OCR深度实践系列(四):文本识别
https://zhuanlan.zhihu.com/p/334340972
(一)图像预处理
(二)数据生成
(三)文本检测
最近在攻关法律领域的类案检索系统,这几天正好忙完了,得空继续写《OCR深度实践系列》这一专题的文章。前面三章依次介绍了图像预处理、数据生成以及文本检测三个模块,本章将介绍第四个关键模块:文本识别。
本文项目地址:https://github.com/Vincent131499/Chinese-OCR3/tree/master/text_recognize

经过文字检测之后我们就可以获得文字区域的位置,此时就可以借助各类文字识别算法来转译这些文字区域的内容。在以前的OCR任务中,识别过程分为两步:单字分割和分类任务,即:首先利用投影法将一连串文字切割出单个字体然后再送入CNN里面进行文字分类。而现在流行的基于深度学习的端到端文字识别方法不需要文字切割这个环节,它将文字识别转换成序列学习问题,虽然输入图像尺度和文本长度不同,但经过特征网络处理后就可以对整个文本图像进行识别(文字切割融入到深度学习中)。
近年来随着深度学习的迅猛发展,针对**场景文字识别(Scene Text Recognition,STR)**逐渐形成两种主流方法:一种是基于CTC的方法,典型代表是CRNN,即CRNN-OCR;另一种是基于Attention的方法,即Attention-OCR。其实这两类方法主要区别在于最后的输出层,即如何将网络学习到的序列特征信息转化为最终的识别结果。这两类方法在特征学习阶段都采用了CNN+RNN的网络结构,而CRNN-OCR在对齐时采用的是CTC算法,而Attention-OCR采用的是attention机制。
本文作为入门篇,主要介绍应用较为广泛的经典算法模型,包括CRNN、RATE以及端到端的两个模型。
1.CRNN模型
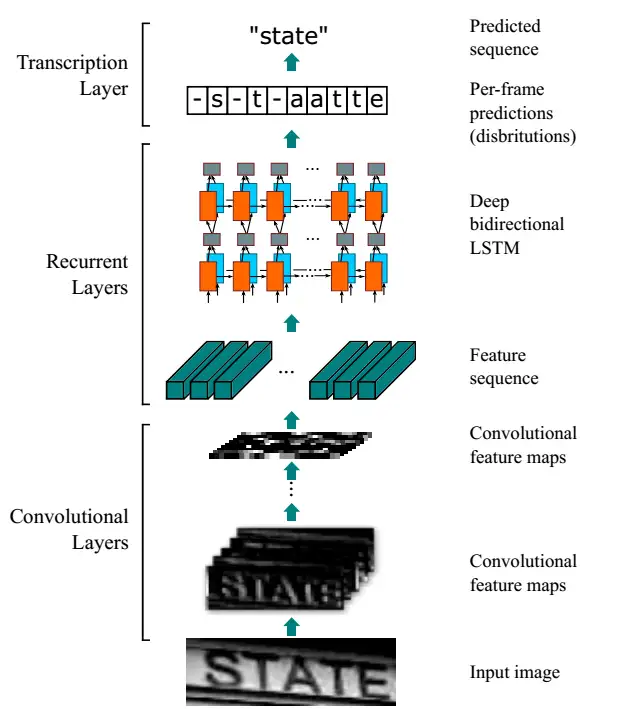
CRNN(Convolutional Recurrent Neural Network)[1]是目前最为流行的文本识别模型之一,可以识别不定长文本序列。如下图所示,网络结构包含三个部分,从下到上依次为:
- 卷积层:使用CNN从输入图像中提取特征序列;
- BiLSTM序列层:用BiLSTM将特征向量进行融合以提取字符序列的上下文特征,然后得到每列特征的概率分布;
- 转录层:使用CTC把从BiLSTM获取的标签分布通过去重整合等操作转换成最终的识别结果。
2.RARE模型
RARE(Robust text renognizer with Automatic Rectification)模型[2]在识别变形的图像文本时效果很好。网络流程如下图所示,针对输入图像,模型首先对其进行空间变换网络处理达到矫正的目的,随后将矫正过的图像送入序列识别网络中得到文本预测结果。

其中,空间变换网络结构如下图所示,内部包括定位网络、网格生成器、采样器三个子结构。经过训练后,它可以根据输入图像的特征图动态地产生空间变换网格,然后采样器根据变换网格核函数从原始图像中采样获得一个矩形的文本图像。RARE中支持一种称为TPS(thin-plate splines)的空间变换,从而能够比较准确地识别透视变换过的文本、以及弯曲的文本。

3.端到端模型
对于现有的字符识别任务来说,若字符区域不充满整张图片,那么字符识别的效果将会出现灾难性的下滑,因此仍然需要字符检测任务作为字符识别的前置任务,检测结果的好坏直接决定识别结果的好坏。但是检测模型与识别模型是两个独立的模型,因此计算量和消耗的时间会大幅增加。近年来,有学者尝试将两个任务合并到一起实现,这不仅可以使多任务模型相互补足,也能使计算量得到一定程度的降低。
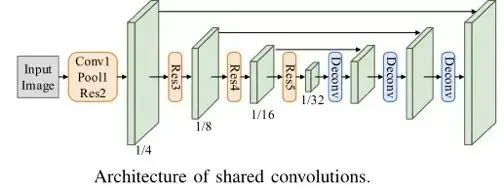
(1)FOTS Rotation-Sensitive Regression
FOTS(Fast Oriented Text Spotting)是图像文本检测与识别同步训练、端到端可学习的网络模型。检测和识别任务共享卷积特征层,既节省了计算时间,也比两阶段训练方式学习到更多图像特征。引入了旋转敏感区域,可以从卷积特征图中产生定向得到文本区域,从而支持倾斜文本的识别。

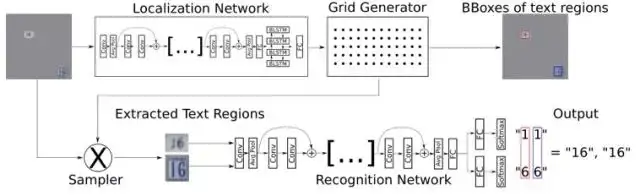
(2)STN-OCR模型
STN-OCR同样是端到端的集成图像文本检测和识别的可学习模型。模型架构如下图所示,检测部分嵌入了一个空间变换网络(STN)来对原始输入图像进行仿射(affine)变换。利用这个空间变换网络,可以对检测到的多个文本块分别执行旋转、缩放和倾斜等图形矫正动作,进而促进后面的文本识别取得更好的识别精度。在训练上STN-OCR属于半监督学习方法,只需要提供文本内容标注,而不要求文本定位信息。作者也提到,如果从头开始训练则网络收敛速度较慢,因此建议渐进地增加训练难度。STN-OCR已经开放了工程源代码和预训练模型。
4.实战演示
接下来本文将以经典的CRNN模型为例讲解文本识别的训练-推理实战演示。
该项目位于Chinese-OCR3/text_recognize/crnn_chinese。
(1)数据集
step1:下载训练数据(下载地址:链接:https://pan.baidu.com/s/16oM4qlWu-SUCu8A-b_PDug 提取码:phhy )
step2:下载标签数据(下载地址:链接:https://pan.baidu.com/s/14gagbl60tyC2w3qsaRSAQw 提取码:n52k)
step3:修改配置文件lib/config/360CC_config.yaml,将训练数据集的根目录换成本地数据集的路径
DATASET
ROOT: 'to/your/images/path'
step4:将下载的标签数据中的char_std_5900.txt放入lib/dataset/txt/
step5:将下载的标签数据中的train.txt和test.txt放入lib/dataset/txt/
数据简介:
- 共约364万张图片,按照99:1划分成训练集和验证集。
- 数据利用中文语料库(新闻 + 文言文),通过字体、大小、灰度、模糊、透视、拉伸等变化随机生成
- 包含汉字、英文字母、数字和标点共5990个字符(字符集合:https://github.com/YCG09/chinese_ocr/blob/master/train/char_std_5990.txt )
- 每个样本固定10个字符,字符随机截取自语料库中的句子
- 图片分辨率统一为280x32
(2)训练
训练命令:
python train.py --cfg lib/config/360CC_config.yaml
查看训练过程的loss变化:
cd output/360CC/crnn/xxxx-xx-xx-xx-xx/
tensorboard --logdir log
注意:支持定长训练。但是可以修改数据加载器以支持随机长度训练。
(3)推理
运行命令:
python demo.py --image_path readme_images/test.png --checkpoint output/checkpoints/mixed_second_finetune_acc_97P7.pth

(4)自定义数据集
若想使用自己的数据来训练一个CRNN文本识别模型,只需更改配置文件即可。
step1:编辑配置文件lib/config/OWN_config.yaml,将训练数据集的根目录换成本地数据集的路径
DATASET:
ROOT: 'to/your/images/path'
step2:将训练集train_own.txt和测试集test_own.txt放入lib/dataset/txt/
数据集样例:test_own.txt
20456343_4045240981.jpg 你好啊!祖国!
20457281_3395886438.jpg 晚安啊!世界!
...
随后就可以继续上面的训练和推理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号