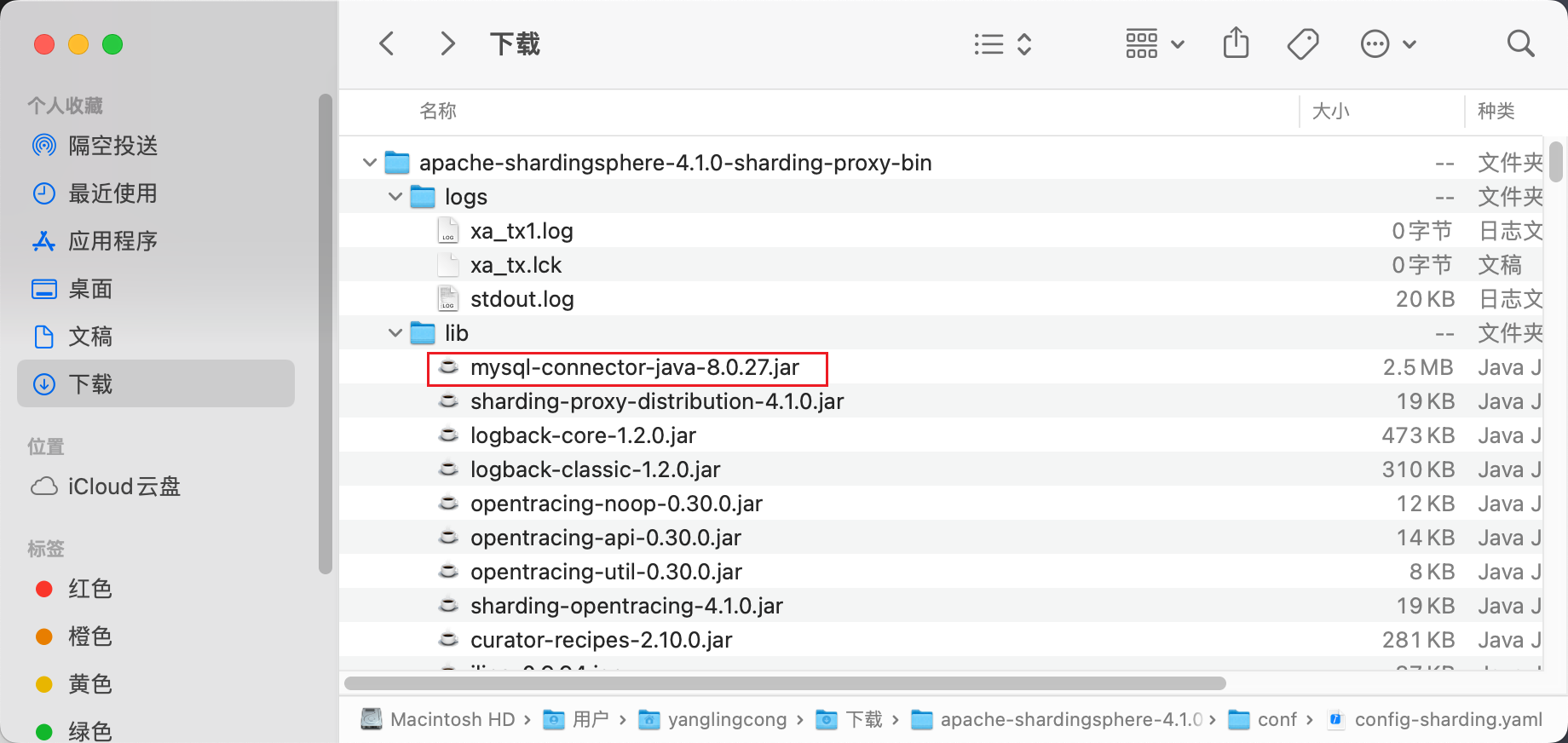
3、需要手动的把mysql驱动的jar包放到lib目录下否则程序无法运行
4、配置分库分表
修改config-sharding.yaml文件
schemaName: sharding_db
dataSources:
ds_0:
url: jdbc:mysql://121.43.33.150:3306/mall_1?serverTimezone=UTC&useSSL=false
username: root
password: xxx
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
ds_1:
url: jdbc:mysql://121.43.33.150:3306/mall_2?serverTimezone=UTC&useSSL=false
username: root
password: xxx
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
shardingRule:
tables:
#t_order表规则 可配置多个表
t_order:
actualDataNodes: ds_${0..1}.t_order_${0..1}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_${order_id % 2}
keyGenerator:
type: SNOWFLAKE
column: order_id
bindingTables:
- t_order
defaultDatabaseStrategy:
inline:
shardingColumn: order_number
algorithmExpression: ds_${order_number % 2}
defaultTableStrategy:
none:
5、启动Sharding-Proxy
执行bin目录下的start.sh文件
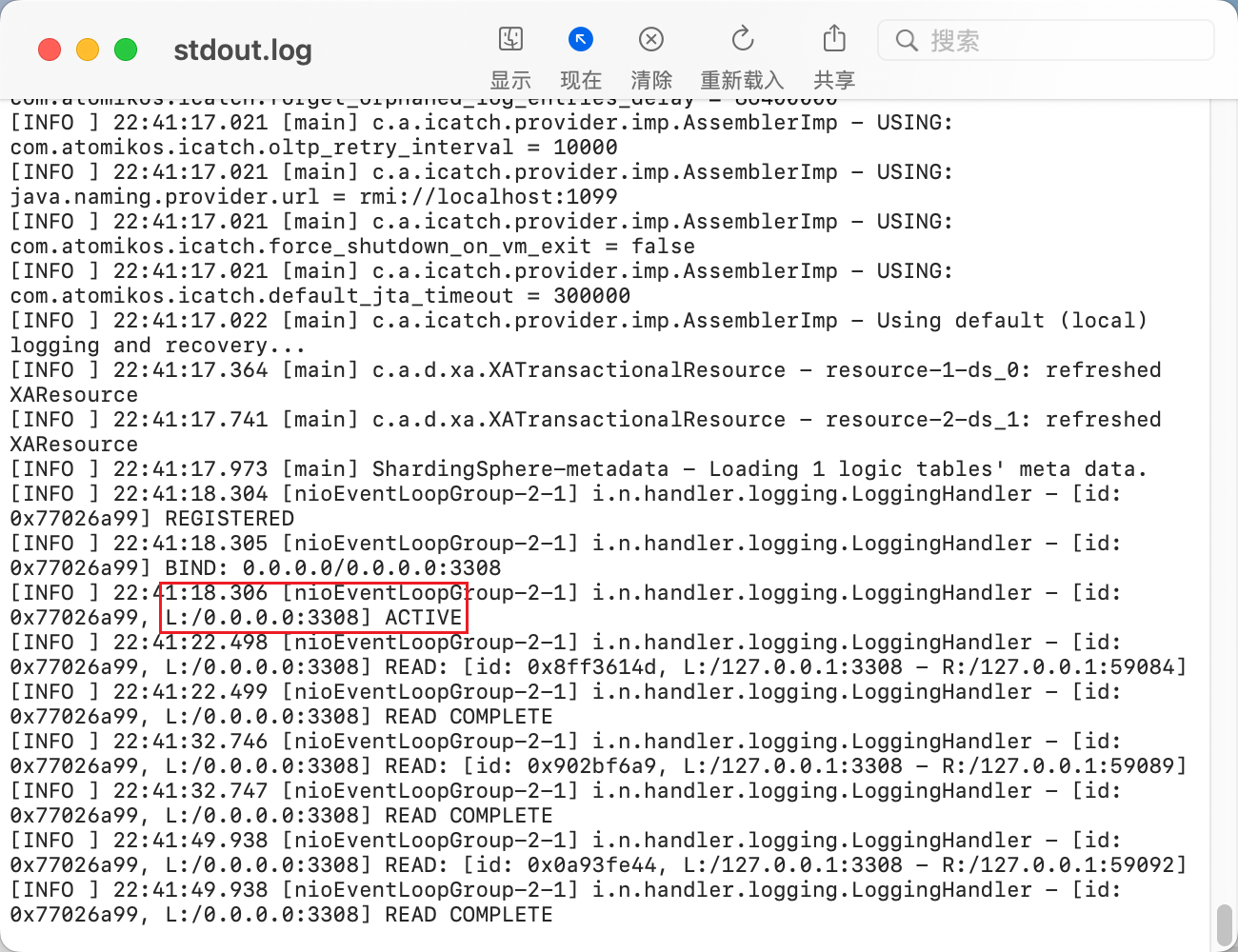
./start.sh 3308
显示Active表示成功了
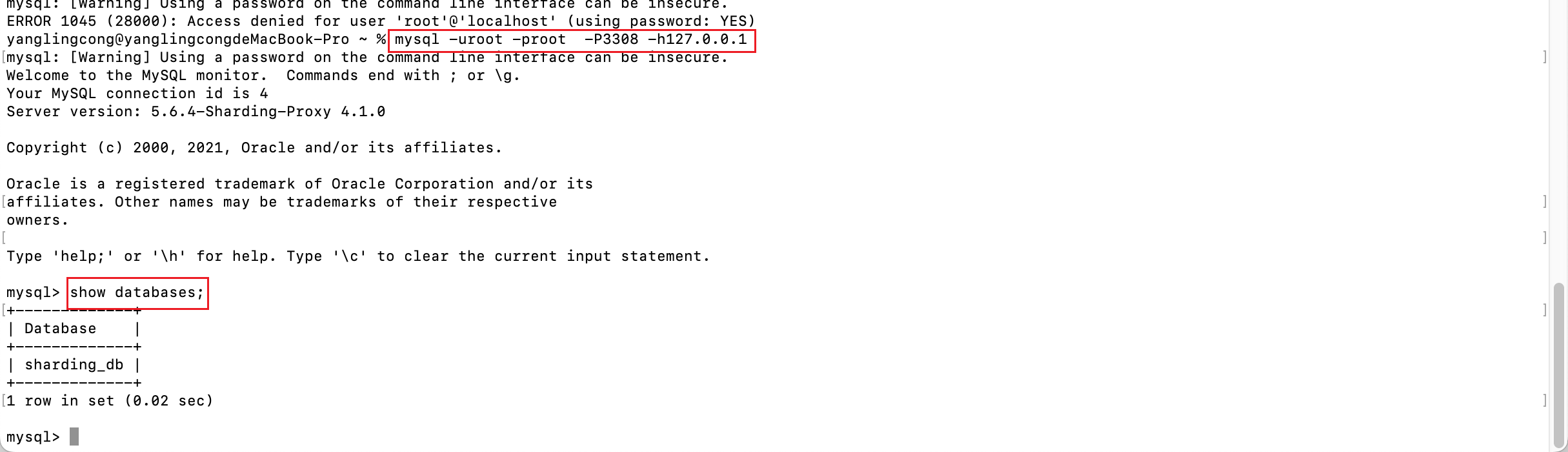
6、mysql登陆
mysql -uroot -proot -P3308 -h127.0.0.1
分库分表
配置规则
schemaName: sharding_db
dataSources:
ds_0:
url: jdbc:mysql://127.0.0.1:3306/lottery_01?serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
ds_1:
url: jdbc:mysql://127.0.0.1:3306/lottery_02?serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
shardingRule:
tables:
#t_order表规则 可配置多个表
t_order:
actualDataNodes: ds_${0..1}.t_order_${0..1}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_${order_id % 2}
keyGenerator:
type: SNOWFLAKE
column: order_id
bindingTables:
- t_order
defaultDatabaseStrategy:
inline:
shardingColumn: user_id
algorithmExpression: ds_${user_id % 2}
defaultTableStrategy:
none:
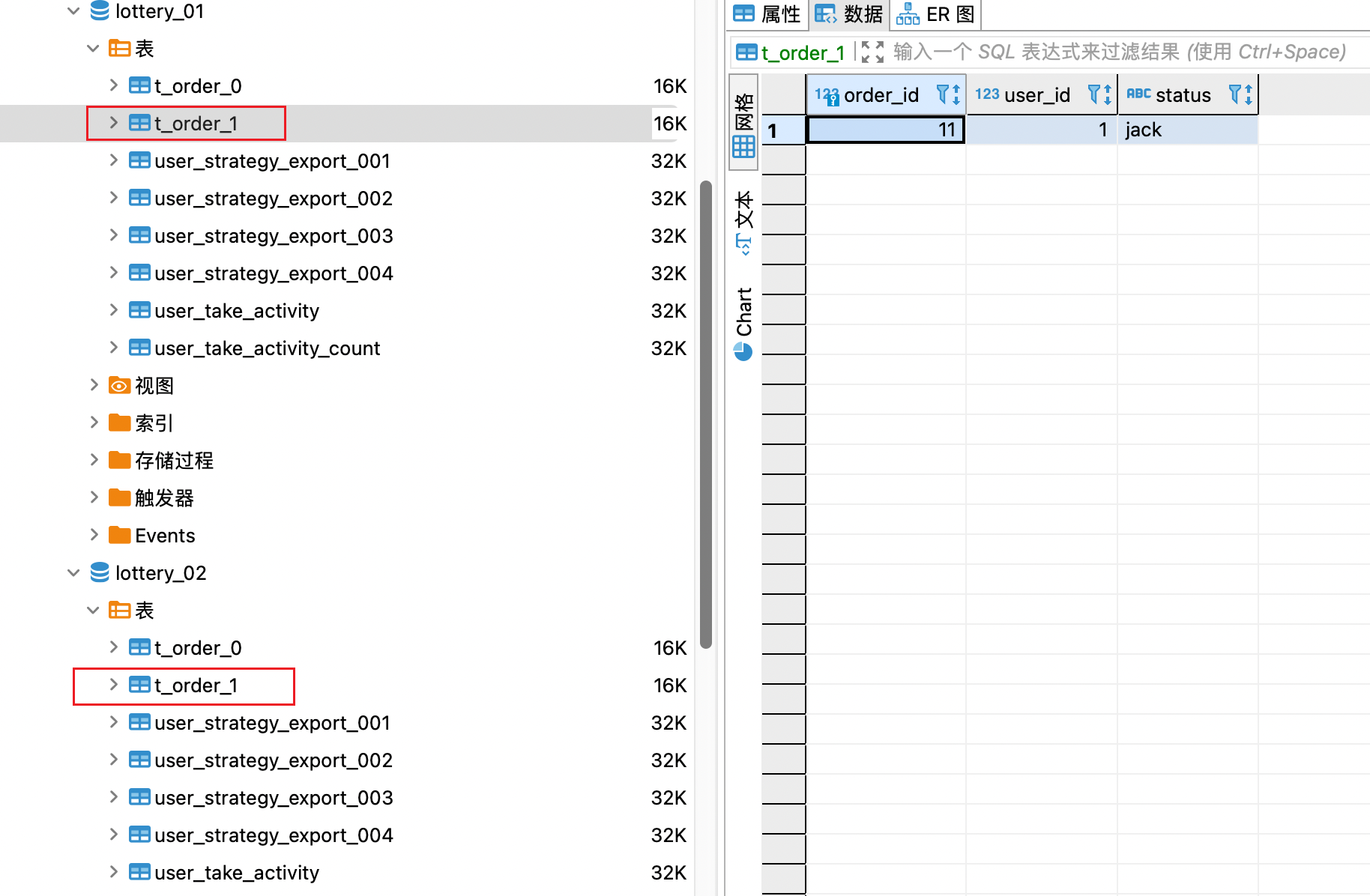
执行语句
use sharding_db;
create table if not exists ds_0.t_order(`order_id` bigint primary key,`user_id` int not null,`status` varchar(50));
insert into t_order(`order_id`,`user_id`,`status`)values(11,1,'jack');
根据插入的id进行运算,11为奇数分配到了t_order_1
读写分离
需要先在Mysql上面配置主从复制,读写分离比较简单,读从库lottery_02,写入主库同步到从库
1、配置规则
schemaName: sharding_db
dataSources:
master:
url: jdbc:mysql://127.0.0.1:3306/lottery_01?serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
save:
url: jdbc:mysql://127.0.0.1:3306/lottery_02?serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
masterSlaveRule:
name: ms_ds
masterDataSourceName: master
slaveDataSourceNames:
- save
2、重新启动
然后查询表t_order_1,这个表同时存在于主从库,最后查到了从库所在的记录行

两者区别
sharding-jdbc是在JDBC层扩展分库分表的,可以理解为增强版的JDBC驱动,支持JDBC协议的数据库的数据库,但目前仅支持Java语言,支持数据分片、读写分离,以 jar 包的形式提供轻量级服务,无proxy代理层,无需额外部署,无其他依赖,适用于Java开发的高性能的轻量级OLTP应用,中小团队
sharding-proxy是屏蔽了底层的分库分表像操作一个数据库一样来进行分库分表,代理了真实数据库,相当于在原有数据库和应用中增加了一层,sharding-proxy是基于 MySQL的,伪装成了MySQL数据库,可以通过DDL/DML等操作来变更数据,对DBA更加友好,适用于OLAP应用以及对分片数据库进行管理和运维的场景
实现原理
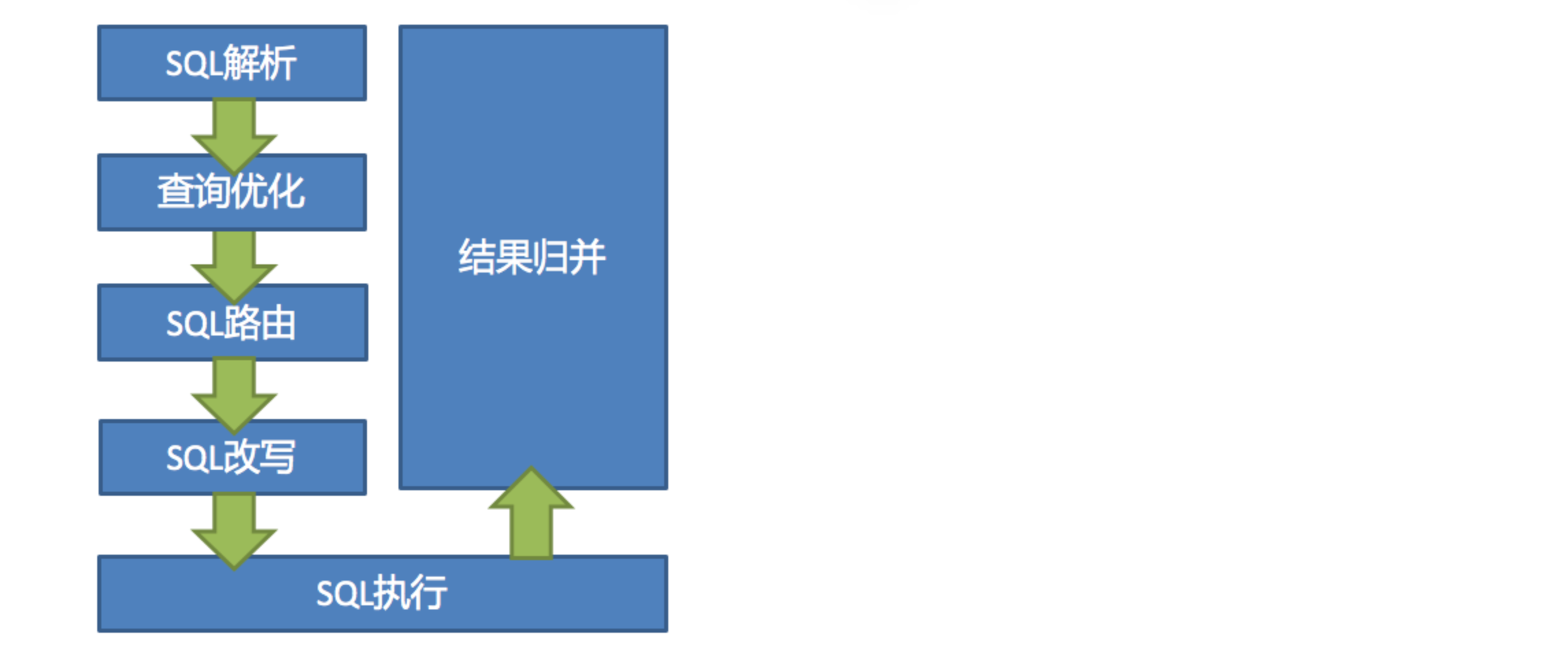
ShardingSphere的3个产品的数据分片主要流程是完全一致的
-
首先连接到Proxy端口执行一条SQL,通过解析引擎SQL会被解析为抽象语语法树,将里面的每一个单词拆分出来,然后标记可能会改写的位置。
SELECT id, name FROM t_user WHERE status = 'ACTIVE' AND age > 18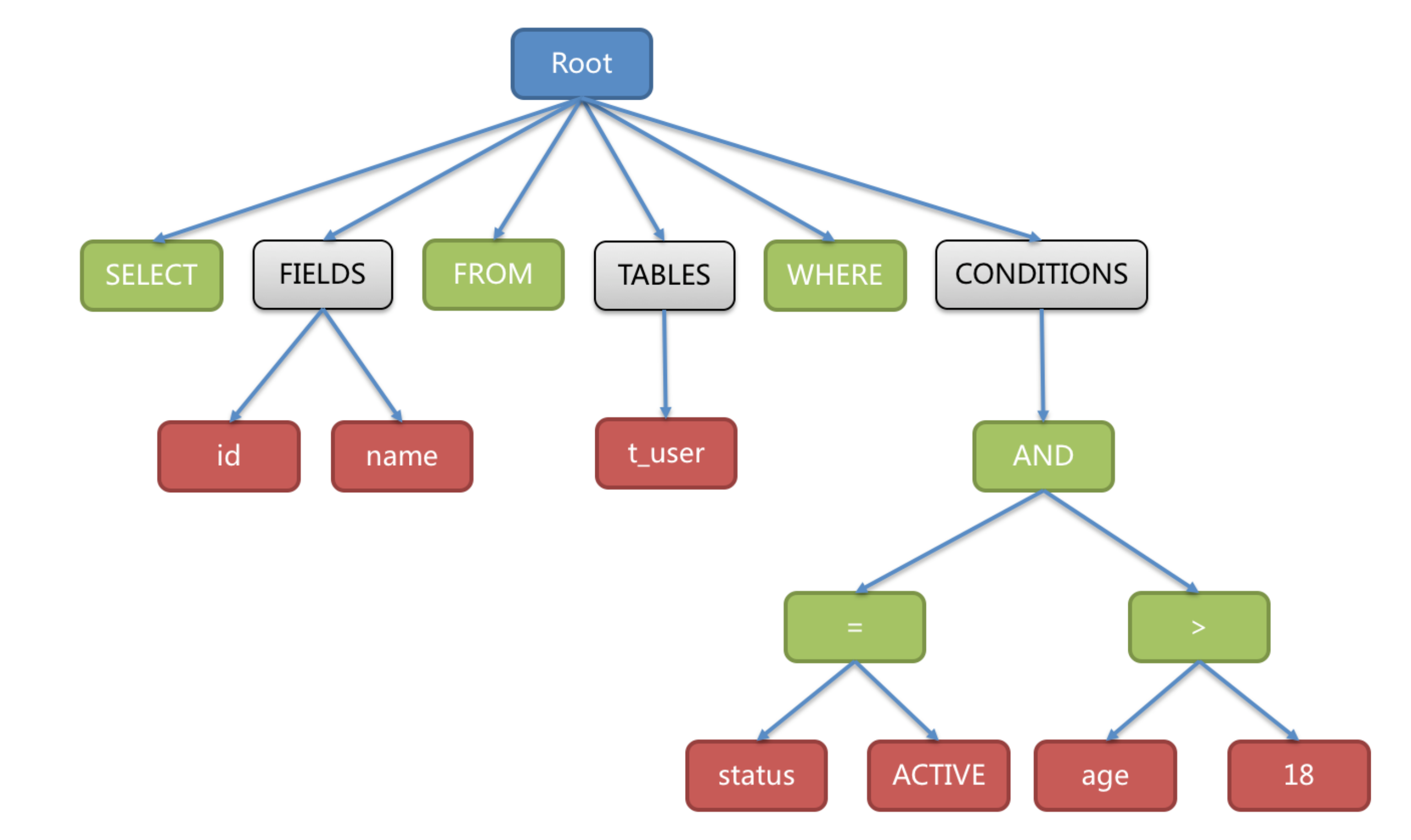
抽象语法树中的关键字的Token用绿色表示,变量的Token用红色表示,灰色表示需要进一步拆分
从3.0.x版本开始使用Druid ANTLR作为解析引擎,为了提高效率增加了缓存机制,因此建议采用PreparedStatement预编译的SQL
-
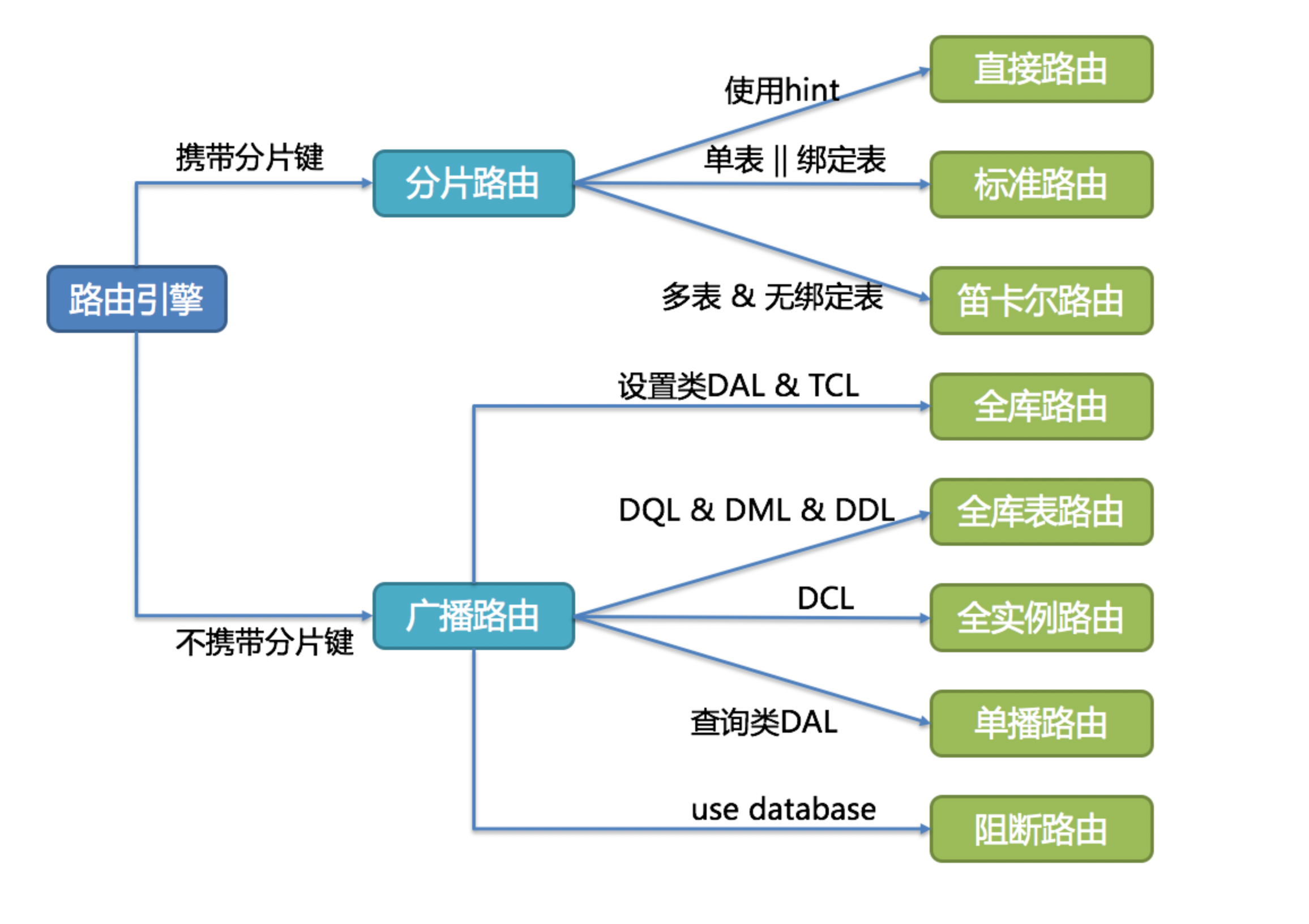
路由引擎通过分片规则(取模、哈希、范围、标签、时间等等)路由到真实的库表
分片路由
- 直接路由:不管SQL是什么样,就要按照规则进行路由,直接指定路由至库表方式分片
- 标准路由:当查询是等于、in、between时就是标准路由,路由结果不一定落入唯一的库,一条SQL可能被拆分为多条用于执行的SQL
- 笛卡尔积路由:无法根据分片规则计算出SQL应该在哪个数据库、哪个表上执行,那么结果就是把所有分库分表中关联使用到的表交叉查询
广播路由
- 全库表路由:对于不带分片键的DQL和DML,以及DDL等会便利所有库表,一一执行,例如select * from user
- 全库路由:对数据库插座都会遍历真实库,例如SET autocommit=0;这种TCL事务控制语句
- 全实例路由:对于DCL操作,会在每个数据库实例中执行一遍
- 单播路由:仅需要从任意库中的任意真实表中获取数据即可 DESCRIBE t_order;
- 阻断路由:用于屏蔽SQL对数据库的操作 USE order_db;,这个命令在真实库中执行
-
改写引擎改写SQL语句,把库名表名替换为配置的信息
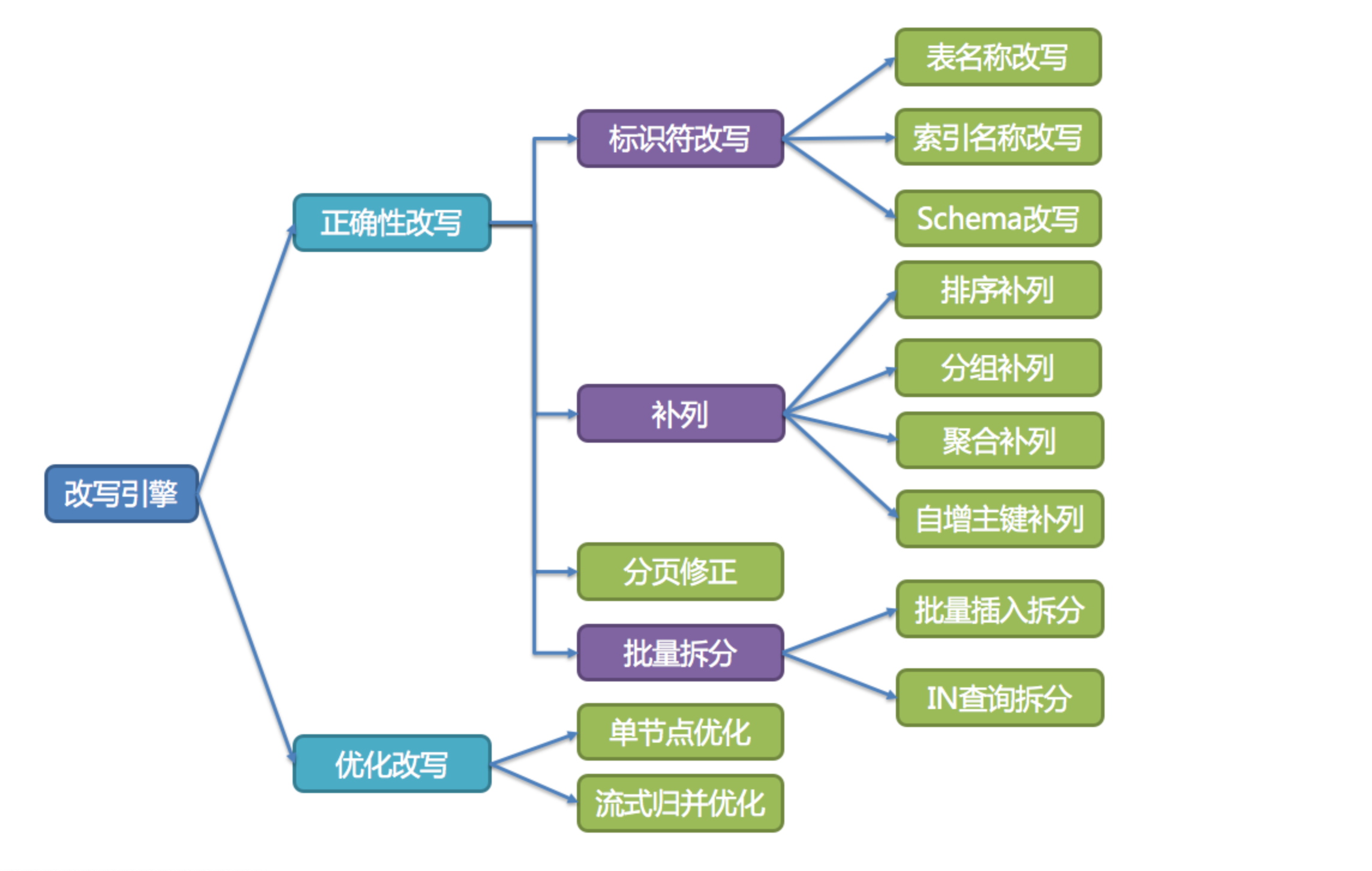
-
执行引擎执行SQL把结果流发送给MySQL服务器,经过MySQL执行后从存储引擎里面把结果集返回出来到Proxy
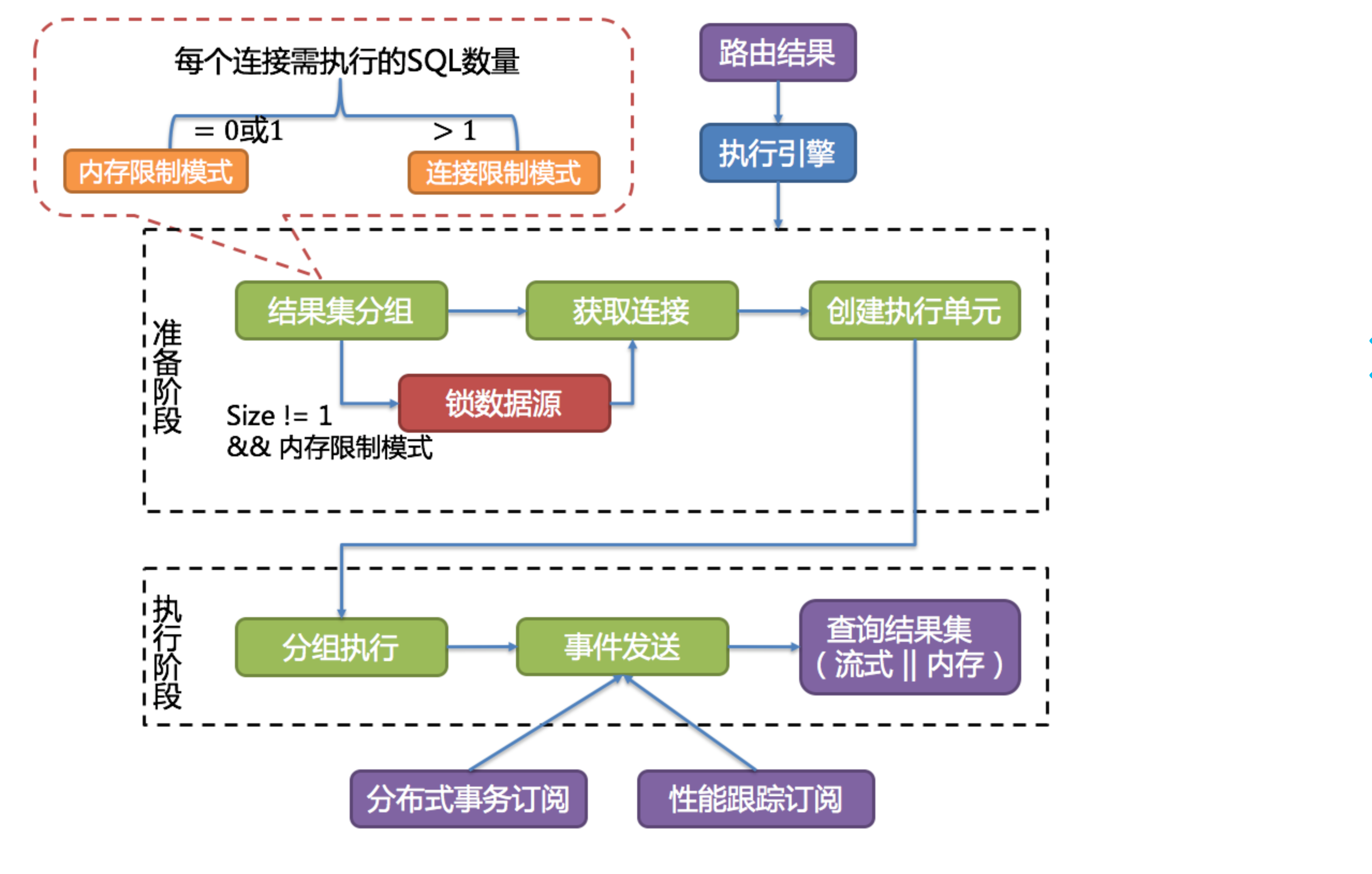
-
归并引擎把接收到的数据归并汇总,然后把结果发送给MySQL客户端
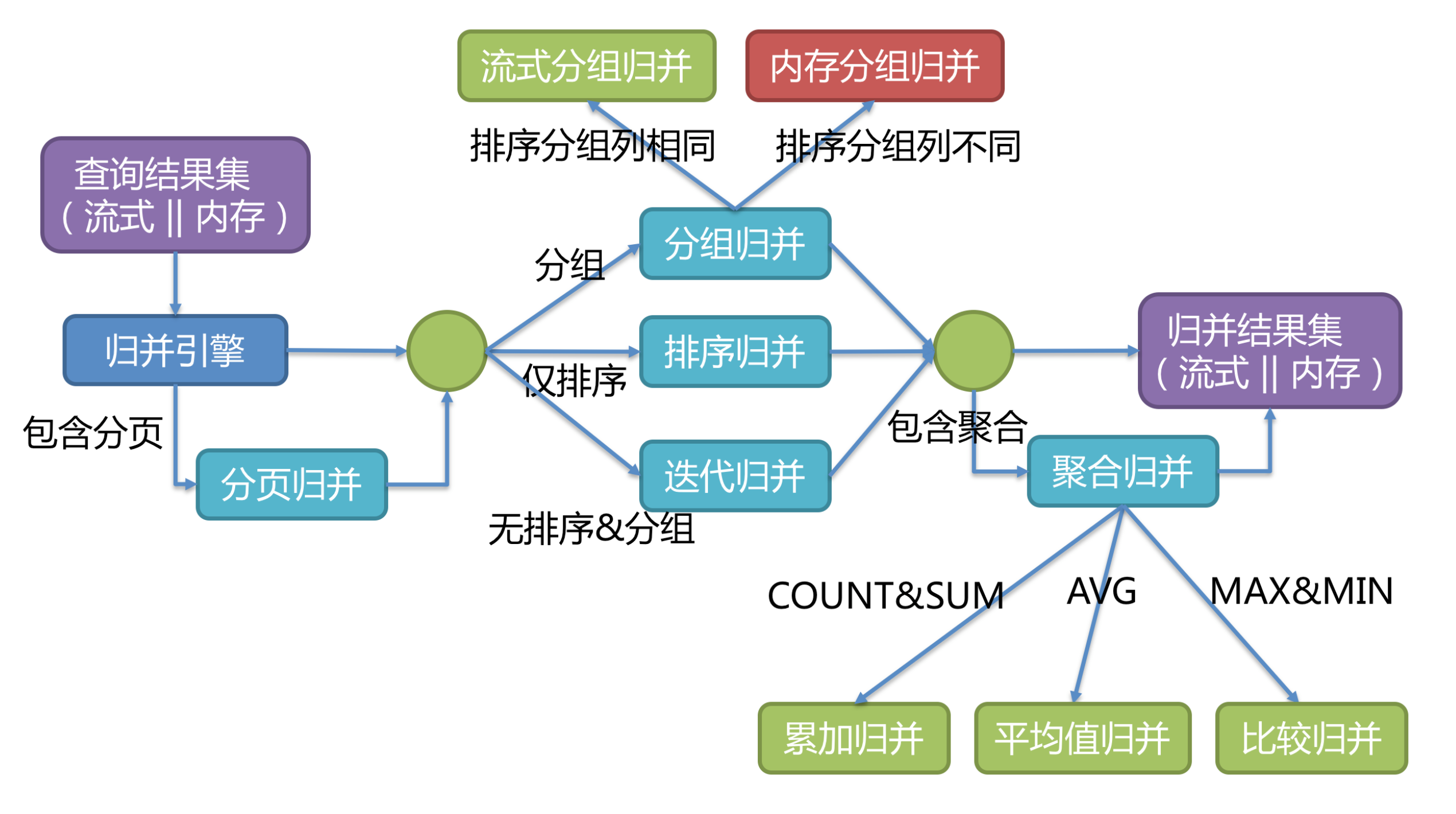
Sharding-jdbc 3.0不支持的sql
- 不支持CASE WHEN、HAVING、UNION (ALL),可以拆分查询自己再拼接
- 子查询不能出现相同的表
- 包含聚合函数的子查询
- 同时使用distinct和聚合函数
ShardingSphere扩展点
ShardingAlgorithm扩展点就列出了ShardingSphere默认提供的多种分片策略:
- InlineShardingAlgorithm:基于⾏表达式的分⽚算法
- ModShardingAlgorithm:基于取模的分⽚算法
- HashModShardingAlgorithm:基于哈希取模的分⽚算法
- FixedIntervalShardingAlgorithm:基于固定时间范围的分⽚算法
- MutableIntervalShardingAlgorithm:基于可变时间范围的分⽚算法
- VolumeBasedRangeShardingAlgorithm:基于分⽚容量的范围分⽚算法
- BoundaryBasedRangeShardingAlgorithm:基于分⽚边界的范围分⽚算法
还有其他分布式主键、分布式ID等等扩展点
分库分表中间件对比#
-
Cobar
阿里 b2b 团队开发和开源的,属于 proxy 层方案,就是介于应用服务器和数据库服务器之间。应用程序通过 JDBC 驱动访问 Cobar 集群,Cobar 根据 SQL 和分库规则对 SQL 做分解,然后分发到 MySQL 集群不同的数据库实例上执行。早些年还可以用,但是最近几年都没更新了,基本没啥人用,差不多算是被抛弃的状态吧。而且不支持读写分离、存储过程、跨库 join 和分页等操作。由于Cobar发起人的离职,Cobar停止维护
-
TDDL
淘宝团队开发的,属于 client 层方案。支持基本的 crud 语法和读写分离,但不支持 join、多表查询等语法。目前使用的也不多,因为还依赖淘宝的 diamond 配置管理系统。
-
Atlas
是360团队基于mysql proxy改写,功能还需完善,高并发下不稳定
-
Sharding-jdbc
当当开源的,属于 client 层方案,目前已经更名为 ShardingSphere(后文所提到的 Sharding-jdbc,等同于 ShardingSphere)。确实之前用的还比较多一些,因为 SQL 语法支持也比较多,没有太多限制,而且截至 2019.4,已经推出到了 4.0.0-RC1 版本,支持分库分表、读写分离、分布式 id 生成、柔性事务(最大努力送达型事务、TCC 事务)。而且确实之前使用的公司会比较多一些(这个在官网有登记使用的公司,可以看到从 2017 年一直到现在,是有不少公司在用的),目前社区也还一直在开发和维护,还算是比较活跃,个人认为算是一个现在也可以选择的方案。
-
Mycat
基于 Cobar 改造的,解决了cobar存在的问题,并且加入了许多新的功能在其中。青出于蓝而胜于蓝,属于 proxy 层方案,支持的功能非常完善,而且目前应该是非常火的而且不断流行的数据库中间件,社区很活跃,也有一些公司开始在用了。但是确实相比于 Sharding jdbc 来说,年轻一些,经历的锤炼少一些。
Sharing-jdbc不用部署,直接使用jar包,相对维护起来比较简单,运维成本低
Mycat属于代理Proxy,需要部署运维,它是一个中间件
建议中小型公司选用 Sharding-jdbc,client 层方案轻便,而且维护成本低,不需要额外增派人手,而且中小型公司系统复杂度会低一些,项目也没那么多;但是中大型公司最好还是选用 Mycat 这类 proxy 层方案,因为可能大公司系统和项目非常多,团队很大,人员充足,那么最好是专门弄个人来研究和维护 Mycat,然后大量项目直接透明使用即可
分布分表应用和问题#
1、在数据库设计的时候就考虑垂直分库和分表
2、数据库数据越来越多不要考虑水平切分,先考虑读写分离,使用索引等等。如果解决不了在使用水平分表
带来的问题:
- 跨分片的事务一致性难以保证
- 跨库的join关联查询性能较差
- 数据多次扩展难度和维护量极大
- 查询问题表分布在不同的库里面
- 分页查询不方便
解决方案:
-
跨分片的事务一致性难以保证
- 拆分成多个小事务,来进行总控制
- 使用分布式事务,性能代价高(推荐)
-
join操作
- 数据分布在不同的表:分两次查询再合并,先查关联id再根据关联id去另一个表查数据(推荐)
- 全局数据:这样的数据比较少修改,很多模块都会依赖这个表,这样可以在每个数据库保存一份,避免跨库查询
- 字段冗余:可能需要的数据字段在详细表中,可以将字段放过来,避免join查询
- Mycat支持跨库join
-
count操作
先在不同库中把数据取出来,最后再统计
-
分页操作
1、数据拼装:先在不同库中把数据取出来,最后再合并分页,如果数据量太大很消耗系统资源,性能也很差
2、禁止跳页:降低技术方案
3、数据库均衡:如果数据差不多均衡的话,各个库各取一半数据,优点是不需要再进行内存排序,但是精度可能会丢失一些
-
数据多次扩展难度和维护量极大
-
查询问题
- 直接查询:每个数据库执行一遍语句,性能差
- 模糊查询:数据拼装
- 使用关联表/关联字段:具体表分布在哪个库
- MyCat多线程查询:类似第一种方式
- 异构索引:额外建立一个索引表记录分片键和非分片字段的对应关系,例如通过xx字段找到订单id,然后根据订单id找到对应的库(方法可以,但没法通用范围,状态等等不好查)
- 实时数仓:通过中间件监听数据库binlog日志,实时收集数据
-
分表后使用非分片字段查询问题(根据任意一个字段查询数据,如何找到所在表)
根据订单ID进行分库,如果需要删除前一天的订单记录,那么需要在每个库中执行一遍sql,没法确定哪个库执行哪个库不执行
解决办法:冗余字段:因为是根据订单id进行路由的,那么几个路由的键都是固定的,比如路由到3个库,那么0、1、2分别代表这三个库的索引,在表里面记录下这个字段,就可以直接找到这个库进行删除。
-
主键ID问题(为什么不使用自增或者UUID)
-
使用自增可能会出现ID重复的问题
-
使用UUID 缺点:太长不方便排序
-
雪花算法:(0+41位时间戳+10位工作机器id+12位序列号)传给前端的时候用String,使用Long的话前端js会溢出。缺点:时间戳依赖于机器时钟。如果机器时间回调,还是可能会有冲突
-
使用redis生成分布式主键
-
-
数据扩缩容
-
扩容的话:一般是因为数据量太多磁盘快满了,原有两台机器,每台机器2个库,每个库4个表,总共个16表,增加服务器2个服务器,每台服务器增加两个库,调整为每个服务器的一个库,每个库里面还是固定的2张表
分片id 取模 8/=库
分片id /8 ,再取模8 = 表
-
-
数据迁移(如何在旧数据上做分库分表)
- 半夜系统停机,停止写入数据然后使用中间件写入(废人)
- 系统不停机,使用双写方案,数据同时写入新库新表和旧表,等于两份数据。再用工具去去读老库的数据到新库中,可以根据主键id或者修改时间区分数据。可能会造成代码入侵,可以监听binlog日志,最后再校验数据是否准确,先校验数量,再使用随机采样法抽取几十条数据合并,比较是否相等通过Base64加密对比
相关博客




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix