Scrapy爬虫框架
一、Scrapy简介
1.1 什么是Scrapy
Scrapy是 Python 开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
1.2 基本功能
Scrapy是一个为爬取网站数据、提取结构性数据而设计的应用程序框架,它可以应用在广泛领域:Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。
尽管Scrapy原本是设计用来屏幕抓取(更精确的说,是网络抓取),但它也可以用来访问API来提取数据。
1.3 Scrapy架构图
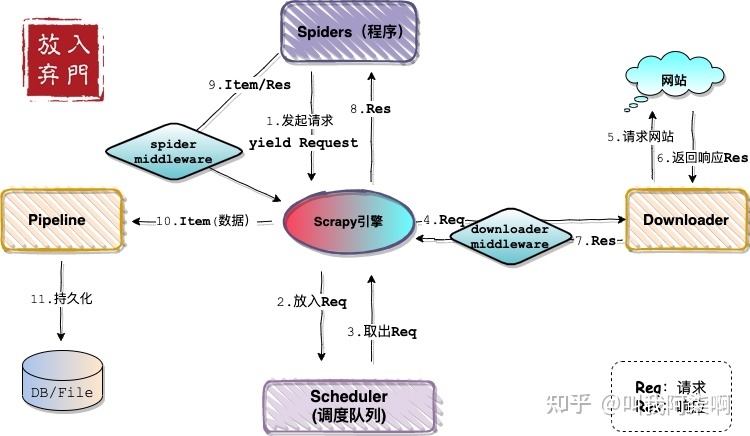
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器).
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
1.4 Scrapy的工作流程
1.首先Spiders(爬虫)将需要发送请求的url(requests)经ScrapyEngine(引擎)交给Scheduler(调度器)。 2.Scheduler(排序,入队)处理后,经ScrapyEngine,DownloaderMiddlewares(可选,主要有User_Agent, Proxy代理)交给Downloader。 3.Downloader向互联网发送请求,并接收下载响应(response)。将响应(response)经ScrapyEngine,SpiderMiddlewares(可选)交给Spiders。 4.Spiders处理response,提取数据并将数据经ScrapyEngine交给ItemPipeline保存(可以是本地,可以是数据库)。 5.提取url重新经ScrapyEngine交给Scheduler进行下一个循环。直到无url请求程序停止结束。
注意!只有当调度器中不存在任何request了,整个程序才会停止,(也就是说,对于下载失败的URL,Scrapy也会重新下载。)
二、创建 Scrapy爬虫项目
制作爬虫一共需要4步:
- 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容
2.1 新建项目
在开始爬取之前,必须创建一个新的Scrapy项目。进入自定义的项目目录中,运行下列命令: 安装模块: python -m pip install --upgrade pip pip install scrapy 新建项目: scrapy startproject mySpider 建项目完成后会有提示,用来创建爬虫代码文件: cd mySpider scrapy genspider exemple exemple.com 其中, mySpider 为项目名称,可以看到将会创建一个 mySpider 文件夹,目录结构大致如下: mySpider/ scrapy.cfg mySpider/ __init__.py items.py pipelines.py settings.py spiders/ __init__.py ...
下面来简单介绍一下各个主要文件的作用,这些文件分别是: scrapy.cfg: 项目的配置文件。 mySpider/: 项目的Python模块,将会从这里引用代码。 mySpider/items.py: 定义数据的结构,类java的class。yield可以将item推送到pipeline中进行处理 mySpider/pipelines.py: 将获取的item进行处理,自定义逻辑将数据持久化存储到文件或数据库 mySpider/settings.py: 项目下所有爬虫配置文件,可以控制爬取速率和并发、配置中间件和管道 myspider/middlewares.py: 下载中间件用在请求之前,可添加UA和代理,蜘蛛中间件用在持久化之前,可实现去重逻辑 mySpider/spiders/: 存储爬虫代码目录。
2.2 明确目标
item.py文件是保存爬取数据的容器,他使用的方法和字典很相似,但是相比字典item多了额外的保护机制,可以避免拼写错误或者定义错误。 在创建item时需要继承scrapy.Item类,并且定义类型为scrapy.Field的类属性来定义一个 Item(可以理解成类似于 ORM 的映射关系)。 目标:我们打算抓取 http://www.itcast.cn/channel/teacher.shtml 网站里的所有讲师的姓名、职称和个人信息 接下来,创建一个 ItcastItem 类,和构建 item 模型(model)。
import scrapy class ItcastItem(scrapy.Item): name = scrapy.Field() title = scrapy.Field() info = scrapy.Field()
根据需求设置爬虫配置文件
#根据robot.txt规则采集(false是关闭)
ROBOTSTXT_OBEY = False
#启用Item Pipeline组件,用框架中封装好的类(ImagesPipeline),去进行图片的爬取
ITEM_PIPELINES = {
'scrapy.pipelines.images.ImagesPipeline': 1
}
#UA 模拟浏览器访问
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
#设置图片下载地址
IMAGES_STORE = 'images'
#item要传递给pipeline管道的url
IMAGES_URLS_FIELD = 'img_url'
2.3 制作爬虫
爬数据:(采集模块spider)
Spider是用户自己编写的类,用来从一个域(或域组)中抓取信息
他们定义了用于下载的URL列表、跟踪链接方案、解析网页内容的方式,以此来提取items。
要建立一个Spider,你必须用scrapy.spider.BaseSpider创建一个子类,并确定三个属性:
name:爬虫的识别名称。必须是唯一的,在不同的爬虫中你必须定义不同的名字
start_urls:爬取的url列表。
parse():解析的方法。调用的时候传入从每一个URL传回的Response对象作为唯一参数,负责解析并匹配抓取的数据(解析为item),跟踪更多的URL
生成代码文件:
方式一:命令生成
cd mySpider
scrapy genspider itcast itcast.cn #生成爬虫代码文件itcast.py;itcase 文件名字;itcase.cn 爬取的网站域名
然后根据自己的需求修改itcast.py文件
方式二:在spiders目录自建Python文件
cd mySpider
vim itcast.py
然后根据自己的需求编写itcast.py文件
页面解析和数据提取
写爬虫最重要的是页面解析和数据提取
一般来讲对我们而言,需要抓取的是某个网站或者某个应用的内容,提取有用的价值。内容一般分为两部分,非结构化的数据 和 结构化的数据。
不同类型的数据,我们需要采用不同的方式来处理。
非结构化数据:先有数据,再有结构
文本、电话号码、邮箱地址
正则表达式
HTML 文件
正则表达式
XPath
CSS选择器
结构化数据:先有结构、再有数据
JSON 文件
JSON Path
转化成Python类型进行操作(json类)
XML 文件
转化成Python类型(xmltodict)
XPath
CSS选择器
正则表达式
选择合适的方式 分析要爬取的网页,并提取内容(可以自己查找如何使用上面提到的处理方式)
完整的爬虫代码文件
# -*- coding: utf-8 -*-
from ..items import ItcastItem
import scrapy
class ItcastSpider(scrapy.Spider):
name = 'itcast'
allowed_domains = ["www.itcast.cn"]
start_urls = ["https://www.itcast.cn/channel/teacher.shtml#ajavaee"]
def parse(self, response):
#file_name = "teacher.html"
#open(file_name,"wb").write(response.body)
items = []
for i in response.xpath("//div[@class='main_mask']"):
# 将我们得到的数据封装到一个 `ItcastItem` 对象
item = ItcastItem()
# extract()方法返回的都是unicode字符串
name = i.xpath('h2/text()').extract()
level = i.xpath('h3/text()').extract()
info = i.xpath('p/text()').extract()
# xpath返回的是包含一个元素的列表
item['name'] = name[0]
item['level'] = level[0]
item['info'] = info[0]
items.append(item)
# 将item提交给管道
yield item
2.4 存储内容
from itemadapter import ItemAdapter
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline
#将数据保存在文本文档中
class MySpiderPipeline(object):
def __init__(self,file_name):
self.file_name = file_name
@classmethod
def from_crawler(cls, crawler):
#获取setting.py文件中的FILE_NAME值,如获取失败就用默认值teachers.txt
return cls(
file_name=crawler.settings.get("FILE_NAME", "teachers.txt")
)
# Spider启动时,执行打开文件操作
def open_spider(self, spider):
print("开始爬取...")
self.file = open(self.file_name, "a", encoding="utf-8")
#数据处理
def process_item(self, item, spider):
novel_str = item["name"] + ";" + item["level"] + ";" + item["info"] + "\n"
self.file.write(novel_str)
return item
#关闭Spider时,执行关闭文件操作
def close_spider(self,spider):
self.file.close()
最后,运行程序:
scrapy crawl itcast
爬取完成。其实爬取文本不需要这么复杂,这是在为后面爬取图片、视频做热身。
作者:等风来~~
本博客所有文章仅用于学习、研究和交流目的,欢迎转载。
如果觉得文章写得不错,或者帮助到您了,请点个赞。
如果文章有写的不足的地方,请你一定要指出,因为这样不光是对我写文章的一种促进,也是一份对后面看此文章的人的责任。谢谢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号