毕业设计相关论文学习
毕业设计相关论文及学习
1. 基于多元线性回归方法的疫情监测系统研究
[1]夏婉玉. 基于多元线性回归方法的疫情监测系统研究[D].武汉工程大学,2022.DOI:10.27727/d.cnki.gwhxc.2022.000481.
2. 中文智能搜索引擎:思路、设计与系统
[1]陈敏.中文智能搜索引擎:思路、设计与系统[J].软件世界,2000(05):60-62.
传统信息检索:
分类检索:
通过人工对网站进行分类,类似于图书馆对图书进行分类。并对每个网站提炼出关键词。
缺点:将花费较高的成本来维护一只专门的人才队伍。除此之外,当用户输入的关键字虽然在该网站中有,但不在人工提炼出的关键词列表中时,将导致漏检。全文检索
只要用户输入的关键字出现在网站中,就将该网站返回给用户。检索过程中通常会设定合理的查全率,并将网站按相关度(查准率)排序。
缺点:大大增加需要处理的数据量。同时往往会返回给用户较多的网页,增加用户筛选的负担。
表达困难
忠实表达
有时很难用关键词串忠实地表达想要检索的内容。与、或、非等逻辑运算的运用对一般人来说有着较高的门槛。表达差异
比如当我们用“电脑”作为关键字时,就检索不到以“计算机”作为关键字的网页,虽然它们是同一个意思。
解决方案(略)
给计算机建设一个知识网,构建不同概念之间的关联,让它能够联想。
3. Web搜索引擎综述
[1]张卫丰,徐宝文,周晓宇等.Web搜索引擎综述[J].计算机科学,2001(09):24-28.
搜索引擎的构成
一般搜索引擎主要由网络蜘蛛、索引与搜索引擎软件等部分组成。
网络蜘蛛:也称“爬行者,是一个功能很强的程序,它会定期根据预先设定的地址去查看对应的网页,如网页发生变化则重新获取该网页,否则根据该网页中的链接继续去访问。
索引:网络蜘蛛将遍历得到的页面存放在临时数据库中。为了提高检索的效率,需要建立索引。索引一般按照倒排文件的格式存放。
搜索引繁软件:该软件用来筛选索引中无数的网页信息,挑出符合查询要求的网页并把它们分级排序,与查询关键字关联越大的排得越前,然后将分级排序后的结果显示给查询用户。
搜索引擎的主要指标
搜索引擎的主要指标有响应时间、查全率、查准率、受欢迎程度、建立索引的方法和相关度等等。
好的搜索引擎应该具有较快的响应速度和高的查全率和查准率,
该文章还讨论了 搜索引擎建立索引的方法 、搜索引擎相关性考虑、搜素引擎的发展趋势
4. Web信息检索技术最新进展
[1]陈定权.Web信息检索技术最新进展[J].现代图书情报技术,2002(02):39-41+58.
主要讨论了 爬行器应该考虑的问题、web网页存储、索引、结果排序与超链分析
5. 基于主题的Web信息采集技术研究
[1]李盛韬. 基于主题的Web信息采集技术研究[D].中国科学院研究生院(计算技术研究所),2002.
6. 基于Python的网络爬虫系统的设计与实现
[1]冯艳茹.基于Python的网络爬虫系统的设计与实现[J].电脑与信息技术,2021,29(06):47-50.DOI:10.19414/j.cnki.1005-1228.2021.06.014.
Python网络爬虫的架构
Python爬虫架构主要有爬虫调度器、URL管理器、HTML下载器、HTML解析器和存储器五部分组成。
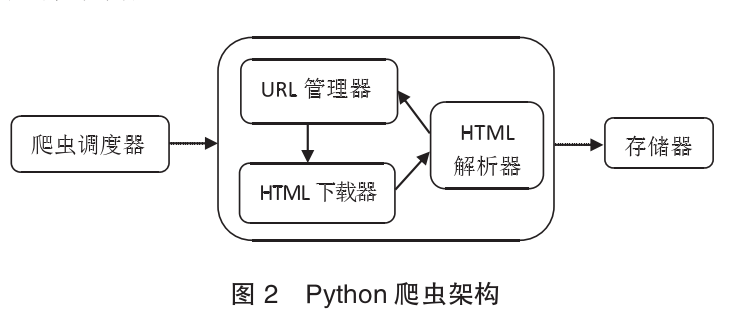
之后就介绍了一些python第三方库,如urllib、requests、re、LXML、BeautifulSoup、Scrapy
7. 基于Web爬虫的学习资源采集系统设计与实现
[1]刘长琦.基于Web爬虫的学习资源采集系统设计与实现[J].辽宁师专学报(自然科学版),2019,21(04):32-37.
Java语言实现,系统主要模块包括采集模板模块、信息采集模块(后台爬虫)、数据分析模块、数据展示模块以及系统管理模块。
8. 基于Python的网页信息爬取技术研究
[1]陈海燕,朱庆华,常莹.基于Python的网页信息爬取技术研究[J].电脑知识与技术,2021,17(08):195-196.DOI:10.14004/j.cnki.ckt.2021.0690.
简单介绍了beautifulSoup库的使用。
9. 基于网络爬虫的数据采集系统设计与实现
[1]赵彦松. 基于网络爬虫的数据采集系统设计与实现[D].东北大学,2015.
主题爬虫的关键模块主要有网页主题相关度评价和网页分析模块。网页主题相关度模块基于预先设定好的关键词,结合相关算法量化相关度评价,再根据预设阀值决定取舍。
互联网的主题站点经过多年发展,其页面分布特点如下:
(1)Hub/Authority特性
网页可分为Hub和Authority网页,Hub网页本身没有正文内容,但却含有许多URL链接;Authority网页对某个主题具有一定的权威性,“吸引”许多链接指向它。
(2)Linkage/SiblingLocality特性
Linkage特性指网页URL链接指向主题相关页面有较大几率。而SiblingLocality特性认为某个URL链接指向某个主题页面的网页有大几率链向符合相同主题的网页。
(3)站点主题特性
站点规划时就会预先做好主题分类。
(4)Tunnel 特性
网络中分布了许多特定主题的团,这些团都是由大量主题网页聚集而成。这些网页团之间看似并不直接互接,但通过若千与主题无关的链接会形成一条无形的隧道,使其连接在一起,这就是Tunnel特性,也称为隧道特性。
系统结构
系统划分为初始化模块、主题爬取模块、通用爬取模块、页面分析模块、增量触发模块和数据存储模块。
初始化模块:在系统运行之初首先需要确定关联信息的主题方向,并设定主题方向的语义描述。根据语义描述可进一步分析关键字、关键词,形成初始关键词队列。为保证数据采集的全面性和准确性,由用户在设立之初设立权威站点,通过权威站点的链接延伸,丰富和完善关键词队列,形成未来爬取的关键词队列
主题爬取模块:
通用爬取模块:通用爬取主要用于动态信息获取,动态信息主要指时效性强的新闻类信息,此类信息除了来源于专题站点,也广泛呈现在网络媒体中。针对此类信息特点,基于广度搜索的通用爬虫算法,主要面向搜索引擎。
增量触发模块:动态信息按两类计时器进行处理,针对权威站点的信息更新情况,设置权威信息定时器,该定时器的激发时间一般以周或月为单位。另一种是针对时效性信息,一般来源于新闻媒体类站点,考虑到新闻媒体类网站较多,且各网站信息量太大,而有效信息太少,对其爬取分析成本过高,所以一般结合爬取主题的一级索引基于搜索引擎(例如,百度、谷歌)进行搜索爬取。
页面解析模块:主要处理页面、链接去重问题和页面分析问题。

10. 基于网络爬虫技术的数据抓取程序的设计
[1]龙香妤.基于网络爬虫技术的数据抓取程序的设计[J].技术与市场,2021,28(10):41-43.
目前主流的爬虫爬取策略有宽度优先遍历策略、深度优先遍历策略、反向连接数、Partial网页级别、OPIC、大站优先策略等几种。宽度优先遍历策略方便实现,但是可能会导致类似拒绝服务攻击等不良效果。深度优先遍历策略可以很容易地爬取到类似目标的内容,不过需要设定深度,否则可能找不到解。反向链接数会根据网页的重要性优先进行爬取,缺点是数据量不够大的情况下效果不明显。Partial网页级别会优先选择评价好的URL进行爬取,然而存在计算量较大、响应速度较慢的问题。OPIC的优点与反向链接数一样,缺点形同Partial网页级别。虽然大站优先策略的爬取效率高,但是其前期爬取数据的效果不太明显。
之后主要介绍了深度优先遍历策略基于网页级别值的优化方案
参考文献
[1]夏婉玉. 基于多元线性回归方法的疫情监测系统研究[D].武汉工程大学,2022.DOI:10.27727/d.cnki.gwhxc.2022.000481.
[1]陈敏.中文智能搜索引擎:思路、设计与系统[J].软件世界,2000(05):60-62.
[1]张卫丰,徐宝文,周晓宇等.Web搜索引擎综述[J].计算机科学,2001(09):24-28.
[1]陈定权.Web信息检索技术最新进展[J].现代图书情报技术,2002(02):39-41+58.
[1]李盛韬. 基于主题的Web信息采集技术研究[D].中国科学院研究生院(计算技术研究所),2002.
[1]冯艳茹.基于Python的网络爬虫系统的设计与实现[J].电脑与信息技术,2021,29(06):47-50.DOI:10.19414/j.cnki.1005-1228.2021.06.014.
[1]刘长琦.基于Web爬虫的学习资源采集系统设计与实现[J].辽宁师专学报(自然科学版),2019,21(04):32-37.
[1]陈海燕,朱庆华,常莹.基于Python的网页信息爬取技术研究[J].电脑知识与技术,2021,17(08):195-196.DOI:10.14004/j.cnki.ckt.2021.0690.
[1]赵彦松. 基于网络爬虫的数据采集系统设计与实现[D].东北大学,2015.
[1]龙香妤.基于网络爬虫技术的数据抓取程序的设计[J].技术与市场,2021,28(10):41-43.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号