dubbo 限制方法线程数_不可忽视的Dubbo线程池避坑指南
转载:https://blog.csdn.net/weixin_39574140/article/details/110193195?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-110193195-blog-121764780.235%5Ev27%5Epc_relevant_recovery_v2&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-110193195-blog-121764780.235%5Ev27%5Epc_relevant_recovery_v2&utm_relevant_index=1
问题描述
-
线上突然出现Dubbo超时调用,时间刚好为Consumer端设置的超时时间。
-
有好几个不同的接口都报超时了
-
第1次调用超时,第2次(或第3次)重试调用非常快(正常水平)
-
Dubbo调用超时的情况集中出现了3次,每次都是过一会自动恢复
看到调用超时,首先就拿着traceId去服务提供方查日志。 奇怪的是,在服务提供方的业务日志里面,只有正常的调用日志(耗时正常),没有超时调用的日志。 从正常的调用日志里面看,一切都是正常的,看不出所以然。 给人的感觉就是超时那次请求的调用没有达到服务提供方。
通过系统历史监控,我们发现除了gc比平时稍微高一点外(也在正常水位),没有其他的异常;CPU、内存、网络等指标都在正常范围。
第2次系统集中超时报警的做的第一件事就是登录到那台服务器查看dubbo线程活动情况:看下能不能找到阻塞在哪一行代码。很遗憾,所有的dubbo线程都没有阻塞,都是正常的WAITING状态。
并没有明显表明阻塞在某段代码,这可难倒我们了:如果没有阻塞的话,为什么dubbo调用方会报超时?继续看代码
硬着头皮重新看代码每一个分支,突然发现底层的一个方法中有http调用!会不会是这个http调用导致的超时?如果是的话,那么不同的接口调用超时的情况就说的通了,因为上层大部分接口都会调用这个底层方法。
怀揣着激动的心,仔细看了http调用的逻辑:用的是JDK提供的HttpURLConnection,其中只用了HttpURLConnection#getContentLength方法,并且也在finally代码块中将这个连接关闭了。好像也不是这个引起的,起初还以为getContentLength会把文件给下载下来,但是看了接口文档以后发现只会去读头信息中的ContentLength。
/** * Returns the value of the {@code content-length} header field. *
* Note: {@link #getContentLengthLong() getContentLengthLong()} * should be preferred over this method, since it returns a {@code long} * instead and is therefore more portable.
* * @return the content length of the resource that this connection's URL * references, {@code -1} if the content length is not known, * or if the content length is greater than Integer.MAX_VALUE. */ public int getContentLength() { long l = getContentLengthLong(); if (l > Integer.MAX_VALUE) return -1; return (int) l; }
代码阻塞的情况可能性也不大,因为重试请求不会超时:如果代码阻塞,那么重试请求大概率也会超时。
既然代码没有阻塞,那么有没有可能是数据访问层的异常造成的呢?毕竟不止一个接口存在超时的问题,如果是底层数据访问层的异常导致,那么也说得通。
重点排查了mysql,但结果是令人失望的:并没有慢SQL;并且dubbo超时期间,mysql实例的CPU和内存水位都是正常的。
除了mysql、redis实例本身指标正常外,基于上面同样的理由:如果数据访问层有问题,那么重试基本上也会超时。所以数据访问层导致超时的线索也被排除。
排查再次陷入僵局,逼迫着我们重新梳理排查思路:
-
除了代码阻塞
-
除了数据访问层异常
-
除了超时请求,其他请求的日志都是正常的
那么还有可能会导致超时呢?会不会是Dubbo本身异常导致的?
此时有一个关键的线索进入我们的视野:超时的那次请求去哪儿了?
在服务提供方的日志里面没有超时请求的的日志,只有重试请求成功的业务日志。太奇怪了,就算超时总的留下日志的吧,日志都不留,欺负我胖虎吗?!
到这里想到超时的请求可能是一个突破口,于是开始看Dubbo的相关的源码和文档。
从官方文档中的服务端调用链一层层往下查

在AllChannelHandler源码中看到了令人兴奋的注释:
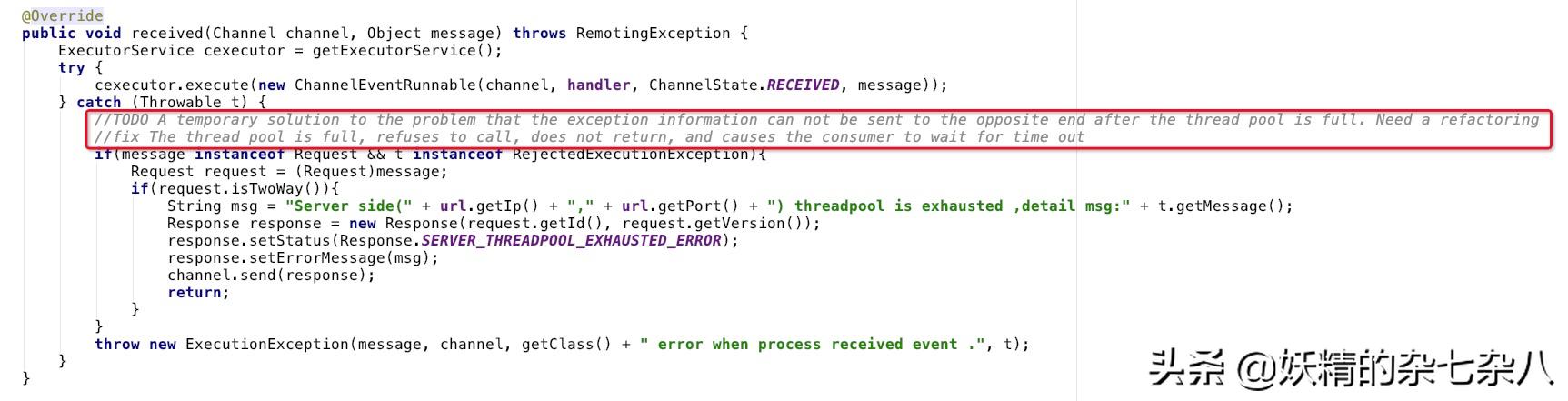
兴奋之余,为了避免理解偏差,还特地用百度翻译了一下
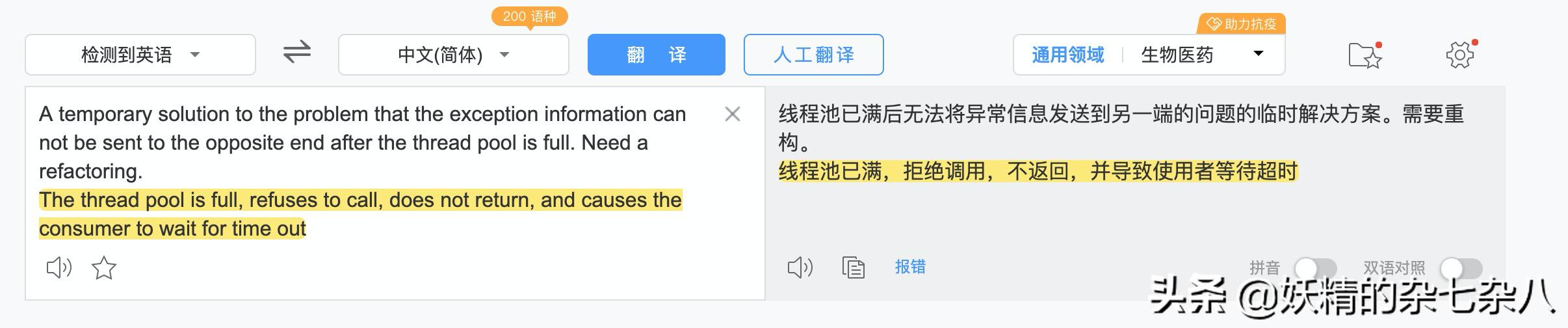
没错,如果线程池已经满了,那么服务端不会返回,直到客户端超时!这不是正式我们碰到的问题吗?! 并且此时还没有进入业务代码,所以没有打印业务日志,这样就可以解释为什么没有服务提供方没有超时请求的日志了。
别激动,这里明明有返回threadpool is exhausted异常信息,怎么能说没有返回呢? 别急,这是另外一个项目引用的dubbo,版本是2.6.2。 回到出问题的那个项目,查看dubbo版本:2.8.6,查看AllChannelHandler源码:是的在2.8.6版本中,并没有返回这个错误
问题好像找到了,OK,剩下的就是验证了。
-
将DubboServerHandler线程池的最大线程数调到5
-
使用Apache Bench进行压测:200请求、并发10个线程
-
Dubbo使用2.8.6版本
-
预期:部分请求超时报错,重试耗时正常
-
压测结果符合预期:部分接口报错超时,并且重试请求耗时正常
-
Dubbo使用2.6.2版本
-
预期:部分请求报错线程池耗尽threadpool is exhausted,并且重试大概率也会报该错误
-
压测结果符合预期
至此,基本判定线上Dubbo调用超时的问题就是因为线程池耗尽引起的。
这个超时问题前前后后查了一周左右,排查过程中试了很多排查方向,为了叙述方便就没有展开。
避坑指南
-
合理设置Dubbo线程池大小。默认是200
-
合理设置超时时间。如果真出现了Dubbo调用超时的情况,合理的超时时间能够避免服务调用方被打爆
-
Dubbo接口必须有返回值。从AllChannelHandler#received的源码和注释中可以看到只有有返回值的接口才会返回线程池耗尽的错误信息;其它的情况则不会将错误信息返回给调用方,直到调用方超时。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号