Python垃圾回收机制
Garbage collection(GC)
1. 引用计数机制
原理:当一个对象的引用被创建或者复制时,对象的引用计数加1;当一个对象的引用被销毁时,对象的引用计数减1,当对象的引用计数减少为0时,就意味着对象已经再没有被使用了,可以将其内存释放掉。
优点:引用计数有一个很大的优点,即实时性,任何内存,一旦没有指向它的引用,就会被立即回收,而其他的垃圾收集技术必须在某种特殊条件下才能进行无效内存的回收。
缺点:但是它也有弱点,引用计数机制所带来的维护引用计数的额外操作与Python运行中所进行的内存分配和释放,引用赋值的次数是成正比的,这显然比其它那些垃圾收集技术所带来的额外操作只是与待回收的内存数量有关的效率要低。同时,引用技术还存在另外一个很大的问题-循环引用,因为对象之间相互引用,每个对象的引用都不会为0,所以这些对象所占用的内存始终都不会被释放掉。如下:
A和B相互引用而再没有外部引用A与B中的任何一个,它们的引用计数虽然都为1,但显然应该被回收
a = { } #对象A的引用计数为 1
b = { } #对象B的引用计数为 1
a['b'] = b #B的引用计数增1
b['a'] = a #A的引用计数增1
del a #A的引用减 1,最后A对象的引用为 1
del b #B的引用减 1, 最后B对象的引用为 1
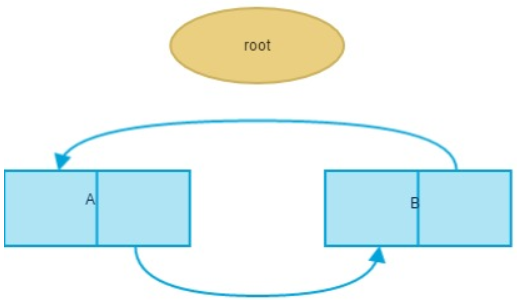
要解决这个问题,Python引入了其他的垃圾收集机制来弥补引用计数的缺陷:“标记-清除”,“分代回收”两种收集技术。
2. 标记-清除
标记清除(Mark—Sweep)算法是一种基于追踪回收(tracing GC)技术实现的垃圾回收算法。它分为两个阶段:
第一阶段是标记阶段,GC会把所有的『活动对象』打上标记;
第二阶段是把那些没有标记的对象『非活动对象』进行回收。那么GC又是如何判断哪些是活动对象哪些是非活动对象的呢?
对象之间通过引用(指针)连在一起,构成一个有向图,对象构成这个有向图的节点,而引用关系构成这个有向图的边。从根对象(root object)出发,沿着有向边遍历对象,可达的(reachable)对象标记为活动对象,不可达的对象就是要被清除的非活动对象。根对象就是全局变量、调用栈、寄存器。
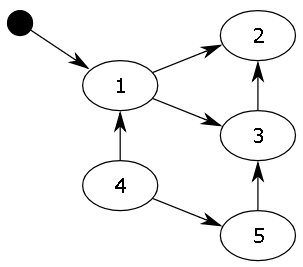
在上图中,我们把小黑圈视为全局变量,也就是把它作为root object,从小黑圈出发,对象1可直达,那么它将被标记,对象2、3可间接到达也会被标记,而4和5不可达,那么1、2、3就是活动对象,4和5是非活动对象会被GC回收。
标记清除算法作为Python的辅助垃圾收集技术主要处理的是一些容器对象,比如list、dict、tuple,instance等,因为对于字符串、数值对象是不可能造成循环引用问题。Python使用一个双向链表将这些容器对象组织起来。不过,这种简单粗暴的标记清除算法也有明显的缺点:
缺点:清除非活动的对象前它必须顺序扫描整个堆内存,哪怕只剩下小部分活动对象也要扫描所有对象。
3. 分代收集
从前面“标记-清除”这样的垃圾收集机制来看,这种垃圾收集机制所带来的额外操作实际上与系统中总的内存块的数量是相关的,当需要回收的内存块越多时,垃圾检测带来的额外操作就越多,而垃圾回收带来的额外操作就越少;反之,当需回收的内存块越少时,垃圾检测就将比垃圾回收带来更少的额外操作。为了提高垃圾收集的效率,采用“空间换时间的策略”。
原理:将系统中的所有内存块根据其存活时间划分为不同的集合,每一个集合就成为一个“代”,垃圾收集的频率随着“代”的存活时间的增大而减小。也就是说,活得越长的对象,就越不可能是垃圾,就应该减少对它的垃圾收集频率。那么如何来衡量这个存活时间:通常是利用几次垃圾收集动作来衡量,如果一个对象经过的垃圾收集次数越多,可以得出:该对象存活时间就越长。同时,分代回收是建立在标记清除技术基础之上,分代回收同样作为Python的辅助垃圾收集技术处理那些容器对象。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号