Suricata源码分析-流管理引擎(flow engine)
初始化
flow engine的初始化主要分为两部分,线程的初始化和配置的初始化,都在SuricataMain* -> PostConfLoadedSetup*(包含一些配置被加载后需要运行的代码)中
线程初始化
函数调用堆栈: -> RegisterAllModules*(注册了suricata所有的线程模块) ->* TmModuleFlowWorkerRegister*(初始化flow worker线程)*
TmModuleFlowWorkerRegister 会填充全局变量tmm_modules字段,注册线程函数。代码如下:
void TmModuleFlowWorkerRegister (void)
{
tmm_modules[TMM_FLOWWORKER].name = "FlowWorker";
tmm_modules[TMM_FLOWWORKER].ThreadInit = FlowWorkerThreadInit; // 线程初始化函数
tmm_modules[TMM_FLOWWORKER].Func = FlowWorker; // 功能主入口
tmm_modules[TMM_FLOWWORKER].ThreadDeinit = FlowWorkerThreadDeinit; // 用来释放的函数
tmm_modules[TMM_FLOWWORKER].ThreadExitPrintStats = FlowWorkerExitPrintStats; // 退出时打印信息
tmm_modules[TMM_FLOWWORKER].cap_flags = 0;
tmm_modules[TMM_FLOWWORKER].flags = TM_FLAG_STREAM_TM|TM_FLAG_DETECT_TM;
}
配置初始化
函数调用堆栈如下: -> PreRunInit*(主模式和unix-socket模式的初始化代码) ->* FlowInitConfig*(初始化flow engine配置)*
FlowInitConfig 函数主要是完成线程回调函数的注册,为了后面启动线程做准备。部分代码及注释如下:
// 初始化flow引擎配置
void FlowInitConfig(char quiet)
{
SCLogDebug("initializing flow engine...");
// 清空FlowConfig结构体,然后进行初始化
memset(&flow_config, 0, sizeof(flow_config));
SC_ATOMIC_INIT(flow_flags);
SC_ATOMIC_INIT(flow_memuse);
SC_ATOMIC_INIT(flow_prune_idx);
SC_ATOMIC_INIT(flow_config.memcap);
// 初始化一个用于存放空闲流(预分配后或回收后)的flow_recycle_q
// 结构是FlowQueue,内部是一个标准的链式队列,适合存储容量未知的数据
FlowQueueInit(&flow_recycle_q);
// 设置默认值
flow_config.hash_rand = (uint32_t)RandomGet();
flow_config.hash_size = FLOW_DEFAULT_HASHSIZE;
flow_config.prealloc = FLOW_DEFAULT_PREALLOC;
SC_ATOMIC_SET(flow_config.memcap, FLOW_DEFAULT_MEMCAP);
// 从配置中读取emergency-recovery,memcap,hash-size,prealloc的值
// 填充flow_config结构体相应字段
// 如果我们有特殊的配置,就用它们覆盖默认配置,否则就保留默认值
intmax_t val = 0;
if (ConfGetInt("flow.emergency-recovery", &val) == 1) {
if (val <= 100 && val >= 1) {
flow_config.emergency_recovery = (uint8_t)val;
} else {
SCLogError(SC_ERR_INVALID_VALUE, "flow.emergency-recovery must be in the range of "
"1 and 100 (as percentage)");
flow_config.emergency_recovery = FLOW_DEFAULT_EMERGENCY_RECOVERY;
}
} else {
SCLogDebug("flow.emergency-recovery, using default value");
flow_config.emergency_recovery = FLOW_DEFAULT_EMERGENCY_RECOVERY;
}
// 检查我们是否在配置中定义了memcap和hash_size
const char *conf_val;
uint32_t configval = 0;
// 为memcap、prealloc和hash_size设置配置值
uint64_t flow_memcap_copy = 0;
if ((ConfGet("flow.memcap", &conf_val)) == 1)
{
// 按照hash_size为流表flow_hash分配内存,初始化各个bucket的锁,并将这个hash表大小记录到当前
// flow engine占用的内存flow_memuse中
flow_hash = SCMallocAligned(flow_config.hash_size * sizeof(FlowBucket), CLS);
if (unlikely(flow_hash == NULL)) {
FatalError(SC_ERR_FATAL,
"Fatal error encountered in FlowInitConfig. Exiting...");
}
memset(flow_hash, 0, flow_config.hash_size * sizeof(FlowBucket));
uint32_t i = 0;
for (i = 0; i < flow_config.hash_size; i++) {
FBLOCK_INIT(&flow_hash[i]);
SC_ATOMIC_INIT(flow_hash[i].next_ts);
}
(void) SC_ATOMIC_ADD(flow_memuse, (flow_config.hash_size * sizeof(FlowBucket)));
if (quiet == FALSE) {
SCLogConfig("allocated %"PRIu64" bytes of memory for the flow hash... "
"%" PRIu32 " buckets of size %" PRIuMAX "",
SC_ATOMIC_GET(flow_memuse), flow_config.hash_size,
(uintmax_t)sizeof(FlowBucket));
}
FlowSparePoolInit();
if (quiet == FALSE) {
SCLogConfig("flow memory usage: %"PRIu64" bytes, maximum: %"PRIu64,
SC_ATOMIC_GET(flow_memuse), SC_ATOMIC_GET(flow_config.memcap));
}
// 初始化支持所有协议的,默认超时、释放和流状态函数
FlowInitFlowProto();
线程启动
- SuricataMain -> RunModeDispatch(运行模式调度):判断传入参数
runmode保存的运行模式,进入对应分支,获取custom_mode。默认是AF_PACKET,对应函数为 RunModeAFPGetDefaultMode ,其中有三种用户模式single/workers/autofp,函数执行后返回默认模式workers。 - 获取了两个重要参数
runmode和custom_mode后,调用 RunModeGetCustomMode 函数,获取到运行模式结构体指针。函数原型如下:
// 运行模式的调度器函数,调用基于runmode和runmode_custom_id,所需的运行模式函数
static RunMode *RunModeGetCustomMode(enum RunModes runmode, const char *custom_mode)
-
若返回的指针不为空,则调用每种模式对应的 RunModeFun 函数。AF_PACKET/workers模式对应的处理函数是 RunModeIdsAFPWorkers
-
该函数会创建出suricata运行所需的主要线程,调用堆栈:RunModeIdsAFPWorkers -> RunModeSetLiveCaptureWorkers -> RunModeSetLiveCaptureWorkersForDevice,
-
- 其中创建的名为
W#01-eth0(eth0为网卡名)的线程,就是流管理引擎的核心线程,回调函数为FlowWorker FM#01是用来管理流表和超时流的线程,回调函数为FlowManager,
- 其中创建的名为
-
FR#01是管理超时流的线程,回调函数为FlowRecycler
线程介绍
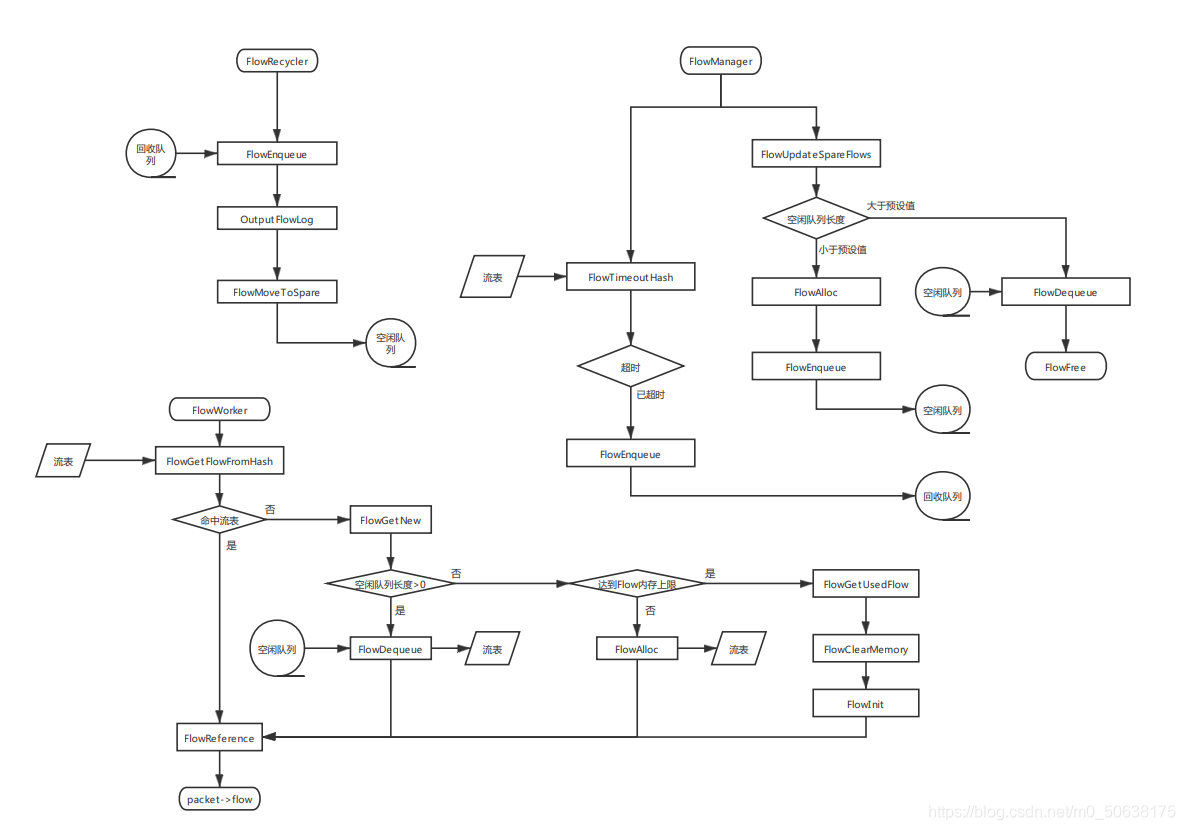
flow engine主要通过三个线程flow worker、flow manager、flow recycler,维护了flow hash(流表)、flow空闲队列、flow回收队列三个结构,用来存储不同状态的流。下面分别进行介绍
FlowWorker
处理新的数据包,在流表中查找对应的Flow结构,若存在则直接引用。若不存在,则按以下优先级获取一个新的Flow结构:
-
从空闲队列中取出一个
Flow结构 -
重新申请一个
Flow结构 -
从流表中取出一个当前未被引用的Flow结构,清空内容并重新插入流表
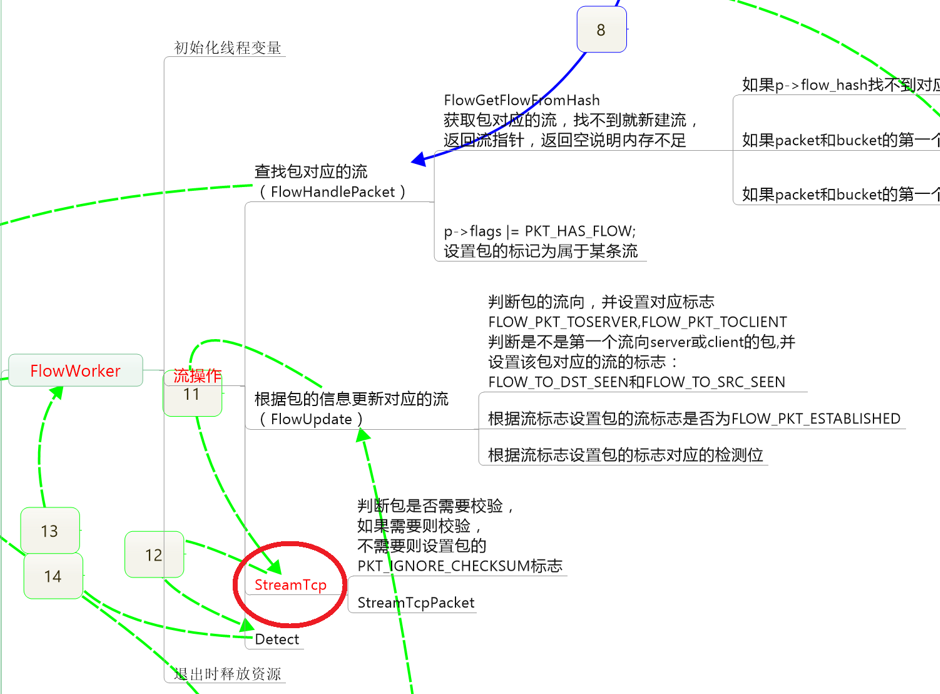
流查找/流分配 FlowHandlePacket
数据包流处理的入口点函数 FlowHandlwPacket ,用于为新数据包进行流查找和分配。主要逻辑由 FlowGetFlowFromHash 实现,该函数会返回一个Flow指针,表示找到的或新分配的流,函数实现在 flow-hash.c 文件,原型如下:
// 获取这个包对应的流,如果已经存在,则返回这个流的引用,
// 否则需要分配一个新的流。返回值Flow表示找到的或新分配的流
Flow *FlowGetFlowFromHash(ThreadVars *tv, FlowLookupStruct *fls,
const Packet *p, Flow **dest)

FlowGetFlowFromHash
函数的主要逻辑:用hash值经过计算作为索引,从流表中获取一个FlowBucket的指针。若head为空,说明还没有流,调用 FlowGetNew 分配一个新的流;若head不为空,则bucket中有流,尝试从Flow链表中查找该packet所属的流。截取部分代码进行说明:
/**
* 获取数据包的流
* 流的哈希检索函数。查找包含流指针的哈希桶,然后将数据包与找到的流进行比较,
* 看它是否是我们需要的流。如果不是,就遍历一遍列表,直到找到正确的流。如果
* 没有找到流或者数据包被删除,则从备用池中提取一个新流。只要不超过memcap
* 限制,池就会分配新流。
*/
Flow *FlowGetFlowFromHash(ThreadVars *tv, FlowLookupStruct *fls,
const Packet *p, Flow **dest)
{
Flow *f = NULL;
// 从流表flow_hash中获取一个FlowBucket的指针并上锁
const uint32_t hash = p->flow_hash;
FlowBucket *fb = &flow_hash[hash % flow_config.hash_size];
FromHashLockBucket(fb);
SCLogDebug("fb %p fb->head %p", fb, fb->head);
// 如果head为空,说明没有流
if (fb->head == NULL) {
// 需要分配一个流
f = FlowGetNew(tv, fls, p);
if (f == NULL) {
FBLOCK_UNLOCK(fb);
return NULL;
}
// 然后将它赋值给bucket并上锁
fb->head = f;
// 用Packet的信息初始化流
FlowInit(f, p);
f->flow_hash = hash;
f->fb = fb;
// 流状态更新,主要是更新流的时间,超时就是基于这个判断的
FlowUpdateState(f, FLOW_STATE_NEW);
// 指针指向新获取的流,并增加流的引用计数
FlowReference(dest, f);
FBLOCK_UNLOCK(fb);
return f;
}
// 如果head不为空,说明已经存在流。尝试从flow链表中查找packet所在的流
const bool emerg = (SC_ATOMIC_GET(flow_flags) & FLOW_EMERGENCY) != 0;
const uint32_t fb_nextts = !emerg ? SC_ATOMIC_GET(fb->next_ts) : 0;
// 验证bucket中的流,是否是需要的流
Flow *prev_f = NULL; /* previous flow */
f = fb->head;
do {
Flow *next_f = NULL;
const bool timedout =
(fb_nextts < (uint32_t)p->ts.tv_sec && FlowIsTimedOut(f, (uint32_t)p->ts.tv_sec, emerg));
if (timedout) {
// 遍历flow链表,如果找到了,移动到链表头部
FromHashLockTO(f);//FLOWLOCK_WRLOCK(f);
if (f->use_cnt == 0) {
next_f = f->next;
MoveToWorkQueue(tv, fls, fb, f, prev_f);
// 流保持锁定,所有权转移到MoveToWorkQueue
goto flow_removed;
}
FLOWLOCK_UNLOCK(f);
// 比较head flow与packet,如果匹配成功,则说明已经找到,并且这个流已经在头部不需要调整
} else if (FlowCompare(f, p) != 0) {
// 先锁定这个流
FromHashLockCMP(f);//FLOWLOCK_WRLOCK(f);
/* found a matching flow that is not timed out */
// 找到一个没有超时并且匹配的流
if (unlikely(TcpSessionPacketSsnReuse(p, f, f->protoctx) == 1)) {
f = TcpReuseReplace(tv, fls, fb, f, hash, p);
if (f == NULL) {
FBLOCK_UNLOCK(fb);
return NULL;
}
}
FlowReference(dest, f);
// 再解锁bucket,返回
FBLOCK_UNLOCK(fb);
return f; /* return w/o releasing flow lock */
}
// 除非我们删除了'f',否则当在下面添加一个新的流时,prev_f需要指向当前的'f'
prev_f = f;
next_f = f->next;
流更新 FlowUpdate
主要逻辑在 FlowUpdate -> FlowHandlePacketUpdate 函数,用来更新流的标志。截取部分代码:
// 获取数据包的方向。这里的方向是相对与流来说的,流的初始方向由流的第一个包决定,
// 若当前包与流的第一个包的方向一致(源端口或源地址相同),则方向为TOSERVER 正向
// 否则为TOCLIENT 反向
if (FlowGetPacketDirection(f, p) == TOSERVER) {
// 若数据包的方向为TOSERVER,则添加流状态标志FLOW_TO_DST_SEEN,
// 并且为数据包的flowflags添加FLOW_PKT_TOSERVER
f->todstpktcnt++;
f->todstbytecnt += GET_PKT_LEN(p);
p->flowflags = FLOW_PKT_TOSERVER;
if (!(f->flags & FLOW_TO_DST_SEEN)) {
if (FlowUpdateSeenFlag(p)) {
f->flags |= FLOW_TO_DST_SEEN;
p->flowflags |= FLOW_PKT_TOSERVER_FIRST;
}
}
/* xfer proto detect ts flag to first packet in ts dir */
if (f->flags & FLOW_PROTO_DETECT_TS_DONE) {
f->flags &= ~FLOW_PROTO_DETECT_TS_DONE;
p->flags |= PKT_PROTO_DETECT_TS_DONE;
}
FlowUpdateEthernet(tv, dtv, f, p->ethh, true);
} else {
// 否则流状态标志加上FLOW_TO_SRC_SEEN,包标志加上FLOW_PKT_TOCLIENT
if (f->flow_state == FLOW_STATE_ESTABLISHED) {
SCLogDebug("pkt %p FLOW_PKT_ESTABLISHED", p);
p->flowflags |= FLOW_PKT_ESTABLISHED;
} else if (f->proto == IPPROTO_TCP) {
TcpSession *ssn = (TcpSession *)f->protoctx;
if (ssn != NULL && ssn->state >= TCP_ESTABLISHED) {
p->flowflags |= FLOW_PKT_ESTABLISHED;
}
} else if ((f->flags & (FLOW_TO_DST_SEEN|FLOW_TO_SRC_SEEN)) ==
(FLOW_TO_DST_SEEN|FLOW_TO_SRC_SEEN)) {
SCLogDebug("pkt %p FLOW_PKT_ESTABLISHED", p);
// 如果流flags的FLOW_TO_DST_SEEN和FLOW_TO_SRC_SEEN都被设置了
// 说明流已经建立,给包添加FLOW_PKT_ESTABLISHED标志
p->flowflags |= FLOW_PKT_ESTABLISHED;
FlowUpdateState(f, FLOW_STATE_ESTABLISHED);
}
// 绕过包检测
if (f->flags & FLOW_NOPACKET_INSPECTION) {
SCLogDebug("setting FLOW_NOPACKET_INSPECTION flag on flow %p", f);
DecodeSetNoPacketInspectionFlag(p);
}
// 绕过负载检测
if (f->flags & FLOW_NOPAYLOAD_INSPECTION) {
SCLogDebug("setting FLOW_NOPAYLOAD_INSPECTION flag on flow %p", f);
DecodeSetNoPayloadInspectionFlag(p);
}
/* update flow's ttl fields if needed */
// 如果需要的话,更新流的ttl字段
if (PKT_IS_IPV4(p)) {
FlowUpdateTTL(f, p, IPV4_GET_IPTTL(p));
} else if (PKT_IS_IPV6(p)) {
FlowUpdateTTL(f, p, IPV6_GET_HLIM(p));
}
FlowManager
从流表中摘除超时的流放入回收队列。
检查空闲队列长度是否为预设值,若过长则释放一部分,过短则申请一部分。
-
检查flow_flags是否为 FLOW_EMERGENCY 标志,表示进入紧急状态
-
检查是否还有空闲流
-
调用 FlowTimeoutHash 和 FlowTimeoutHashInChunks 进行实际的流超时处理
流超时 FlowTimeoutHash
-
循环遍历整个hash表,获取FlowBucket。
-
若尝试锁上FlowBucket失败,说明有其他线程正在操作,则跳过继续循环。
-
若这个bucket上没有流,则解锁,继续循环。
-
调用 FlowManagerHashRowTimeout 进行处理
-
扫描完整个hash表后,退出,返回值为删除的超时流数目。
FlowTimeoutHashInChunks
非紧急状态调用的流超时处理函数,内部也是调用了 FlowTimeoutHash 函数
FlowRecyler
从回收队列中摘除flow,调用注册flow输出模块的回调,清空Flow信息,插入回收队列
附1:流管理三大线程流程图(来源见水印)
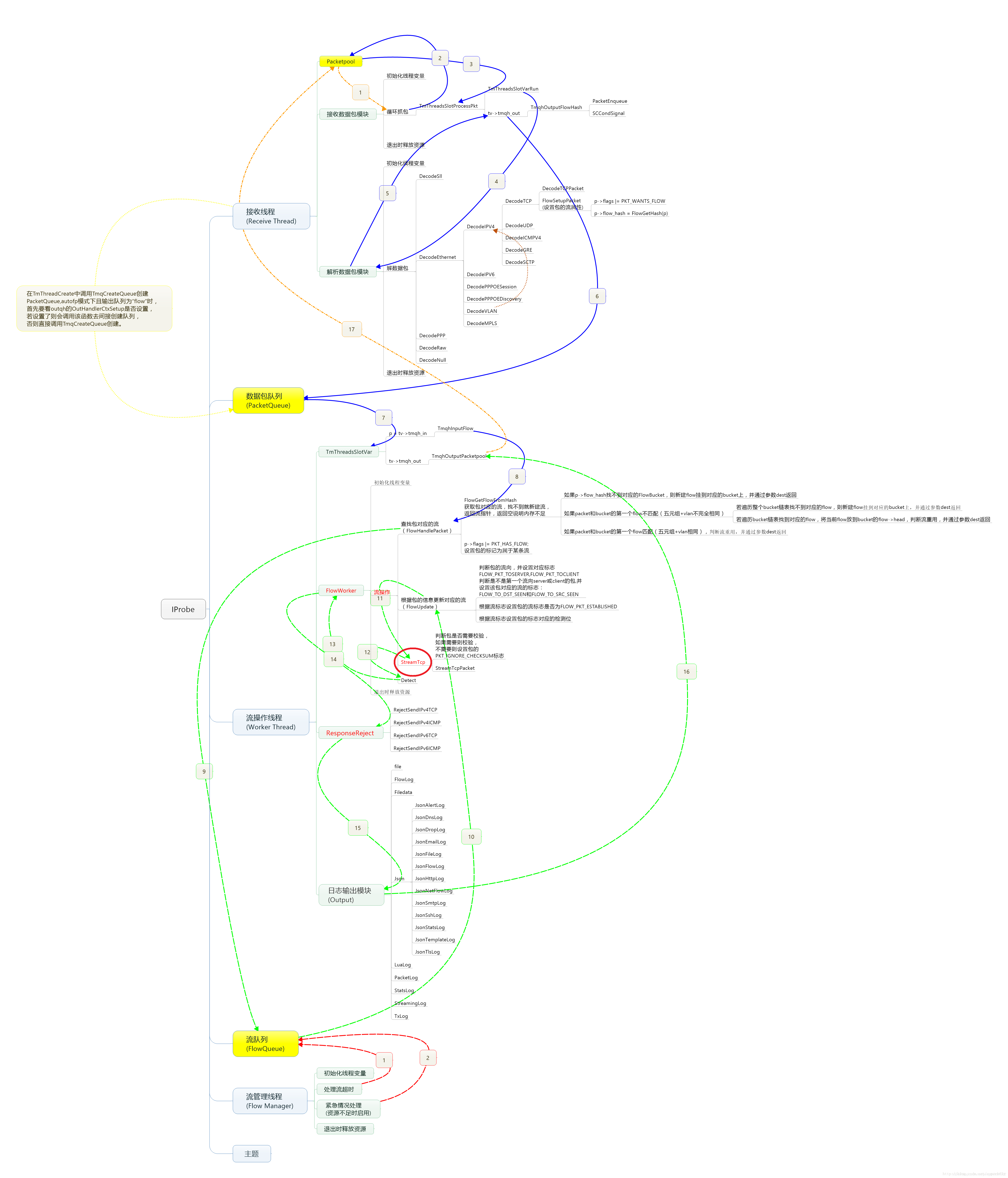
附2:Suricata整体流程图(来源看不清了,右下角好像有水印)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号