python中的filter、map、reduce、apply用法总结
1. filter
功能: filter的功能是过滤掉序列中不符合函数条件的元素,当序列中要删减的元素可以用某些函数描述时,就应该想起filter函数。
调用: filter(function,sequence),function可以是匿名函数或者自定义函数,它会对后面的sequence序列的每个元素判定是否符合函数条件,返回TRUE或者FALSE,从而只留下TRUE的元素;sequence可以是列表、元组或者字符串
例子:
x = [1,2,3,4,5] print(list(filter(lambda x:x%2==0,x))) # 找出偶数。python3.*之后filter函数返回的不再是列表而是迭代器,所以需要用list转换。 # 输出: [2, 4]
2. map
功能: 求一个序列或者多个序列进行函数映射之后的值,就该想到map这个函数,它是python自带的函数,在python3.*之后返回的是迭代器,同filter,需要进行列表转换
调用: map(function,iterable1,iterable2),function中的参数值不一定是一个x,也可以是x和y,甚至多个;后面的iterable表示需要参与function运算中的参数值,有几个参数值就传入几个iterable
例子:
x = [1,2,3,4,5] y = [2,3,4,5,6] print(list(map(lambda x,y:(x*y)+2,x,y))) # 输出: [4, 8, 14, 22, 32]
3. reduce
功能: 对一个序列进行压缩运算,得到一个值。但是reduce在python2的时候是内置函数,到了python3移到了functools模块,所以使用之前需要 from functools import reduce
调用: reduce(function,iterable),其中function必须传入两个参数,iterable可以是列表或者元组
例子:
from functools import reduce arr = [2,3,4,5,6] reduce(lambda x,y: x + y,arr) # 直接返回一个值 20
其计算原理:
先计算头两个元素:f(2, 3),结果为5;
再把结果和第3个元素计算:f(5, 4),结果为9;
再把结果和第4个元素计算:f(9, 5),结果为14;
再把结果和第5个元素计算:f(14, 6),结果为20;
由于没有更多的元素了,计算结束,返回结果20。
from functools import reduce arr = [2,3,4,5,6] reduce(lambda x,y: x * y,arr) # 连乘
720
4. apply
功能: 是pandas中的函数,应用对象为pandas中的DataFrame或者Series。大致有两个方面的功能:一是直接对DataFrame或者Series应用函数,二是对pandas中的groupby之后的聚合对象apply函数
调用: apply(function,axis),function表明所使用的函数,axis表明对行或者列做运算
例子:
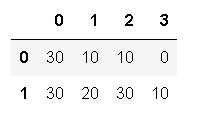
import numpy as np a = np.random.randint(low=0,high=4,size=(2,4)) data = pd.DataFrame(a) data.apply(lambda x:x*10) # 输出:
5. 总结
- filter和map都是python内置的函数,可以直接调用,reduce在functools模块,apply在pandas模块
- 要过滤删减序列用filter;要对多个序列做函数运算用map;在pandas里面直接调用apply,尤其是聚合对象,当然还有agg。reduce用得少

 浙公网安备 33010602011771号
浙公网安备 33010602011771号