ch9学习笔记
第九章学习笔记
知识点归纳

文件流与缓冲区
在C中引入了流(stream)的概念。它将数据的输入输出看作是数据的流入和流出,这样不管是磁盘文件或者是物理设备(打印机、显示器、键盘等),都可看作一种流的源和目的,视他们为同一种东西,而不管其具体的物理结构
缓冲区存在于流与具体的设备终端或者存储介质上的文件之间。
标准I / O提供缓存的目的是尽可能减少使用read和write调用的数量。
它也对每个I / O流自动地进行缓存管理。缓存可由标准I / O例程自动地刷新(例如当填满一个缓存时),或者可以调用函数fflush()刷新一个流。
标准I / O提供了三种类型的缓存:全缓存、行缓存、无缓存。
fopen
FILE *fopen(const char *filename, const char *mode)
- b 二进制模式,默认为文本模式
- r 打开,文件必须存在
- w 创建,截断
- a 追加,创建
- r+ r和写入
- w+ w和读取
- a+ a和读取
fread()
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream)
存储数据的地址、读取元素的大小、读取多少个元素、文件指针
fwrite()
size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream)
待写入数据的地址、写入元素的大小、写入多少个元素、文件指针
fgetc()
int fgetc(FILE *stream)
如果没有发生错误,则返回被写入的字符。如果发生错误,则返回 EOF,并设置错误标识符。
fputc()
int fputc(int char, FILE *stream)
如果没有发生错误,则返回被写入的字符。如果发生错误,则返回 EOF,并设置错误标识符。
ungetc()
int ungetc(int char, FILE *stream)
把字符 char(一个无符号字符)推入到指定的流 stream 中,以便它是下一个被读取到的字符。
换言之,ungetc不对文件进行操作,只是针对文件流
fgets()
char *fgets(char *str, int n, FILE *stream)
fgets()读到回车换行就会结束读取
str 存储地址
int n 这是要读取的最大字符数(包括最后的空字符)。通常是使用以 str 传递的数组长度。
如果成功,该函数返回相同的 str 参数。如果到达文件末尾或者没有读取到任何字符,str 的内容保持不变,并返回一个空指针。
如果发生错误,返回一个空指针。
fputs()
int fputs(const char *str, FILE *stream)
str 是一个数组,包含了要写入的字符序列。
fscanf()
int fscanf(FILE *stream, const char *format, 存储地址...)
format -- 这是 C 字符串,包含了以下各项中的一个或多个:空格字符、非空格字符 和 format 说明符。
format 说明符形式为 [=%[*][width][modifiers]type=]
如果成功,该函数返回成功匹配和赋值的个数。如果到达文件末尾或发生读错误,则返回 EOF。
scanf其实是fscanf(stdin,...)
fprintf()
int fprintf(FILE *stream, const char *format, 待输出数据...)
format 是 C 字符串,包含了要被写入到流 stream 中的文本。它可以包含嵌入的 format 标签,format 标签可被随后的附加参数中指定的值替换,并按需求进行格式化。format 标签属性是 %[flags][width][.precision][length]specifier
如果成功,则返回写入的字符总数,否则返回一个负数。
printf其实是fprintf(stdout,...)
sscanf()
int sscanf(const char *str, const char *format, ...) 从str字符串读取格式化输入。
sprintf()
int sprintf(char *str, const char *format, ...) 发送格式化输出到 str 所指向的字符串。
fseek()
int fseek(FILE *stream, long int offset, int origin)
设置流 stream 的文件位置为给定的偏移 offset,参数 offset 意味着从给定的 origin 位置查找的字节数。
origin:
- SEEK_SET 文件的开头
- SEEK_CUR 文件指针的当前位置
- SEEK_END 文件的末尾
ftell()
long int ftell(FILE *stream)
该函数返回位置标识符的当前值。如果发生错误,则返回 -1
与SEEK_END 一起,可以计算文件的大小
rewind()
void rewind(FILE *stream)
相当于 fseek(fp,0,SEEK_SET)
setvbuf()
int setvbuf(FILE *stream, char *buffer, int mode, size_t size)
setvbuf(),设置文件缓冲区,而不必使用fopen()函数打开文件时设定的默认缓冲区,从而控制缓冲区大小、定时刷新缓冲区、改变缓冲区类型、删除流中默认的缓冲区、为不带缓冲区的流开辟缓冲区等。
buffer : 分配给用户的缓冲。如果设置为 NULL,该函数会自动分配一个指定大小的缓冲。
size : 缓冲区大小
mode :
| _IOFBF | 全缓冲:对于输出,数据在缓冲填满时被一次性写入。对于输入,缓冲会在请求输入且缓冲为空时被填充。 |
|---|---|
| _IOLBF | 行缓冲:对于输出,数据在遇到换行符或者在缓冲填满时被写入,具体视情况而定。对于输入,缓冲会在请求输入且缓冲为空时被填充,直到遇到下一个换行符。 |
| _IONBF | 无缓冲:不使用缓冲。每个 I/O 操作都被即时写入。buffer 和 size 参数被忽略。 |
fflush()
int fflush(FILE *stream)
fflush()的作用是用来刷新缓冲区
fflush(stdin)刷新标准输入缓冲区,把输入缓冲区里的东西丢弃
fflush(stdout)刷新标准输出缓冲区,把输出缓冲区里的东西强制打印到标准输出设备上。
如果成功,该函数返回零值。如果发生错误,则返回 EOF
二进制文件与文本文件
-
计算机的存储在物理上是二进制的,所以文本文件与二进制文件的区别并不是物理上的,而是逻辑上的。这两者只是在编码层次上有差异。
-
使用对应的打开方式,否则都可能出问题:
如果以文本模式打开二进制,会将 0x1A 解释为EOF,从而读不到后面的内容;
如果以二进制模式打开文本,那么就不会做文本文件的预处理,比如windows将\n(0x0A)变成回车换行(0x0D 0x0A),二进制打开,就不会把它们变回去。 -
在读二进制文件时,需要知道数据类型(结构),否则读取的时候容易出错。
-
读写二进制文件:fopen(,"+b") fwrite() fread()
-
hexdump -C 可以同时查看二进制文件和它的ASCII解码结果
最有收获的内容
库函数和系统调用
- 分别是什么?
库函数:是由用户或组织自己开发的,具有一定功能的函数集合,一般具有较好平台移植性。
系统调用:是一种由用户态陷入内核态的手段。几乎所有对于硬件的操作,都需要陷入内核态。好处一是封装、屏蔽硬件;二是系统更加安全和稳定。
- 既然库函数想进入内核态,也必须走系统调用,那库函数有什么存在的意义?直接使用系统调用不是更加高效吗?
原因:
-
如果不熟练掌握操作系统编程,自己写的程序性能,大概率不如库函数。
以读写文件为例,库函数在实现时,利用了缓冲技术,可以大大减少系统调用的次数,从而减少用户态和内核态之间的切换,提升效率。如果自己用系统调用读取文件时,不知道去实现缓冲技术,写出来的程序自然低效。 -
对系统调用进行封装,提供面向操作系统的API。既然程序员不一定会熟练掌握操作系统具体知识,那就直接用已经写好的库函数去完成系统调用的相关功能。这样就极大减小了程序的开发难度。
-
可移植性。不同操作系统的系统调用是不同的,使用系统调用编程,在不同的操作系统之间就没有可移植性。而库函数,背后还有着强大的编译器,能够做到相同的代码,经过编译器处理后,能在不同的操作系统上面运行。
- 用哪个?
综上所述,优先使用库函数,在某种情况下,追求极致速度,实现某种操作系统特定功能时,再考虑使用系统调用。
问题与解决思路
argv数组的零号去哪了?
argv[0]
写个程序试验一下,发现是在命令行输入的可执行文件的路径。
在终端运行程序,需要先输入这个程序的路径才能运行,你的输入就是argv[0],不会做任何处理,输入什么就是什么

文件描述符是什么?为什么要用int类型?
文件描述符本质是一个数组的索引值,这个数组里面存储的是指针,指针指向一个文件结构体。(也有说是“键值对”的,文件描述符是key,文件指针是value)
既然文件描述符是数组下标,自然就是非负数了。
0,1,2 文件描述符一般是固定的,即stdin,stdout,stderro,所以用户打开的第一个文件的描述符一般是3
那为什么不直接指针指定文件,非得中间加一层数组,转而使用数组下表呢?
大概是因为操作系统不想让用户知道它的具体实现细节

为什么按位或运算能实现函数标志位的叠加?
例如 : fd = open("2.txt",O_WRONLY|O_CREAT|O_TRUNC);
这里涉及一个叫“位图”的数据结构,点此查看位图的更多信息
就以上面这个代码为例,假设用1个字节的位图来记录,假设O_WRONLY,O_CREAT,O_TRUNC 分别是 位图中的第1位,第2位,第3位,
那么就相当于1000_0000 | 0100_0000 | 0010_0000 = 1110_0000 ,这样就完成了标志位的叠加,而且十分节省空间,1个字节就能搞定8个标志位
高,实在是高

为什么库函数会比系统调用性能更好?
按道理来说,如果使用库函数,会比直接使用系统调用多一道手续,因为库函数也是要去调用系统调用,才能进入内核
但是从结果来看,我们编写的,以字节为单位读写文件的程序,调用库函数的程序运行快得多,为什么?
主要还是因为我们不了解操作系统,自己写出来的系统调用效率太低,与标准库函数的效率相差甚远。
就这次我们写的系统调用的程序来说,存在这样的问题,每一次系统调用,都需要从用户态向内核态转换,这个开销很大;如此巨大的开销,却只操作了一个字节的数据。
而库函数的fgetc()和fputc(),表面看也是每次只操作一个字节,而实际上,在其实现的时候,维护了一个4K的缓冲区(和内核态中的缓冲区大小一致),只有当用户态的缓冲区写满了之后,才发起真正的系统调用,产生一次巨大的开销,一次性将4k的数据,写入内核态的缓冲区,
所以库函数的速度才会比自己写的系统调用快
当我们把自己写的系统调用也设置一个4k的缓冲区后,发现系统调用的速度就会比库函数快了

实践内容
p225的复制文件代码运行
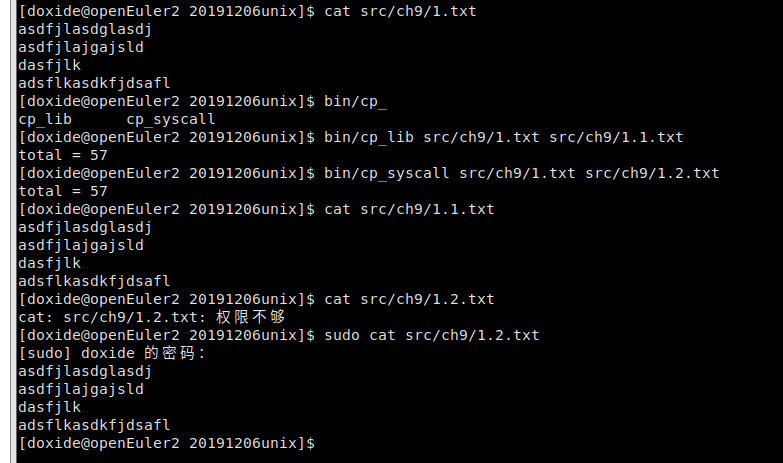
比较库函数和系统调用的速度
都以一个字符为单位,读写文件。
库函数
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int main(){
clock_t start_t, end_t;
double total_t;
start_t = clock();
FILE *fp1,*fp2;
int n;
fp1 = fopen("/home/doxide/20191206unix/src/ch9/1.txt","r");
if(fp1==NULL){
perror("fopen error");
exit(1);
}
fp2 = fopen("/home/doxide/20191206unix/src/ch9/2.txt","w");
if(fp2==NULL){
perror("fopen error");
exit(1);
}
while((n=fgetc(fp1))!=EOF){
fputc(n,fp2);
}
fclose(fp1);
fclose(fp2);
end_t =clock();
total_t = (double)(end_t - start_t) / CLOCKS_PER_SEC;
printf("用时%f\n",total_t);
return 0;
}
系统调用
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <unistd.h>
#define N 1
int main(){
clock_t start_t, end_t;
double total_t;
start_t = clock();
int fd1,fd2;
int n;
char buf[N];
fd1 = open("/home/doxide/20191206unix/src/ch9/1.txt",O_RDONLY);
if(fd1<0){
perror("fopen error");
exit(1);
}
fd2 = open("/home/doxide/20191206unix/src/ch9/2.txt",O_WRONLY|O_CREAT|O_TRUNC,0644);
if(fd2<0){
perror("fopen error");
exit(1);
}
while(n=read(fd1,buf,N)){
if(n<0){
perror("read error");
exit(1);
}
write(fd2,buf,n);
}
close(fd1);
close(fd2);
end_t =clock();
total_t = (double)(end_t - start_t) / CLOCKS_PER_SEC;
printf("用时%f\n",total_t);
return 0;
}
可以看到库函数明显快与系统调用,

改进:给系统调用的程序设置一个4k的缓冲区

fread和fwrite
#include <string.h>
int main()
{
FILE *fp;
char c[] = "This is 20191206陈发强";
char buffer[50];
/* 打开文件用于读写 */
fp = fopen("res/file.txt", "w+");
/* 写入数据到文件 */
fwrite(c, strlen(c) + 1, 1, fp);
/* 查找文件的开头 */
fseek(fp, 0, SEEK_SET);
/* 读取并显示数据 */
fread(buffer, strlen(c)+1, 1, fp);
printf("%s\n", buffer);
fclose(fp);
return(0);
}

fgetc和fputc
1 #include <stdio.h>
2
3 int main ()
4 {
5 FILE *fp;
6 int ch;
7
8 fp = fopen("res/file2.txt", "w+");
9 for( ch = 33 ; ch <= 100; ch++ )
10 {
11 fputc(ch, fp);
12 }
13
14 fseek(fp,0,SEEK_SET);
15
16 int c;
17 while(1)
18 {
19 c = fgetc(fp);
20 if( feof(fp) )
21 {
22 break ;
23 }
24 printf("%c", c);
25 }
26 printf("\n");
27 fclose(fp);
28
29 return(0);
30 }

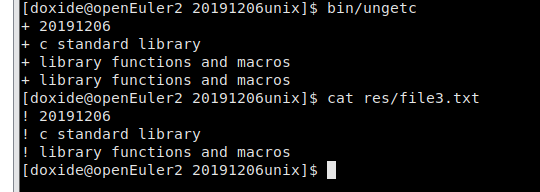
ungetc
1 #include <stdio.h>
2
3 int main ()
4 {
5 FILE *fp;
6 int c;
7 char buffer [256];
8
9 fp = fopen("res/file3.txt", "r");
10 if( fp == NULL )
11 {
12 perror("打开文件时发生错误");
13 return(-1);
14 }
15 while(!feof(fp))
16 {
17 c = getc (fp);
18 /* 把 ! 替换为 + */
19 if( c == '!' )
20 {
21 ungetc ('+', fp);
22 }
23 else
24 {
25 ungetc(c, fp);
26 }
27 fgets(buffer, 255, fp);
28 fputs(buffer, stdout);
29 }
30 return(0);
31 }
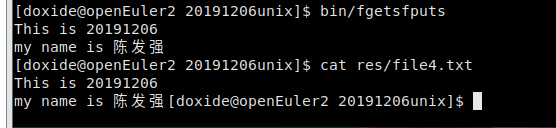
fgets和fputs
1 #include <stdio.h>
2
3 int main()
4 {
5 FILE *fp;
6 char str[60];
7
8 /* 打开用于读取的文件 */
9 fp = fopen("res/file4.txt" , "w+");
10 if(fp == NULL) {
11 perror("打开文件时发生错误");
12 return(-1);
13 }
14
15 fputs("This is 20191206 \nmy name is 陈发强", fp);
16
17 fseek(fp,0,SEEK_SET);
18
19 while( fgets (str, 60, fp)!=NULL ) {
20 /* 向标准输出 stdout 写入内容 */
21 fputs(str,stdout);
22 }
23
24 fclose(fp);
25 printf("\n");
26 return(0);
27 }
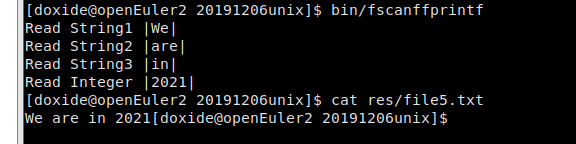
fscanf和fprintf
1 #include <stdio.h>
2 #include <stdlib.h>
3
4
5 int main()
6 {
7 char str1[10], str2[10], str3[10];
8 int year;
9
10 FILE * fp;
11
12 fp = fopen ("res/file5.txt", "w+");
13
14 fprintf(fp, "%s %s %s %d", "We", "are", "in", 2021);
15
16 rewind(fp);
17
18 fscanf(fp, "%s %s %s %d", str1, str2, str3, &year);
19
20 printf("Read String1 |%s|\n", str1 );
21 printf("Read String2 |%s|\n", str2 );
22 printf("Read String3 |%s|\n", str3 );
23 printf("Read Integer |%d|\n", year );
24
25 fclose(fp);
26
27 return(0);
28 }
setvbuf试验
给库函数的缓冲区,也设置成一个字节,无缓冲的模式,再去和一字节的系统调用比较,发现这回是系统调用更快了
1
2 #include <stdio.h>
3 #include <stdlib.h>
4 #include <time.h>
5
6 int main(){
7
8 clock_t start_t, end_t;
9 double total_t;
10
11 start_t = clock();
12
13 FILE *fp1,*fp2;
14 int n;
15
16 char buff[1];
17
18 fp1 = fopen("/home/doxide/20191206unix/src/ch9/1.txt","r");
19 if(fp1==NULL){
20 perror("fopen error");
21 exit(1);
22 }
23 setvbuf(fp1,buff,_IONBF,1);
24
25 fp2 = fopen("/home/doxide/20191206unix/src/ch9/2.txt","w");
26 if(fp2==NULL){
27 perror("fopen error");
28 exit(1);
29 }
30 setvbuf(fp2,buff,_IONBF,1);
31
32 while((n=fgetc(fp1))!=EOF){
33 fputc(n,fp2);
34 }
35 fclose(fp1);
36 fclose(fp2);
37
38 end_t =clock();
39 total_t = (double)(end_t - start_t) / CLOCKS_PER_SEC;
40 printf("用时%f\n",total_t);
41 return 0;
42 }

复制jpg文件
1 #include <stdio.h>
2
3 int main()
4 {
5 FILE *fp = fopen("res/sakura.jpg","rb+");
6 FILE *fp2 = fopen("res/copy.jpg","wb+");
7
8 if(fp==NULL|fp2==NULL){
9 printf("open file error !\n");
10 return -1;
11 }
12
13 char buf[4096];
14 int n = 0;
15
16 while((n=fread(buf,sizeof(char),4096,fp))>0){
17 fwrite(buf,sizeof(char),4096,fp2);
18 }
19
20 fclose(fp);
21 fclose(fp2);
22
23 return 0;
24 }

对比fwrite和fputs
都以wb形式打开文件
用hexdump查看,发现fwrite()写的多一个 00 空字符
fwrite()
#include <stdio.h>
int main()
{
FILE *fp = fopen("res/binwrite.txt","wb");
if(fp==NULL){
perror("open file error");
return -1;
}
char buf[]="20191206陈发强\n";
fwrite(buf,sizeof(buf),1,fp);
fclose(fp);
return 0;
}
fputs()
#include <stdio.h>
int main()
{
FILE *fp = fopen("res/binputs.txt","wb");
if(fp==NULL){
perror("open file error");
return -1;
}
char buf[]="20191206陈发强\n";
fputs(buf,fp);
fclose(fp);
return 0;
}

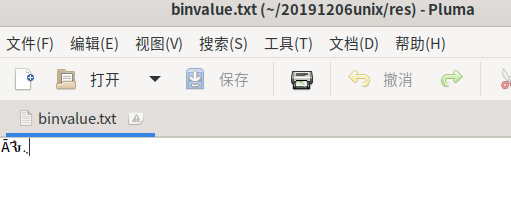
fwrite()写入二进制数值
用文本查看就不能正常解码成可见字符了。
#include <stdio.h>
int main()
{
FILE *fp = fopen("res/binvalue.txt","wb");
if(fp==NULL){
perror("open file error");
return -1;
}
char buf[]={0,1,2,3,4,5,6,7};
fwrite(buf,sizeof(buf),1,fp);
fclose(fp);
return 0;
}