
爬虫———通过pipeline以及items 将数据以json类型存储
1、books.py


1 import scrapy 2 from scrapy.selector.unified import SelectorList 3 4 class BooksSpider(scrapy.Spider): 5 name = 'books' 6 allowed_domains = ['books.toscrape.com'] 7 start_urls = ['http://books.toscrape.com/catalogue/page-1.html'] 8 9 def parse(self, response): 10 # print('*') 11 # print(type(response)) # <class 'scrapy.http.response.html.HtmlResponse'> 12 # print('*') 13 14 Books_lis = response.xpath("//div/ol[@class='row']/li") 15 # print('*') 16 # print(type(Books_lis)) 17 # print('*') 18 for Books_li in Books_lis: 19 book_name = Books_li.xpath(".//h3/a/@title").get() 20 book_price = Books_li.xpath(".//div[@class='product_price']/p[@class='price_color']/text()").getall() 21 22 book_price = "".join(book_price) 23 books_all = {"book_name":book_name,"book_price":book_price} 24 yield books_all
2、pipeline .py
1 import json 2 3 4 class BooksPipeline(object): 5 def __init__(self): 6 self.file = open("books_all.json", "w", encoding="utf-8") 7 8 def open_spider(self, spider): 9 # self.file = open('items.jl', 'w') 10 print("爬虫开始了。。。") 11 12 def close_spider(self, spider): 13 self.file.close() 14 print("爬虫结束了。。。") 15 16 def process_item(self, item, spider): 17 # line = json.dumps(dict(item)) + "\n" 18 # self.file.write(line) 19 item_json = json.dumps(item,ensure_ascii= False) 20 self.file.write(item_json+'\n') 21 return item
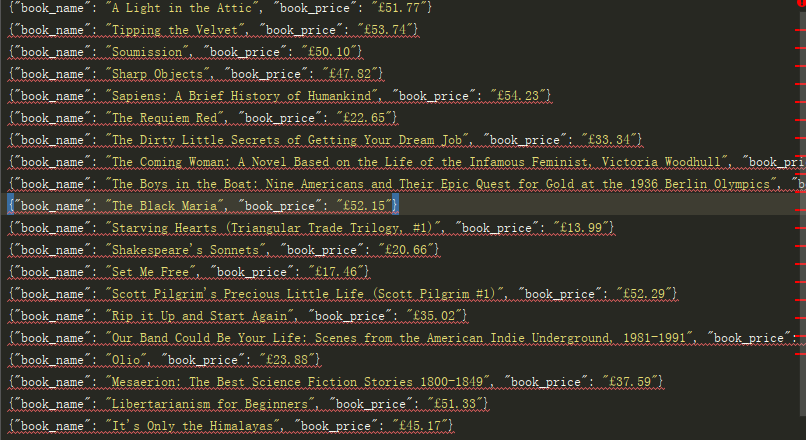
3、结果
3、犯的错误


4、专业化
设置item.py文件
1 from scrapy import Item,Field 2 3 4 class BooksItem(Item): 5 # define the fields for your item here like: 6 # name = scrapy.Field() 7 book_name = Field() 8 book_price = Field()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号