3.Java线程同步机制
一.线程同步机制简介
从广义上说,Java平台提供的线程同步机制包括:锁、volatile关键字、final关键字、static关键字以及一些相关的API,如Object.wait()/Object.notify()等。
二.锁概述
线程安全问题产生的前提是多个线程并发访问共享变量、共享资源(统称共享数据)。一种保障线程安全的方法是将多个线程对共享数据的并发访问转换为串行访问,即一个共享数据一次只能被一个线程访问,该线程访问结束后其他线程才能对其进行访问。锁(Lock)就是利用这种思路以保障线程安全的线程同步机制。
一个线程在访问共享数据前必须申请相应的锁,一个锁一次只能被一个线程持有。锁的持有线程可以对该锁所保护的共享数据进行访问,访问结束后该线程必须释放(Release)相应的锁。锁的持有线程在其获得锁之后和释放锁之前这段时间内所执行的代码被称为临界区(Critical Section)。因此,共享数据只允许在临界区内进行访问,临界区一次只能被一个线程执行。
锁具有排他性(Exclusive),即一个锁一次只能被一个线程持有。这种锁被称为排他锁或者互斥锁(Mutex)。还有一种读写锁,可看作是对排他锁的一种相对改进。
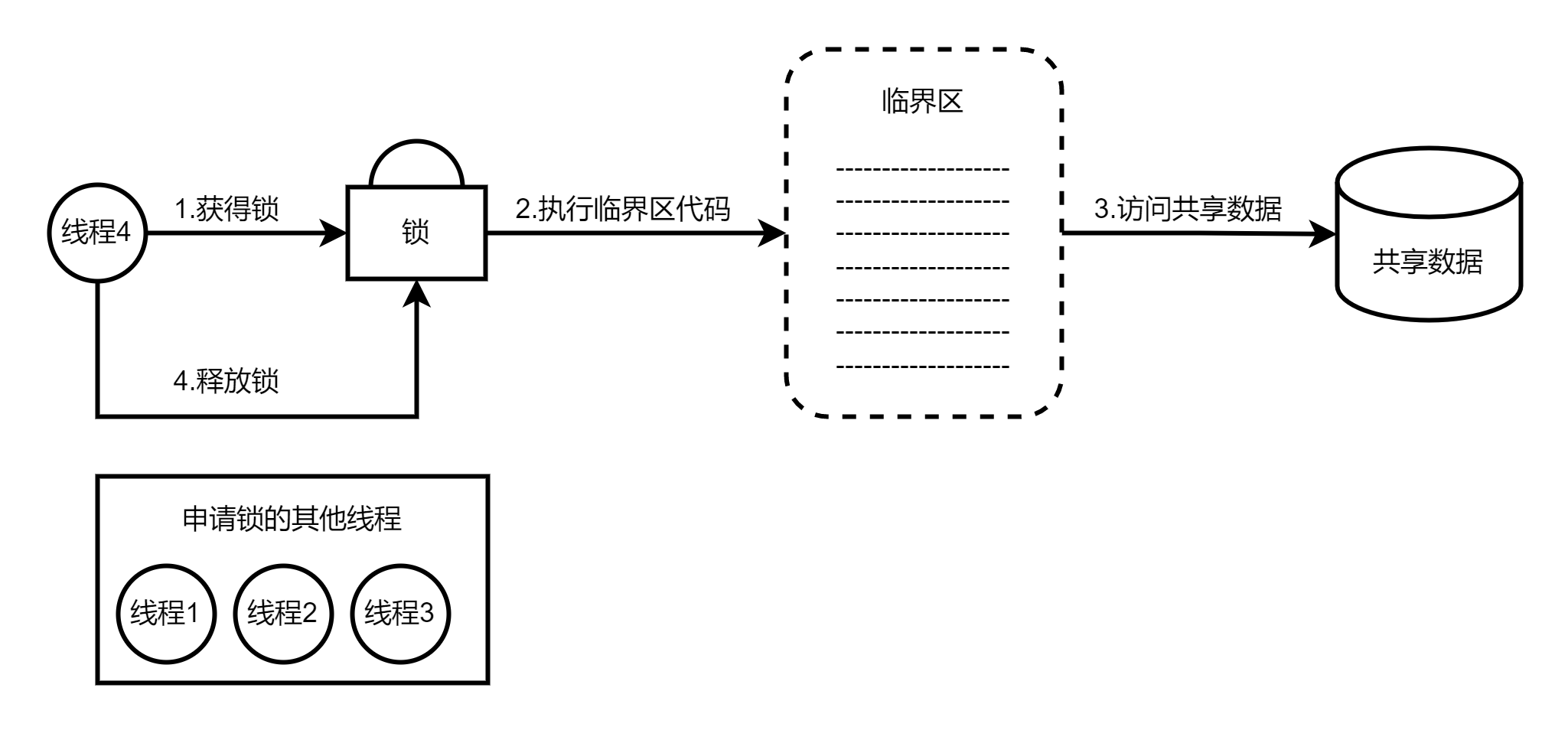
2-1 互斥锁示意图
2-1 锁的作用
锁能够保护共享数据以实现线程安全,其作用包括保障原子性、可见性和有序性。
1.保障原子性
锁是通过互斥保障原子性的。互斥(Mutual Exclusion)是指一个锁一次只能被一个线程持有。因此一个线程持有一个锁的时候,其他线程无法获得该锁,而只能等待其释放该锁后再申请。这就保证了临界区代码一次只能够被一个线程执行。因此,一个线程执行临界区期间没有其他线程能够访问相应的共享数据,使得临界区代码所执行的操作具有不可分割的特性,即具备了原子性。
- 在其他线程看来,临界区(同一个锁锁住的多个代码块)中的操作要么是没执行,要么是执行完毕了。因为一个锁一次只能被一个线程持有且执行完毕持有者线程才会释放锁(互斥)。
- 临界区中的操作不能被多个线程交替执行。因为执行临界区的代码需要先获取锁,一个锁一次只能被一个线程持有且执行完毕持有者线程才会释放锁(互斥)。
2.保障可见性
可见性的保障是通过写线程冲刷处理器缓存和读线程刷新处理器缓存这两个动作实现的。
在Java平台中,锁的获得隐含着刷新处理器缓存这个动作,这使得读线程在执行临界区代码前(获得锁之后)可以将写线程对共享变量所作的更新同步到读线程执行处理器的高速缓存中;锁的释放隐含着冲刷处理器缓存这个动作,这使得写线程对共享变量所作的更新能够被“推送”到该线程执行处理器的高速缓存中,从而对读线程可同步。
锁的互斥性及其对可见性的保障合在一起,可保证临界区内的代码能够读取到共享数据的最新值。由于锁的互斥性,同一个锁所保护的共享数据一次只能够被一个线程访问,因此线程在临界区中所读到共享数据的相对新值(锁对原子性和可见性保障的结果)同时也是最新值。
锁不仅能够保障临界区中共的代码能够读取到共享变量的最新值。对于引用型共享变量,锁还可以保障临界区中的代码能够读取到该变量所引用对象的字段(实例变量和静态变量)的最新值。这点可以推广到数组变量,即如果共享变量是个数组,那么锁能够保障临界区中的代码可以读取到该数组中各个元素的最新值。
- 前提是系统中不能存在对共享变量所引用的对象(数组)进行不加同一个锁的访问。
3.保障有序性
锁能够保障有序性。写线程在临界区中共所执行的一系列操作在读线程所执行的临界区看起来像是完全按照源代码顺序执行的,即读线程对这些操作的感知顺序与源代码顺序一致。这是锁对原子性和可见性保障的结果。
设写线程在临界区中更新了b、c和flag这3个共享变量。
// 临界区 { b = a + 1; c = 2; flag = true; }
由于锁对可见性的保障,写线程在临界区中对上述任何一个共享变量所做的更新都对读线程可见。并且,由于临界区内的操作具有原子性,因此写线程对上述共享变量的更新结果会同时对读线程可见,即在读线程看来这些变量就像是在同一刻被更新的。因此读线程并无法(也没有必要)区分写线程实际上以什么顺序更新上述变量的,这意味着读线程可以认为写线程是依照源代码顺序更新上述共享变量的,即有序性得以保障。
由于锁能够保障有序性,因此对于上述例子,可有:如果一个读线程在临界区中读取到变量c的值为2,那么flag的值必然为true,b的值必然比a的值大1;如果一个线程在临界区中读到变量flag的值为true,那么c的值必然为2,b的值必然比a的值大1......
尽管锁能够保障有序性,但这并不意味着临界区内的内存操作不能够被重排序。临界区内任意两个操作可以在临界区之内被重排序(即不会重排到临界区之外)。由于临界区内的操作具有的原子性,写线程在临界区内对各个共享数据的更新同时对读线程可见,因此这种重排序并不会对其他线程产生影响。
4.锁保障原子性、可见性和有序性的条件
锁对可见性、原子性和有序性的保障是有条件的,需要同时保证以下两点得以满足。
- 这些线程在访问同一组共享数据的时候必须使用同一个锁。
- 这些线程中任意一个线程,即使其仅仅是读取这组共享数据而没有对其进行更新的话,也需要在读取时持有相应的锁。
2-2 与锁相关的几个概念
1.可重入性
可重入性(Reentrancy)描述的是:一个线程在持有一个锁的时候能否再次(或者多次)申请该锁。如果一个线程持有一个锁的时候还能够继续成功申请该锁,那么就称该锁是可重入的(Reentrant),否则就称该锁为非可重入的(Non-reentrant)。
可重入性问题可由如下伪代码来理解:
void methodA() { // 申请锁lock acquireLock(lock); // 省略其他代码 methodB(); // 释放锁lock releaseLock(lock); } void methodB() { // 申请锁lock acquireLock(lock); // 省略其他代码 // 释放锁lock releaseLock(lock); }
如果锁lock是可重入的,那么methodB中能成功申请锁,methodB中释放锁的时候也不会导致锁lock被完全释放(因为methodA中还未释放)。
可重入锁的实现
可重入锁可以被理解为一个对象,该对象包含一个计数器属性。计数器属性的初始值为0,表示相应的锁还没有被任何线程持有。每次线程获得一个可重入锁的时候,该锁的计数器值会被增加1。每次一个线程释放锁的时候,该锁的计数器属性值就会被减1。一个可重入锁的持有线程初次获得该锁时相应的开销相对大,这是因为该锁的持有线程必须与其他线程“竞争”以获得锁。可重入锁的持有线程继续获得相应锁产生的开销要小得多,这是因为此时Java虚拟机只需要将相应锁的计数器属性增加1即可以实现锁的获得。
2.锁的争用与调度
锁可以被看作多线程程序访问共享数据时所需要持有的一种排他性资源。因此,资源的争用、调度的概念也对锁适用。
Java平台中锁的调度策略也包括公平策略和非公平策略,相应的锁就被称为公平锁和非公平锁。內部锁属于非公平锁,而显示锁则既支持公平锁又支持非公平锁。
3.锁的粒度
一个锁实例可以保护一个或多个共享数据。一个锁实例所保护的共享数据的数据量大小就被称为该锁的粒度(Granularity)。一个锁实例保护的共享数据的数据量大,我们就称该锁的粒度粗,否则就称该锁的粒度细。
锁的粒度过粗会导致线程在申请锁的时候进行不必要的等待(等待不同共享变量的线程都会在这个粒度粗的锁上等待)。锁的粒度过细会增加锁调度的开销。
2-3 锁的开销及其可能导致的问题
锁的开销包括锁的申请和释放所产生的开销,以及锁可能导致的上下文切换的开销。这些开销主要是处理器时间。
锁可能导致上下文切换。多个线程争用排他性资源可能导致上下文切换,因此,锁作为一种排他性资源,一旦被争用就可能导致上下文切换。
三.内部锁:synchronized关键字
Java平台中的任何一个对象都有唯一一个与之关联的锁。这种锁被称为监视器(Monitor)或者内部锁(Intrinsic Lock)。内部锁是一种排他锁,它能够保障原子性、可见性和有序性。
内部锁是通过synchronized关键字实现的。synchronized关键字可以用来修饰方法以及代码块。
synchronized修饰代码块时,锁句柄通常采用final修饰。这是因为锁句柄变量的值一旦改变,会导致执行同一个同步块的多个线程实际上使用不同的锁,从而导致竞态。作为锁句柄的变量通常采用private final 修饰,如:private final Object handle= new Object();
同步实例方法相当于以“this”为引导锁的同步块。同步静态方法相当于以当前类对象(Class对象)(Java中的类本身也是一个对象)为引导锁的同步块。
public class SynchronizedMethodExample { // 同步实例方法 synchronized void instanceMethod() { // 省略方法体 } void instanceMethodEquivalent() { synchronized (this) { // 省略方法体 } } // 同步静态方法 static synchronized void staticMethod() { // 省略方法体 } static void staticMethodEquivalent() { synchronized (SynchronizedMethodExample.class) { // 省略方法体 } } }
线程对内部锁的申请与释放的动作由Java虚拟机负责,这正是synchronized实现的锁被称为内部锁的原因。
內部锁的使用不会导致锁泄漏。因为javac在将同步块代码编译为字节码的时候,对临界区中可能抛出的而程序代码中又未捕获的异常进行了特殊(代为)处理,这使得临界区的代码即使抛出异常也不会妨碍内部锁的释放。
内部锁的调度
Java虚拟机会为每个内部锁分配一个入口集(Entry Set)(类似于排他资源的等待队列),用于记录等待获得相应内部锁的线程。多个线程申请同一个锁的时候,只有一个申请者能够成为该锁的持有线程(即申请锁的操作成功),而其他申请者的申请操作会失败。这些申请失败的线程不会抛出异常,而是会被暂停(生命周期状态变为BLOCKED)并被存入相应锁的入口集中等待再次申请锁的机会。入口集中的线程就被称为相应内部锁的等待线程。当这些线程申请的锁被其持有者线程释放的时候,该锁的入口集中的一个任意线程会被Java虚拟机唤醒,从而得到再次申请锁的机会。
由于Java虚拟机对内部锁的调度仅支持非公平调度,被唤醒的等待线程占用处理器运行时(BLOCKED->READY->RUNNING)可能还有其他新的活跃线程(处于RUNNING状态,且未进入过入口集)与该线程抢占这个被释放的锁,因此被唤醒的线程不一定就能成为该锁的持有线程。
四.显示锁:Lock接口
显示锁是自JDK1.5开始引入的排他锁。
显示锁(Explicit Lock)是java.util.concurrent.locks.Lock接口的实例。该接口对显式锁进行了抽象,类java.util.concurrent.locks.ReentrantLock是Lock接口的默认实现类。
一个Lock接口的实例就是一个显式锁对象,Lock接口定义的lock方法和unlock方法分别用于申请和释放相应Lock实例表示的锁。显式锁的使用方法如下所示:
// 创建一个Lock接口实例 private final Lock lock = ...; ... // 申请锁lock lock.lock(); try { // 在此对共享数据进行访问 } finally { // 总是在finally块中释放锁,以避免锁泄漏 // 释放锁lock lock.unlock(); }
4-1 显式锁的调度
ReentrantLock既支持非公平锁也支持公平锁。ReentrantLock的一个构造器的签名如下:ReentrantLock(boolean fair),该构造器使得在创建显式锁实例的时候可以指定相应的锁是否是公平锁(fair参数为true表示是公平锁)。
公平锁保障锁调度的公平性往往会增加上下文切换的可能性,因此,公平锁适用于锁被持有的时间相对长的情形。总的来说使用公平锁的开销比使用非公平锁的开销要大,因此显式锁默认使用的是非公平调度策略。
4-2 显式锁与内部锁的比较
内部锁是基于代码块的锁,因此其使用基本无灵活性可言。而显式锁是基于对象的锁,其使用可以充分发挥卖你想对象编程的灵活性。比如,内部锁的申请与释放只能是在一个方法内进行(因为代码块无法跨方法),而显式锁支持在一个方法内申请锁,却在另一个方法里释放锁。
内部锁基于代码块的这个特征也使其具有简单易用,不会导致锁泄漏的优势。
在锁的调度方面,内部锁仅支持非公平锁;而显式锁既支持非公平锁也支持公平锁。
如果一个内部锁的持有线程一致不释放这个锁(这通常是由于代码错误导致的),那么同步在该锁之上的所有线程就会一直被暂停。而显式锁则可以避免这样的问题。Lock接口定义了一个tryLock的方法。该方法的作用是尝试申请相应Lock实例所表示的锁。如果相应的锁未被其他任何线程持有,那么该方法会返回true,表示其获得了相应的锁;否则,该方法不会导致其执行线程被暂停而是直接返回false,表示其未获得相应得锁。tryLock方法使用方法如下代码模板所示:
Lock lock = ...; if (lock.tryLock()) { try{ // 在此访问共享数据 } finally { lock.unlock; } } else { // 执行其操作 }
tryLock另外一个签名版本:
boolean tryLock(long time, TimeUnit unit);
这个版本的tryLock方法使得我们可以指定一个时间。如果当前线程没有在指定时间内成功申请到相应的锁,那么tryLock方法就直接返回false。
显式锁提供了一些方法可以用来对锁的相关信息进行监控,而内部锁不支持这种特性。ReentrantLock中定义的方法isLocked()可用于检测相应的锁是否被某个线程持有(Thread.holdsLock(Object)只能检测当前线程是否持有特定的内部锁),getQueueLength()方法可用于检查相应锁的等待线程的数量。
4-3 锁的选用
一般来说,新开发的代码中可以选用显式锁。但是选用显式锁时需要注意:显式锁的不正确使用会导致锁泄漏;线程转储可能无法包含显式锁相关的信息,从而导致定位问题困难(使用jstack可避免)。
另外,也可以使用相对保守的策略——默认情况下选用内部锁,仅在需要显式锁提供的特征时才使用显式锁。比如,在多数线程持有一个锁的时间相对长的情况下使用仅支持非公平策略的内部锁是不恰当的,可以考虑使用公平策略的显式锁。
4-4 改进型锁:读写锁
锁的排他性使得多个线程无法以线程安全的方式在同一时刻对共享变量进行读取(只是读取而不是更新),这不利于提高系统的并发性。
1.读写锁的概念及使用
读写锁(Read/Write Lock)是一种改进型的排他锁,也被称为共享/排他锁(Shared/Exclusive)锁。读写锁允许多个线程可以同时读取(只读)共享变量,但是一次只允许一个线程对共享变量进行更新(包括读取后再更新)。
- 读-写互斥、写-写互斥、读-读共享。
读写锁的功能是通过其扮演的两个角色——读锁(Read Lock)和写锁(Write Lock)实现的。读线程在访问共享变量的时候必须持有相应读写锁的读锁。写线程在访问共享变量的时候必须持有相应读写锁的写锁。
| 获得条件 | 排他性 | 作 用 | |
| 读锁 | 相应的写锁未被任何线程持有 | 对读线程是共享的,对写线程是排他的 | 允许多个读线程可以同时读取共享变量,并保障读线程读取共享变量期间没有其他任何线程能够更新这些共享变量。 |
| 写锁 | 该写锁未被其他任何线程持有并且相应的读锁未被其他任何线程持有 | 对写线程和读线程都是排他的 | 使得写线程能够以独占的方式访问共享变量。 |
java.util.concurrent.locks.ReadWriteLock接口时对读写锁的抽象,其默认实现是java.util.concurrent.locks.ReentrantReadWriteLock。ReadWriteLock接口定义了两个方法:readLock()和writeLock(),分别用于返回相应读写锁实例的读写和写锁。这两个方法的返回值类型都是Lock,这并不是表示一个ReadWriteLock接口实例对应两个锁,而是代表一个ReadWriteLock接口实例可以充当两个角色。
读写锁的使用方法
public class ReadWriteLockUsage { private final ReadWriteLock readWriteLock = new ReentrantReadWriteLock(); private final Lock readLock = readWriteLock.readLock(); private final Lock writeLock = readWriteLock.writeLock(); // 读线程执行该方法 public void reader() { // 申请读锁 readLock.lock(); try { // 在此区域读取共享变量 } finally { // 总是在finally块中释放锁,以免锁泄漏 readLock.unlock(); } } // 写线程执行该方法 public void writer() { // 申请写锁 writeLock.lock(); try { // 在此区域访问(读、写)共享变量 } finally { // 总是在finally块中释放锁,以免锁泄漏 writeLock.unlock(); } } }
与普通的排他锁(如内部锁和ReentrantLock)相比,读写锁在排他性方面比较弱(这是我们锁期望的)。在原子性、可见性和有序性保障方面,它所起到的作用与普通的排他锁是一致的。由于读写锁内部实现比内部锁和其他显示锁要复杂得多,因此读写锁适合于在以下条件同时满足的场景中使用,否则使用读写锁会得不尝失(开销)。
- 只读操作比写(更新)操作要频繁得多;
- 读线程持有锁的时间比较长(怎么理解?读锁持续时间短会更容易被切换成写锁,不能发挥读共享的优势?)。
2.读写锁的降级
ReentrantReadWriteLock所实现的读写锁是个可重入锁。ReentrantReadWriteLock支持锁的降级(Downgrade),即一个线程持有读写锁的写锁的情况下可以继续获得相应的读锁。
读写锁的降级示例
public class ReadWriteLockDowngrade { private final ReadWriteLock readWriteLock = new ReentrantReadWriteLock(); private final Lock readLock = readWriteLock.readLock(); private final Lock writeLock = readWriteLock.writeLock(); public void operationWithLockDowngrade() { boolean readLockAcquired = false; // 申请写锁 writeLock.lock(); try { // 读共享数据进行更新 // ... // 当前线程在持有写锁的情况下申请读锁readLock readLock.lock(); readLockAcquired = true; } finally { writeLock.unlock(); } if (readLockAcquired) { try { // 读取共享数据并据此执行其他操作 // ... } finally { readLock.unlock(); } } else { // ... } } }
锁的降级的反面是锁的升级(Upgrade),即一个线程在持有读写锁的读锁的情况下,申请相应的写锁。ReentrantReadWriteLock并不支持锁的升级。读线程如果要转而申请写锁,需要先释放读锁,然后申请相应的写锁。
五.锁的使用场景
锁是Java线程同步机制中功能最强大、适用范围最广泛,同时也是开销最大、可能导致的问题最多的同步机制。
多个线程共享一组共享数据的时候,如果其中有线程涉及如下操作,那么就可以考虑使用锁。
- check-then-act:读取共享变量并在此基础上决定其下一个操作是什么。(隐含的前提条件是有其他操作会修改共享数据,否则check-then-act无意义(不会变化))
- read-modify-write操作:读取共享数据并在此基础上更新数据。不过,某些想自增操作(“count++”)这种简单的read-modify-write操作,可以使用原子变量类来实现线程安全。
- 对多个共享数据进行更新:如果这些数据之间存在关联关系,那么为了保障操作的原子性,可以考虑使用锁。
简单来说,只要会对共享变量进行读-写操作,就可以考虑使用锁。
六.线程同步机制的底层助手:内存屏障
锁保障可见性的时候线程获取锁和释放锁分别会执行刷新处理器缓存和冲刷处理器缓存这两个动作,对于同一个锁所保护的共享数据而言,前一个动作保证了该锁的当前持有线程能够读取到前一个持有线程对这些数据所作的更新,后一个动作保证了该锁的持有线程对这些数据所做的更新对该锁的后续持有线程可见。
Java虚拟机底层实际上是借助内存屏障(Memory Barrier,也称Fence)来实现上述两个动作的。内存屏障是对一类仅针对内存读、写操作指令(Instruction)的跨处理器架构(比如x86、ARM)的比较底层的抽象。内存屏障是被插入到两个指令之间进行使用的,其作用是禁止编译器、处理器重排序从而保障有序性。它在指令序列中就像一堵墙一样使其两侧(之前和之后)的指令无法“穿越”它(一旦穿越了了就是重排序了)。
在内存屏障实现禁止重排序的功能的同时也有刷新处理器缓存和冲刷处理器缓存的功能,从而保证可见性。
由于内部锁的申请与释放对应的Java虚拟机字节码指令分别是monitorenter和monitorexit,因此习惯上用MonitorEnter表示锁的申请,用MonitorExit表示锁的释放。
读操作和写操作没有特别说明时,都是指对主内存(即DRAM)进行的读、写操作。具体的,读操作(Load或Read)指将主内存中的数据(通过)高速缓存读取到寄存器中。写操作(Store或Write)指将寄存器中的数据写到主内存中。
按照内存屏障所起的作用来划分,将内存屏障划分为以下几种。
- 按照可见性保障来划分,内存屏障可以分为加载屏障(Load Barrier)和存储屏障(Store Barrier)。加载屏障的作用是刷新处理器缓存,存储屏障的作用是冲刷处理器缓存。Java虚拟机会在MonitroExit(释放锁)对应的机器码指令后插入一个存储屏障,这就保障了写线程在释放锁之前在临界区中对共享变量所做的更新对读线程的执行器来说是可同步的;Java虚拟机在MonitorEnter(申请锁)对应的①机器码指令之后②临界区开始之前的地方插入一个加载屏障,这使得读线程的执行器能够将写线程对相应共享变量所做的更新从其他处理器同步到该处理器的高速缓存中。因此,可见性的保障是通过写线程和读线程成对地使用存储屏障和加载屏障实现的。
- 按照有序性保障来划分,内存屏障可以分为获取屏障(Acquire Barrier)和释放屏障(Release Barrier)。获取屏障的使用方式是在一个读操作(指令,对主内存的读操作)之后插入该内存屏障,其作用是禁止该读操作与其后的任何读写操作之间进行重排序,这相当于在进行读操作的后续操作之前先要获取相应共享数据的所有权。释放屏障的使用方式是在一个写操作(指令,对主内存的写操作)之前插入该内存屏障,其作用是禁止该写操作与其前面的任何读写操作之间进行重排序。这相当于在对相应共享数据操作结束后释放所有权。

图6-1 获取屏障和释放屏障的位置
Java虚拟机会在①MonitorEnter(它包含了读操作)对应的机器码指令之后②临界区开始之前的地方插入一个存储屏障,并在①临界区结束之后②MonitorExit(它包含了写操作)对应的机器码之前的地方插入一个释放屏障。

图6-2 内存屏障在锁中的使用
由于获取屏障禁止了临界区中的任何读、写操作被重排序到临界区之前的可能性,而释放屏障又禁止了临界区中的任何读、写操作被重排序到临界区之后的可能性,因此临界区内的任何读、写操作都无法被重排序到临界区之外。在锁的排他性的共同作用下,这使得临界区中执行的操作序列具有原子性。因此,写线程在临界区中对各个变量你所作的更新会同时对读线程可见,即在读线程看来各个共享变量就像是“一下子”被更新的,于是这些线程无从(也无必要)区分这些共享变量是以何种顺序被更新的。这使得写线程在临界区中执行的操作自然而然的具有有序性——读线程对这些操作的感知顺序与源代码的顺序一致。
可见,锁对有序性的保障是通过写线程和读线程配对使用释放屏障与加载屏障实现的。
七.轻量级同步机制:volatile关键字
volatile意为“不稳定”。volatile关键字用于修饰共享可变变量,即没有使用final关键字修饰的实例变量或者静态变量,如
private volatile int logLevel;
volatile关键字表示被修饰的变量的值容易变化(即被其他线程更改),因而不稳定。volatile变量的不稳定性意味着对volatile关键字修饰的变量的读和写操作都必须从高速缓存或者主内存(也是通过高速缓存读取)中读取,以读取变量的相对新值。因此,volatile变量不会被编译器分配到寄存器进行存储,对volatile变量的读写操作都是内存访问(访问高速缓存相当于主内存)操作。
这是否意味着volatile关键字不需要进行冲刷处理器缓存(寄存器->高速缓存)和刷新处理器缓存(高速缓存->寄存器)的操作?
但因为不同的处理器有各自的高速缓存,所以仍然需要进行冲刷、刷新处理器缓存进行缓存同步?
volatile关键字常被称为轻量级锁,其作用与锁有相同的地方:保证可见性和有序性。不同的是,在原子性方面它仅能保障写volatile变量操作的原子性,但没有锁的排他性;其次,volatile关键字的使用不会引起上下文切换(这是volatile被冠以“轻量级”的原因)。因此,volatile更像是一个轻量级简易(功能比锁有限)锁。
7-1 volatile的作用
volatile关键字的作用包括:保障可见性、保障有序性和保障long/double型变量读写操作的原子性。
volatile仅仅保障对其修饰的变量的写操作(以及读操作)本身的原子性,而这并不表示对volatile变量的赋值操作一定具有原子性。例如,如下对volatile变量count1的赋值操作并不是原子操作:
count1 = count2 + 1; // count1和count2都是共享变量
该赋值操作实际上是一个read-moidfy-write操作。在其执行过程中其他线程可能已经更行了count2的值,因此该操作不具备不可分割性,也就不是原子操作。如果count2是一个局部变量,那么该赋值操作就是一个原子操作。
一般而言,对volatile变量的赋值操作,其右边表达式中只要涉及共享变量(包括被赋值的volatile变量本身),那么这个赋值操作就不是原子操作。要保障这样操作的原子性,仍然需要借助锁。
对于这样一个操作:
volatile Map map = new HashMap();
可以分解为如下伪代码所示的几个操作:
objRef = allocate(HashMap.class); // 子操作①:分配对象所需存储空间 invokeConstructor(objRef); // 子操作②:初始化objRef引用的对象 map = objRef; // 子操作③:将对象引用写入变量map
虽然volatile关键字仅保障其中的子操作③是一个原子操作,但是由于子操作①和子操作②仅涉及局部变量而未涉及共享变量,因此对变量map的赋值操作仍然是一个原子操作。
volatile变量的写操作
volatile变量的写操作相当于释放锁。
对于volatile变量的写操作,Java虚拟机会在该操作之前插入一个释放屏障,并在该操作之后插入一个存储屏障。
把对volatile变量的写操作理解为写指令。

图7-1-1 volatile变量写操作与内存屏障
其中,释放屏障禁止了volatile写操作与该操作之前的任何读、写操作进行重排序,从而保证了volatile写操作之前的任何读、写操作会先于volatile写操作被提交,即其他线程看到写线程对volatile变量的更新时,写线程在更新volatile变量之前所执行的内存操作的结果对于读线程必然也是可见的。这就保障了读线程读写线程在更新volatile变量前对共享变量(sharedA, sharedB)所执行的更新操作的感知顺序与相应的源代码顺序一致,即保障了有序性。
这个有序性保障的似乎只是volatile写操作和其之前整个操作的有序性,即读取到volatileVar为true时,能保证shareA=1和shareB="OK"(其他线程未修改的情况下)。但不能保证读到shareB="OK"时shareA=1。
volatile虽然能够保障有序性,但是它不像锁那样具备排他性,所以并不能保障其他操作的原子性,而只能够保障对被修饰便变量的写操作的原子性。因此,volatile变量写操作之前的操作如果涉及到共享可变变量,那么竞态仍可能产生。这是因为共享变量被赋值给volatile变量的时候,其他线程可能已经更新了该共享变量的值。
存储屏障具有冲刷处理器缓存的作用,因此,在volatile变量写操作之后插入一个存储屏障就使得该存储屏障前所有操作的结果(包括volatile变量写操作即该操作之前的任何操作)对其他处理器来说是可同步的。
volatile变量的读操作
volatile变量的读操作相当于获取锁。
对于volatile变量的读操作,Java虚拟机会在该操作之前插入一个加载屏障(Load Barrier),并在该操作之后插入一个获取屏障(Acquire Barrier),如图7-1-2所示。
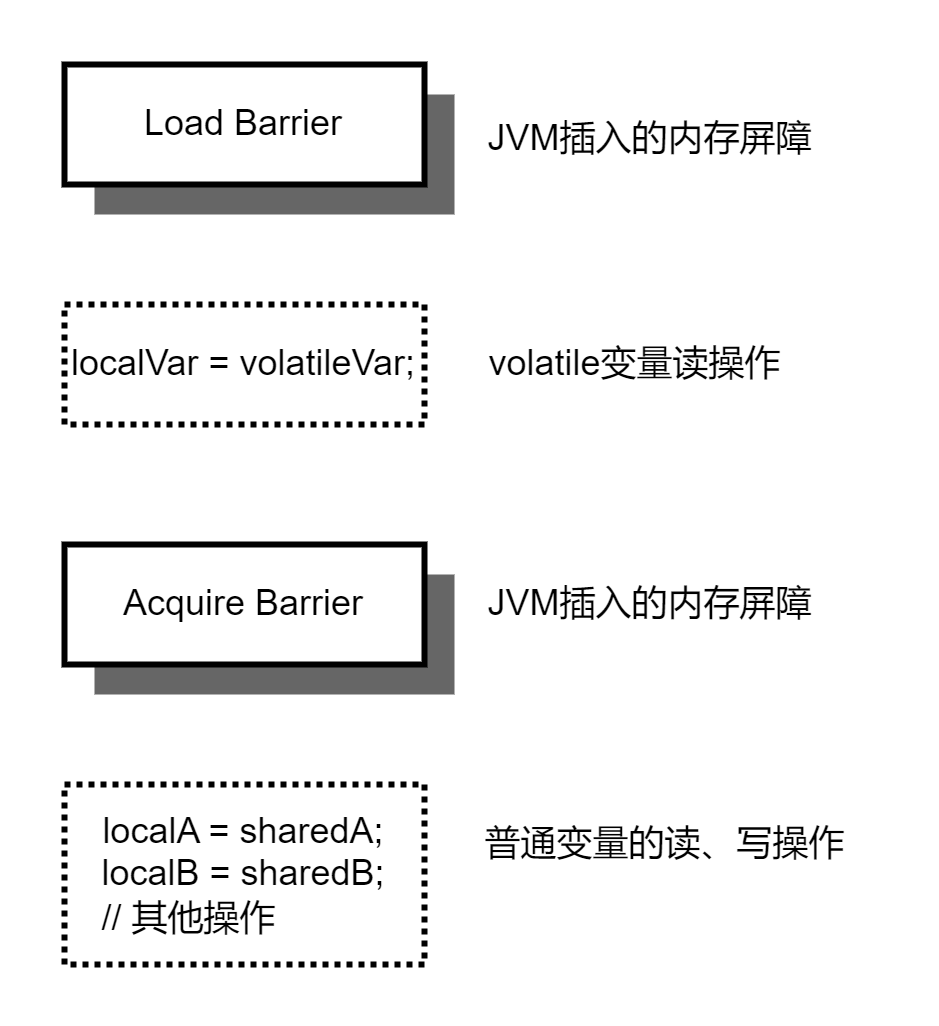
图7-1-2 volatile变量读操作与内存屏障
其中,加载屏障通过冲刷处理器缓存,使其执行线程(读线程)所在的处理器将其他处理器对共享变量(可能是多个变量)所做的更新同步到该处理器的高速缓存中。
保障可见性
读线程执行的加载屏障和写线程执行的存储屏障配合在一起使得写线程①对volatile变量的写操作②以及在此之前所执行的其他内存操作的结果对读线程可见,即保障了可见性。因此volatile不仅仅保障了volatile变量本身的可见性,还保障了写线程在更新volatile变量之前执行的所有操作结果对读线程可见。这种可见性保障类似于锁对可见性的保障,与锁不同的是volatile不具备排他性,因而它不能保障读线程读取到的这些共享变量的值是最新值。
另外,volatile关键字也可以看作给JIT编译器的一个提示,它相当于告诉JIT编译器相应变量的值可能会被其他处理器更改,从而使JIT编译器不会对相应代码做出一些优化(如循环不变表达式外提)而导致可见性问题。
保障有序性
volatile在有序性保障方面也可以从禁止排序的角度理解,即volatile禁止了如下重排序:
- 读volatile变量与该操作之后的任何读、写操作不会被重排序;
- 写volatile变量与该操作之前的任何读、写操作不会被重排序。
7-3 volatile的典型应用场景
volatile除了用于保障long/double性变量的读、写操作的原子性,其典型的应用场景还包括以下几个方面:
- 场景一 使用volatile关键字作为状态标志。使用volatile变量作为同步机制的好处使一个线程能够“通知”另一个线程某种事件的发生,而这些线程又无须因此而使用锁,从而避免了锁的开销以及相关问题。
- 场景二 使用volatile保障可见性。多个线程共享一个可变状态变量,其中一个线程更新了该变量之后,其他线程在无须加锁的情况下也能看到该更新。
- 场景三 使用volatile变量代替锁。volatile关键字并非锁的替代品,但是在一定的条件下它比锁更适合(性能开销小、代码简单)。多个线程共享一组可变状态变量的时候,通常需要使用锁来保障对这些变量的更新操作的原子性,以避免产生数据不一致的问题。利用volatile变量写操作具有的原子性,可以报这一组可变状态变量封装成一个对象,那么对这些状态变量的更新操作就可以通过创建一个新的对象并将该对象引用赋值给相应的引用型变量来实现。在这个过程中,volatile保障了原子性和可见性(有序性同样也保证了,读取到封装在对象里一个变量的更新值时,对象里其他变量的值也是更新值),从而避免了锁的使用。例如,之前修改主机IP和端口的例子。
- 场景四 使用volatile实现简易版读写锁。读写锁是通过混合使用锁和volatile关键字而实现的,其中锁用于保障共享变量写操作的原子性,volatile变量用于保障共享变量的可见性。因此,与ReentrantReadWriteLock所实现的读写锁不同的是,这种简易版读写锁①仅涉及一个共性变量并且②允许一个线程读取这个共享变量的时候其他线程可以更新该变量(这是因为读线程没有加锁)。因此,这种读写锁允许写线程可以读取到共享变量的非最新值。该场景一个典型的例子是实现一个计数器。
public class Counter { private volatile long count; public long value() { return count; } public void increment() { synchronized (this) { count ++; } } }
八.实践:正确实现看似简单的单例模式
单例模式所要实现的目标为:保持一个类有且仅有一个实例。出于性能的考虑,不少单例模式的实现会采用延迟加载(Lazy Loading)的方式,即仅在需要用到相应实例的时候才创建实例。
严格来说,所谓“一个类有且仅有一个实例”隐含着一个前提——这个类是一个Java虚拟机实例(进程)中一个Class Loader所加载的类。Java虚拟机的Class Loader机制:同一个类可以被多个Class Loader加载,这些Class Loader各自创建这个类的实例(Class本身也是一个对象)。因此,如果有多个Class Loader加载同一个类,那么所谓“单例”就无法满足——这些Class Loader都创建该类的唯一一个实例,实际上被创建的实例数就等于加载这个类的Class Loader的数量。
8-1 基于双检查锁的正确单例模式实现
public class DCLSingleton { /* * 保存该类的唯一实例,使用volatile关键字修饰instance */ private static volatile DCLSingleton instance; /* * 私有构造器使其他类无法直接通过new创建该类实例 */ private DCLSingleton() { } /** * 创建并返回该类的唯一实例 * 即只有该方法被调用时,该类的唯一实例才会被创建 */ public static DCLSingleton getInstance() { if (null == instance) { // 操作①:第1次检查 synchronized (DCLSingleton.class) { if (null == instance) { // 操作②:第2次检查 instance = new DCLSingleton(); // 操作③ } } } // 读的时候并没有加锁 return instance; } public void someService() { // 省略其他代码 } }
操作③可以分解为如下伪代码所示的几个独立的子操作:
objRef = allocate(DCLSingleton.class); // 子操作①:分配对象所需空间 invokeConstructor(objRef); // 子操作②:初始化objRef引用的对象 instance = objRef; // 子操作③:将对象引用写入共享变量
JIT编译器可能将上述的子操作重排序为子操作①->子操作③->子操作②,即在初始化对象之前将对象的引用写入共享变量instance。由于锁对有序性的保障是有条件的(读或写共享数据都需要获取共享数据上的锁),而操作①读取instance变量的时候并没有加锁,因此上述重排序对操作①的执行线程是有影响的:操作①的执行线程可能看到一个未初始化(或者未初始化完毕)的实例(instance),即变量instance的值不为null,但是该变量所引用的对象中的某些实例变量值可能仍然是默认值,而不是构造器中设置的初始值。
解决方法
只需要将instance变量用volatile修饰即可。这利用了volatile关键字以下两个作用:
- 保障可见性:一个线程通过执行操作③修改了instance变量的值,其他线程可以读取到相应的值(通过执行操作①)。
- 保障有序性:由于volatile能够禁止volatile变量写操作(子操作③)与该操作之前的任何读、写操作进行重排序,因此,volatile修饰instance相当于禁止JIT编译器以及处理器将子操作②(对对象进行初始化的写操作)重排序到子操作③(将对象引用吸入共享变量的写操作),着保障了一个线程读取到instance变量所引用的实例时,该实例已经初始化完毕。
通过volatile关键字对上述两点的保障,双重检查锁所要实现的效果才得以正确实现。
8-2 基于静态内部类的单例模式实现
考虑到双重检查锁实现上容易出错,可以采用另一种同样可以实现延迟加载的效果且比较简单的一种方法。
public class StaticHolderSingleton { // 私有构造器 private StaticHolderSingleton() { } private static class InstanceHolder { // 保存外部类的唯一实例 static final StaticHolderSingleton INSTANCE = new StaticHolderSingleton(); } public static StaticHolderSingleton getInstance() { return InstanceHolder.INSTANCE; } public void someService() { // 省略其他代码 } }
类的静态变量被初次访问会触发Java虚拟机对该类进行初始化,即该类的静态变量的值会变为其初始值而不是默认值。因此,静态方法getInstance()被调用InstanceHolder.INSTANCE被访问的时候Java虚拟机会初始化内部静态类InstanceHolder。这使得InstanceHolder的静态变量INSTANCE被初始化,从而使StaticHolderSingleton类的唯一实例得以创建。由于类的静态变量只会创建一次,因此StaticHolderSingleton(单例类)只会被创建一次。
8-3 基于枚举类型的单例模式实现
public enum Singleton { INSTANCE; // 私有构造器,默认是private Singleton() { } public void someService() { // 省略其他代码 } }
单例类的INSTANCE字段相当于该类的唯一一个实例。这个实例是在Singleton.INSTANCE初次被引用的时候才会被初始化。仅访问Singleton本身并不会导致Singleton的唯一实例被初始化。
九.CAS与原子变量
CAS(Compare and Swap)是对一种处理器指令(例如x86处理器中的cmpxchg指令)的称呼。不少多线程相关的Java标准库类的实现最终都会借助CAS。在实际工作中不需要直接使用CAS。
9-1 CAS
count++(count是共享变量)实际上是一个read-modify-write操作,它可以由CAS转换为一种一般性的if-then-act的操作,并由处理器保障该操作的原子性。这里,CAS相当于一个代理人(中间人),共享同一个变量V的多个线程就是它的客户。当客户需要更新变量V的值的时候,他们只需要请求(即调用)代理人代为修改,为此,客户要告诉代理人①其看到的共享便变量的当前值A及②期望的新值B。CAS作为代理人,相当于如下伪代码所示的函数:
boolean compareAndSwap(Variable V, Object A, Object B) { if ( A == V.get()) { // check: 检查变量值是否被其他线程修改过 V.set(B); // act:更新变量值 return true; // 更新成功 } return false; // 变量值已被其他线程修改,更新失败 }
CAS是一个原子的if-then-act的操作,其背后的假设是:当一个客户(线程)执行CAS操作的时候,如果变量V的当前值和客户请求CAS所提供的变量值A(即变量的旧值)是相等的,那么就说明其他线程并没有修改过变量V的值(但可能也是改了后又改回去了)。执行CAS时如果没有其他线程修改过变量V的值,那么下手最快的客户(当前线程)就会抢先将变量V的值更新为B(新值),而其他客户(线程)的更新请求则会失败。这些失败的客户(线程)通常可以选择再次尝试,直到成功。
使用CAS实现线程安全的计数器
public calss CASBasedCounter { private volatile long count; public long value() { return count; } public void increment() { long oldValue; long newValue; do { oldValue = count; // 读取共享变量的值 newValue = oldValue + 1; // 计算共享变量的新值 } while(/* 调用CAS来更新共享变量的值 */ !compareAndSwap(oldValue, newValue)); } /* * 该方法是一个实例方法,因为共享变量count是当前类的实例变量, * 所以封装了一层使不同每次在调用方法时都传入共享变量参数 */ private boolean compareAndSwap(long oldValue, long newValue){ // ... } }
上述increment方法中的do-while循环用于更新共享变量失败的时候继续重试,直到更新成功。这也是许多基于CAS的算法的代码模板(伪代码):
do { oldValue = V.get(); // 读取共享变量V的旧值 newValue = calculate(oldValue); // 通过旧值计算新值 } while( /* 调用CAS */ !compareAndSwap(V, oldValue, newValue));
即在循环体中读取共享变量V的旧值(当前值)A,并以该值为输入经过一系列操作计算共享变量的新值B,接着调用CAS试图将V的值更新为B。若更新失败(说明更新期间其他线程修改了共享变量V的值,导致共享变量V的当前值和读到的旧值A不同)则继续重试,直到成功。
CAS只是保障了共享变量更新这个操作的原子性,它并不保障可见性。因此,仍然需要使用volatile修饰共享变量count。
9-2 原子操作工具:原子变量类
原子变量类(atomics)是基于CAS实现的能够保障对共享变量进行read-modify-write更新操作的原子性和可见性的一组工具类。这里所谓的read-modify-write更新操作,是指对共享变量的更新不是一个简单的赋值操作,而是变量的新值依赖变量的旧值,例如自增操作“count++”。由于volatile无法保障自增操作的原子性,而原子变量类的内部通常借助一个volatile变量并保障对该变量的read-modify-write更新操作的原子性,因此它可以被看作增强型的volatile变量。
原子变量类一共有12个,可以被分为4组:
| 分组 | 类 |
| 基础数据型 | AtomicInteger, AtomicLong, AtomicBoolean |
| 数组型 | AtomicIntegerArray, AtomicLongArray, AtomicReferenceArray |
| 字段更新器 | AtomicIntegerFiledUpdater, AtomicLongFieldUpdater, AtomicReferenceFieldUpdater |
| 引用型 | AtomicReference, AtomicStampedReference, AtomicMarkableReference |
AtomicLong
AtomicLong类继承自Number类,其内部维护了一个long型volatile变量。AtomicLong可以看作一个增强型对的volatile long变量:自增、自减操作都具有原子性。
| 方法声明 | 功能 | 备注 |
| public final long get() | 获取档期实例的当前数值 | 相当于直接读一个volatile变量,因此该方法并不保障读线程读到的数值是最新值 |
| public final long getAndIncrement() | 使当前实例的数值以原子操作的方式自增1,返回自增前的数值 | 这些方法实现的操作都是原子操作,客户端代码无须在调用这些方法时加锁。 |
| public final long getAndDecrement() | 使当前实例的数值以原子操作的方式自减1,返回自减前的数值 | |
| public final long incrementAndGet() | 使当前实例的数字以原子操作的方式自增1,返回自增后的数值 | |
| public final long decrementAndGet() | 使当前实例的数字以原子操作的方式自减1,返回自减后的数值 | |
| public final void set(long newValue) | 设置当前实例的数值为指定值 |
// 声明时指定初始值 private final AtomicLong requestCount = new AtomicLong(0); // 请求总数加1,无需加锁 requestCount.incrementAndGet(); // 获取请求总数,直接读内部维护的volatile变量,获取当前值 requestCount.get(); // 重置请求总数,无需加锁 requestCount.set(0);
AtomicBoolean
AtomicBoolean类乍一看似乎显得有些多余,因为对布尔类型变量的写操作本身就是一个原子操作。实际上,这里需要注意更新操作并不一定是简单地进行赋值。AtomicBoolean用于实现read-modify-write操作的原子性。
public enum AlarmMgr implements Runnable { // 保存该类的唯一实例 INSTANCE; private final AtomicBoolean initializing = new AtomicBoolean(false); AlarmMgr() { // 什么也不做 } public void init() { // 使用AtomicBoolean的CAS操作确保工作者线程只会被创建(并启动)一次 if (initializing.compareAndSet(false, true)) { // 创建并启动工作者线程 new Thread(this).start(); } } @Override public void run() { // ... } }
AtomicBoolean变量initializing用于表示告警管理器初始化(即创建并启动告警上报线程)的状态。initializing内部值为true表示正在初始化(或者已经初始化完毕),false表示未开始初始化。AalrmMgr.init()在创建(并启动)告警上报线程前会检查initializing的内部值:若initializing内部值为false,则将其置为true以表示当前线程即将执行初始化;若initializing内部值为true,则当前线程直接从AlarmMgr.init()返回。显然,在多线程环境下这个将initializing内部值从false调整为true的过程是一个check-then-act操作,若用锁来保障该操作的原子性,那么AlarmMgr.init()看起来会像这样:
public void init() { synchronized (this) { // 这里initializing可以不用volatile修饰,锁会保障可见性 if (initializing) { return; } initializing = true; } // 创建并启动工作者线程 new Thread(this).start(); }
而实际上,可以使用AtomicBoolean的compareAndSwap方法(相当于CAS)来保障上述check-then-act操作的原子性,从而既避免了所得开销,又使代码更加简单。
前面CAS实现原子操作背后的一个假设是:共享变量的当前值与当前线程所提供的旧值相同,就认为这个变量没有被其他线程修改过。实际上,这个假设不一定总是成立的。例如,对于共享变量V,当前线程看到它的值为A的那一刻(旧值为A),其他线程已经将其值更新为B,接着在当前线程执行CAS的时候该变量的值又被其他线程更新为A(共享变量的当前值为A),此时共享变量的当前值与当前线程所提供的旧值相同,但共享变量已经被其他线程修改过了。这就是ABA问题,即共享变量经历了A->B->A的更新。ABA问题是否可以接受或者可以容忍与要实现的算法有关。如果要规避ABA问题,可以为共享变量的更新引入一个修订号(也称时间戳)。每次更新共享变量时相应的修订号的值就会被增加1。也就是说,将共享变量V的值“扩展”成一个又变量实际值和相应修订号所组成的元组([共享变量值,修订号])。于是,对于初始实际值为A的共享变量V,它可能经历这样的变量更新:[A,0]->[B,1]->[C,2]。AtomicStampedReference类就是基于这种思想而产生的。
十.对象的发布与逸出
线程安全问题产生的前提条件是多个线程共享变量。
多个线程共享变量的途径被统称为对象发布(Publish)。
常见的发布形式包括:
- 通过public方法共享private变量。
- 将对象的引用存储到public变量中。例如:public Map<String, Integer> registry = new HashMap<>();
- 在非private方法中返回一个对象。
- 创建内部类,使得当前对象(this)能够被这个内部类使用。
10-1 对象初始化安全:重访final与static
1.static
static关键字在多线程环境下有其特殊的含义,它能够保证一个线程即使在未使用其他同步机制的情况下也总是可以读取到一个类的静态变量的初始值(而不是默认值)。但是,这种可见性保障仅限于线程初次读取改变量。如果这个静态变量在相应类初始化完毕之后被其他线程更新过,那么一个线程要读取该变量的相对新值仍然需要借助锁、volatile关键字等同步机制。
对于引用型静态变量,static关键字还能够保障一个线程读取到该变量的初始值时,这个值所指向(引用)的对象已经初始化完毕。
- static变量初始值(包括这个值所指向(引用)对象)的可见性,是由Java类初始化机制保证的。即初次访问该类的任意一个静态变量才使这个类被初始化——①类的静态初始化块(“static{}”)被执行,②类的所有静态变量被赋予初始值。
- 类初始化的详情可参考https://www.cnblogs.com/certainTao/p/14614203.html
2.final
由于指令重排序的作用(2.多线程编程的目标与挑战 6-2 指令重排序),一个线程读取到一个对象引用时,该对象可能尚未初始化完毕,即这些线程可能读取到该对象字段的默认值而不是初始值(通过构造器或者初始化语句指定的值)。在多线程环境下,final关键字有其特殊的作用:
当一个对象被发布到其他线程的时候,该对象所有final字段(实例变量)都是初始化完毕的,即其他线程读取这些字段的时候所读取到的值都是相应字段的初始值(而不是默认值)。而非final字段没有这种保障,即这些线程读取该对象的非final字段时所读取到的值可能仍然是相应字段的默认值。对于final字段,final关键字还进一步确保该字段所引用的对象已经初始化完毕,即这些线程读取该字段所引用的对象已经初始化完毕,读取到的字段值都是相应的初始值。
那么对于[2.多线程编程的目标与挑战 -> 6-2 指令重排序 -> JIT编译器指令重排序Demo]中的Helper类来说,如果所有字段都由final关键字修饰一下,那么sum的结果应该就只会有-1和4。
static class Helper { final int payloadA; final int payloadB; final int payloadC; final int payloadD; public Helper(int externalData) { this.payloadA = externalData; this.payloadB = externalData; this.payloadC = externalData; this.payloadD = externalData; } }
进一步,对于对象的引用型final字段,Java语言规范还会保障其他线程看到包含该字段的对象时,这个字段所引用的对象必然是初始化完毕的(所有字段都被初始化了)。
final关键字只能保障有序性,即保障一个对象(引用)对外可见的时候该对象的final字段必然是初始化完毕的。但final关键字并不保障对象引用本身对外的可见性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号