SpringData学习04
滴水穿石

之前的 Repository 的分页不支持传参,怎么破? ...实现 JpaSpecificationExecutor<T> 接口
service 层
/** * Specification<T> : 封装了 JPA Criteria 查询的查询条件 * Pageable : 封装了请求分页的信息 * */ public Page<Person> findByJpaSpecificationExecutor(Specification<Person> spec,Pageable pageable){ return pRepository.findAll(spec, pageable); }
单元测试
/** * 实现带查询条件的分页 * */ @Test public void testJpaSpecificationExecutor(){ int page = 3 - 1; int size = 5; PageRequest pageable = new PageRequest(page, size); Specification<Person> spec = new Specification<Person>() { /** * *root : 代表查询的实体类 * query : 从中可得到Root对象,即告知JPA Criteria 查询要查询哪一个实体类 * 还可以用来添加查询条件, * 还可以结合EntityManager 对象得到最终查询的 TypedQuery 对象 * *cb : CriteriaBuilder对象,用于创建 Criteria相关对象的工厂,当然可以从中获取Predicate对象 * *Predicate : 代表一个查询条件 * */ @Override public Predicate toPredicate(Root<Person> root, CriteriaQuery<?> query, CriteriaBuilder cb) { Path path = root.get("id"); Predicate predicate = cb.gt(path, 5); return predicate; } }; Page<Person> plist = pService.findByJpaSpecificationExecutor(spec, pageable); System.out.println("总条数: " + plist.getTotalElements()); System.out.println("总页数: " + plist.getTotalPages()); System.out.println("当前页数: " + (plist.getNumber()+1)); System.out.println("当前页面记录数: " + plist.getNumberOfElements()); System.out.println("当前页面List: " + plist.getContent()); }
测试结果
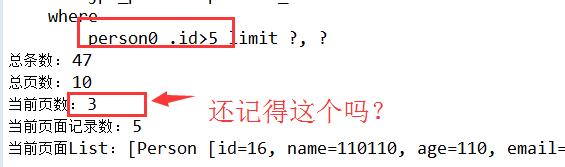
当前页数 为 21 , "xxx" + 2 + 1 ; 不能忽略呀 要写成 “xxxx” + (2+1) 哦
这个方式工作中肯定是不科学的,需要构建一个通用的Base类。
自定义方法

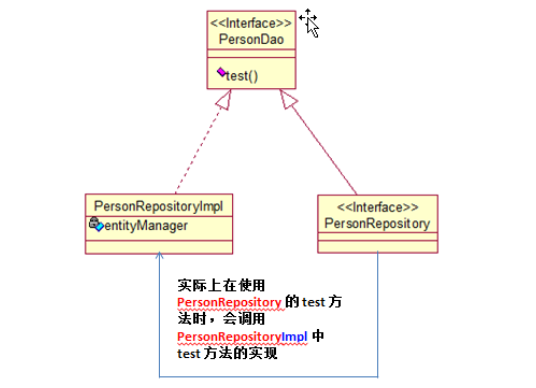
—————————————————————————————————————————————————————————————————————————
无论如何,心平气和

 浙公网安备 33010602011771号
浙公网安备 33010602011771号