
爬虫————获取图片(scrapy使用自带类 ImagesPipeline)
爬取的图片网址为:http://699pic.com/collectInfo/273785
解决问题的参考链接:https://blog.csdn.net/loner_fang/article/details/81111879
问题代码1
imgpro.py
1 # -*- coding: utf-8 -*- 2 import scrapy 3 4 from tupian.items import TupianItem 5 from scrapy.selector.unified import SelectorList 6 7 8 class ImgproSpider(scrapy.Spider): 9 name = 'imgpro' 10 #allowed_domains = ['699pic.com'] 11 start_urls = ['http://699pic.com/collectInfo/273785'] 12 13 def parse(self, response): 14 li_ul = response.xpath('/html/body/div[11]/div/ul') 15 # print(type(li_ul)) 16 for li in li_ul : 17 img_src = li.xpath('./li/a/img/@src').extract() 18 # print(img_src) 19 if img_src: 20 item = TupianItem() 21 item['src'] = img_src 22 yield item
pipeline.py
1 # -*- coding: utf-8 -*- 2 3 # Define your item pipelines here 4 # 5 # Don't forget to add your pipeline to the ITEM_PIPELINES setting 6 # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html 7 8 9 # class TupianPipeline(object): 10 # def process_item(self, item, spider): 11 # return item 12 13 from scrapy.pipelines.images import ImagesPipeline 14 import scrapy 15 16 class TupianPipeline(ImagesPipeline): 17 18 # 对某一个媒体资源进行请求发送 19 # item就是接收到的spider提交过来的item 20 def get_media_requests(self, item, info): 21 22 23 yield scrapy.Request(item['src']) 24 25 #制定媒体数据存储的名称/html/body/div[11]/div/ul /html/body/div[11]/div/ul 26 def file_path(self, request, response=None, info=None): 27 name = request.url.split('/')[-1] 28 print("正在下载。。。。。。。",name) 29 return name 30 31 #将item传递给下一个即将执行的管道类 32 def item_completed(self, results, item, info): 33 return item
错误类型
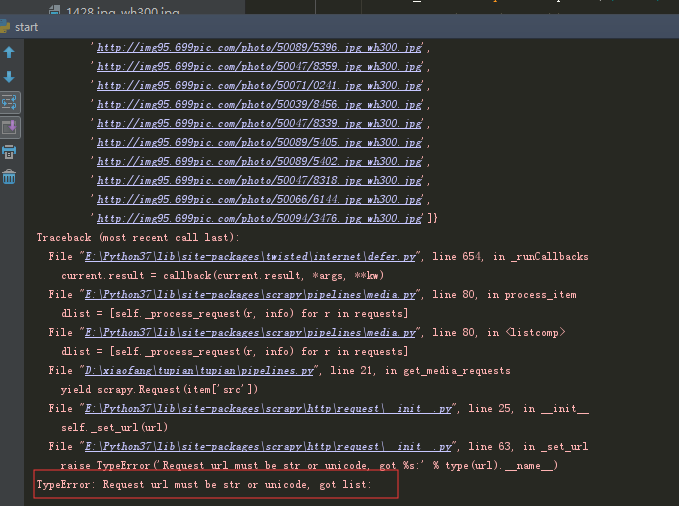
分析错误原因:
1、在写爬虫文件解析response时,获取图片的下载地址,一开始写的xpath是@src

修改后为下图所示
后来排查代码,观察网页源代码,发现源代码中@src的值是http://static.699pic.com/images/blank.png。刚才element中的src是经过渲染之后的值,所以最后采用的@data-original。这也就证实了爬虫获取到的response是网页的源码,爬取之前需要先确认源码和element中的元素和值是否一致,只有一致了才可以直接使用element中的元素和值。

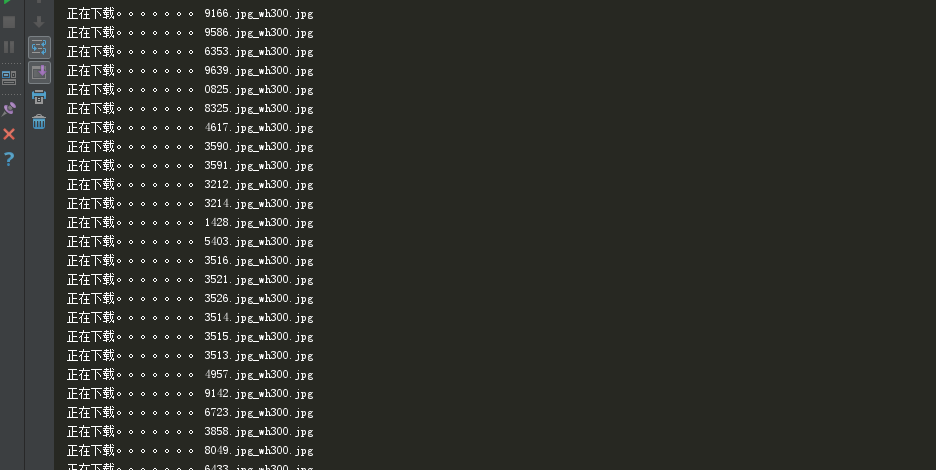
2、遍历image_urls里的每一个url,调用调度器和下载器,下载图片 。 图片下载完毕后,处理结果会以二元组的方式返回给item_completed()函数
错误点为下图

修改后为下图

1 # -*- coding: utf-8 -*- 2 import scrapy 3 4 from tupian.items import TupianItem 5 from scrapy.selector.unified import SelectorList 6 7 8 class ImgproSpider(scrapy.Spider): 9 name = 'imgpro' 10 #allowed_domains = ['699pic.com'] 11 start_urls = ['http://699pic.com/collectInfo/273785'] 12 13 def parse(self, response): 14 li_ul = response.xpath('/html/body/div[11]/div/ul') 15 # print(type(li_ul)) 16 for li in li_ul : 17 img_src = li.xpath('./li/a/img/@data-original').extract() 18 # print(img_src) 19 if img_src: 20 item = TupianItem() 21 item['src'] = img_src 22 yield item
1 # -*- coding: utf-8 -*- 2 3 # Define your item pipelines here 4 # 5 # Don't forget to add your pipeline to the ITEM_PIPELINES setting 6 # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html 7 8 9 # class TupianPipeline(object): 10 # def process_item(self, item, spider): 11 # return item 12 13 from scrapy.pipelines.images import ImagesPipeline 14 import scrapy 15 16 class TupianPipeline(ImagesPipeline): 17 18 # 对某一个媒体资源进行请求发送 19 # item就是接收到的spider提交过来的item 20 def get_media_requests(self, item, info): 21 22 for image_url in item['src']: 23 yield scrapy.Request(image_url) 24 25 #制定媒体数据存储的名称/html/body/div[11]/div/ul /html/body/div[11]/div/ul 26 def file_path(self, request, response=None, info=None): 27 name = request.url.split('/')[-1] 28 print("正在下载。。。。。。。",name) 29 return name 30 31 #将item传递给下一个即将执行的管道类 32 def item_completed(self, results, item, info): 33 return item
1 # -*- coding: utf-8 -*- 2 3 # Define here the models for your scraped items 4 # 5 # See documentation in: 6 # https://docs.scrapy.org/en/latest/topics/items.html 7 8 import scrapy 9 10 11 class TupianItem(scrapy.Item): 12 # define the fields for your item here like: 13 # name = scrapy.Field() 14 src = scrapy.Field()
1 # -*- coding: utf-8 -*- 2 3 # Scrapy settings for tupian project 4 # 5 # For simplicity, this file contains only settings considered important or 6 # commonly used. You can find more settings consulting the documentation: 7 # 8 # https://docs.scrapy.org/en/latest/topics/settings.html 9 # https://docs.scrapy.org/en/latest/topics/downloader-middleware.html 10 # https://docs.scrapy.org/en/latest/topics/spider-middleware.html 11 12 BOT_NAME = 'tupian' 13 14 SPIDER_MODULES = ['tupian.spiders'] 15 NEWSPIDER_MODULE = 'tupian.spiders' 16 17 18 # Crawl responsibly by identifying yourself (and your website) on the user-agent 19 #USER_AGENT = 'tupian (+http://www.yourdomain.com)' 20 21 # Obey robots.txt rules 22 ROBOTSTXT_OBEY = False 23 24 LOG_LEVEL = 'ERROR' 25 26 IMAGES_STORE = './imgsLib' 27 28 # Configure maximum concurrent requests performed by Scrapy (default: 16) 29 #CONCURRENT_REQUESTS = 32 30 31 # Configure a delay for requests for the same website (default: 0) 32 # See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay 33 # See also autothrottle settings and docs 34 #DOWNLOAD_DELAY = 3 35 # The download delay setting will honor only one of: 36 #CONCURRENT_REQUESTS_PER_DOMAIN = 16 37 #CONCURRENT_REQUESTS_PER_IP = 16 38 39 # Disable cookies (enabled by default) 40 #COOKIES_ENABLED = False 41 42 # Disable Telnet Console (enabled by default) 43 #TELNETCONSOLE_ENABLED = False 44 45 # Override the default request headers: 46 DEFAULT_REQUEST_HEADERS = { 47 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 48 'Accept-Language': 'en', 49 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36' 50 51 } 52 53 # Enable or disable spider middlewares 54 # See https://docs.scrapy.org/en/latest/topics/spider-middleware.html 55 #SPIDER_MIDDLEWARES = { 56 # 'tupian.middlewares.TupianSpiderMiddleware': 543, 57 #} 58 59 # Enable or disable downloader middlewares 60 # See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html 61 #DOWNLOADER_MIDDLEWARES = { 62 # 'tupian.middlewares.TupianDownloaderMiddleware': 543, 63 #} 64 65 # Enable or disable extensions 66 # See https://docs.scrapy.org/en/latest/topics/extensions.html 67 #EXTENSIONS = { 68 # 'scrapy.extensions.telnet.TelnetConsole': None, 69 #} 70 71 # Configure item pipelines 72 # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html 73 ITEM_PIPELINES = { 74 # 'scrapy.pipelines.images.ImagesPipeline': 1, 75 'tupian.pipelines.TupianPipeline': 300, 76 } 77 78 # Enable and configure the AutoThrottle extension (disabled by default) 79 # See https://docs.scrapy.org/en/latest/topics/autothrottle.html 80 #AUTOTHROTTLE_ENABLED = True 81 # The initial download delay 82 #AUTOTHROTTLE_START_DELAY = 5 83 # The maximum download delay to be set in case of high latencies 84 #AUTOTHROTTLE_MAX_DELAY = 60 85 # The average number of requests Scrapy should be sending in parallel to 86 # each remote server 87 #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 88 # Enable showing throttling stats for every response received: 89 #AUTOTHROTTLE_DEBUG = False 90 91 # Enable and configure HTTP caching (disabled by default) 92 # See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings 93 #HTTPCACHE_ENABLED = True 94 #HTTPCACHE_EXPIRATION_SECS = 0 95 #HTTPCACHE_DIR = 'httpcache' 96 #HTTPCACHE_IGNORE_HTTP_CODES = [] 97 #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号